Food Truck Architecture - It’s all about events
As you might have guessed if you’ve followed my postings about the Sleepy Hollow Architecture and the Terminus Architecture, I’m on a quest. I want to find a better way to fundamentally structure software for higher evolvability. Not as an end to itself, but because higher evolvability means higher longterm productivity – which seems a good thing at least if you want to make money with software not just today but also tomorrow.
Sure, there are quite a few architectural patterns out there already. So, why add more? Because in my experience over the course of decades in software development there’s still something missing. And that is: a fundamental re-orientation towards less functional dependencies and more guidance and higher flexibility.
The patterns from MVC to Clean Architecture have three things in common:
- they all rely on functional dependencies
- they all revolve around a domain model
- they all structure software in a technical way
Since I’ve seen enough software system based on those patterns and still being hard to change I came to think, maybe we should give architectural patterns another try.
With the Sleepy Hollow and Terminus Architectures I’m addressing the technical orientation of the traditional patterns:
- The Sleepy Hollow Architecture is putting the most important part of a software in the center: the body (which also is called the backend because it’s not directly interacting with any user). Software is neither about the frontend nor persistence or any other resource access. They are just details of the backend which at first should be viewed as a single thing.
- The Terminus Architecture then is structuring the backend into message handlers each focused on just one request from a user. That’s even more of a non-technical decomposition because it’s the messages that count when delivering software. Handling a message is a natural increment for Agile software development. Software gains value one handled message at a time.
So much for less technicalities in a software architecture. But what about the other two aspects? In this posting I’d like to tackle the domain model focus. Or maybe it should even be called the „domain model fallacy“?
One model to rule them all?
Generations of developers learned to go straight for the one central data structure to hold everything together in a software. Today it might be called the domain model. But you also can call it a business object model or - if it gets larger - the enterprise data model.
The idea behind this is that a software’s purpose is to modify a single data model representing whatever a user needs to deal with. Look at an SQL Server database with 350 closely related tables and you know what I mean. Add to them the 350 closely related classes to represent those tables in memory and I hope you start feeling uneasy. So many dependencies, such a huge claim of one-size-fits-all.
I used to be thinking along the same lines. I didn’t know how to manage and store application data in a different way. (I have to admit I even thought O/R mapping was a good idea… Well, I was young back then. I have to learn to forgive myself…)
But those days are gone. I’ve come to see such thinking, such models more as a hindrance than an enabler. They might seem obvious and natural – but actually they are not. At best they are premature optimizations.
The problem with these central and single comprehensive data structures is the widespread dependence on them. The larger the claim, the more encompassing the data models, the closer the relationship of all sorts of parts of an application on them. That’s the opposite of decoupling and evolvability.
The more central a part is, the more other parts depend on it, the more stable the central part needs to be. And that’s contrary to what customer require; they require flexibility.
MVC is suggesting there should be one (data) model; it’s right there in the acronym. Clean Architecture is putting the domain in the center which also suggests that there is a single domain model. And in DDD there is so much talk about Entities and Aggregates that it would be strange not to strive for a comprehensive domain data model.
Maybe I’m doing this or that pattern wrong here. Maybe their intention is different. I’d be glad to hear about that. Nevertheless the simple code reality in so many projects is like described. So, at least some massive misunderstandig must be at work.
But what can be done about it? How can the „one domain model fallacy“ be overcome?
Well, for one thing, following the Terminus Architecture there could be several domain models: one for each message handling slice of the backend.
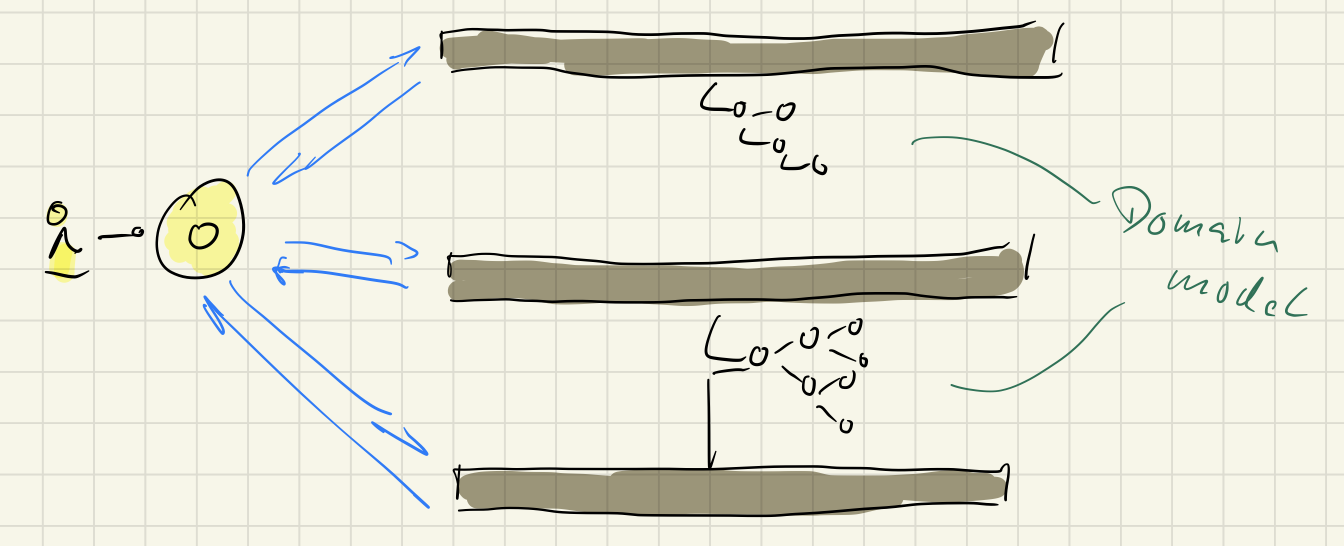
At least in principle there could be many such domain models. Because in reality the question immediately arising is: How to store all those domain models? In the same database? Or how to sync the domain models? Or rather share them? And wouldn’t that lead to one big domain model again?
I think a premise needs to be questioned. That’s the idea of storing in a static structure at all.
Event Sourcing to the rescue
To switch from one domain model to several requires a more fundamental change, I guess. We’ve to give up thinking in big schemas for single data models. Instead of putting static data at the center of our applications we should record its evolution change by change, or to be more precise: change event by change event.
If we want to get rid of the one domain model we need to create a stream of changes over time as the source for all the individual models fitting the changing needs of different parts of a software system.
Data models needed should be seen as projections of recorded events in an never ending stream. That’s called Event Sourcing.
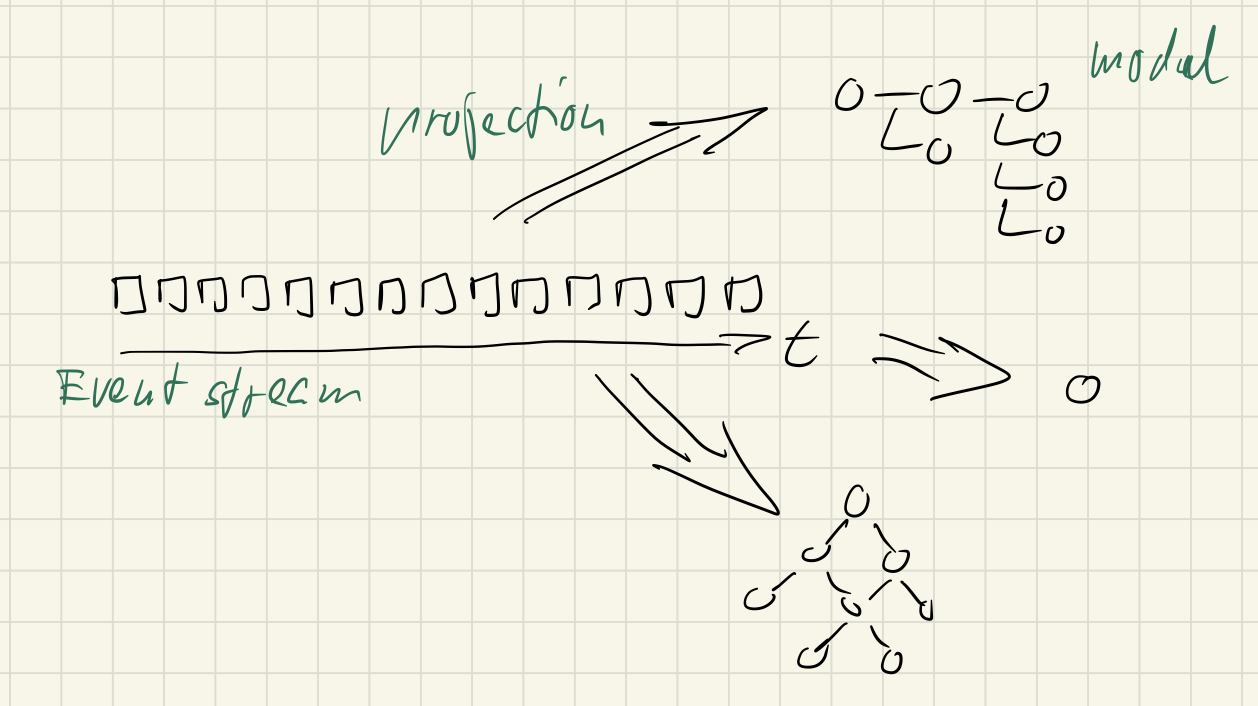
When requirements change for one part of an application just one projection has to be adapted. The impact is local by definition instead of global, because different parts depend only on local data models.
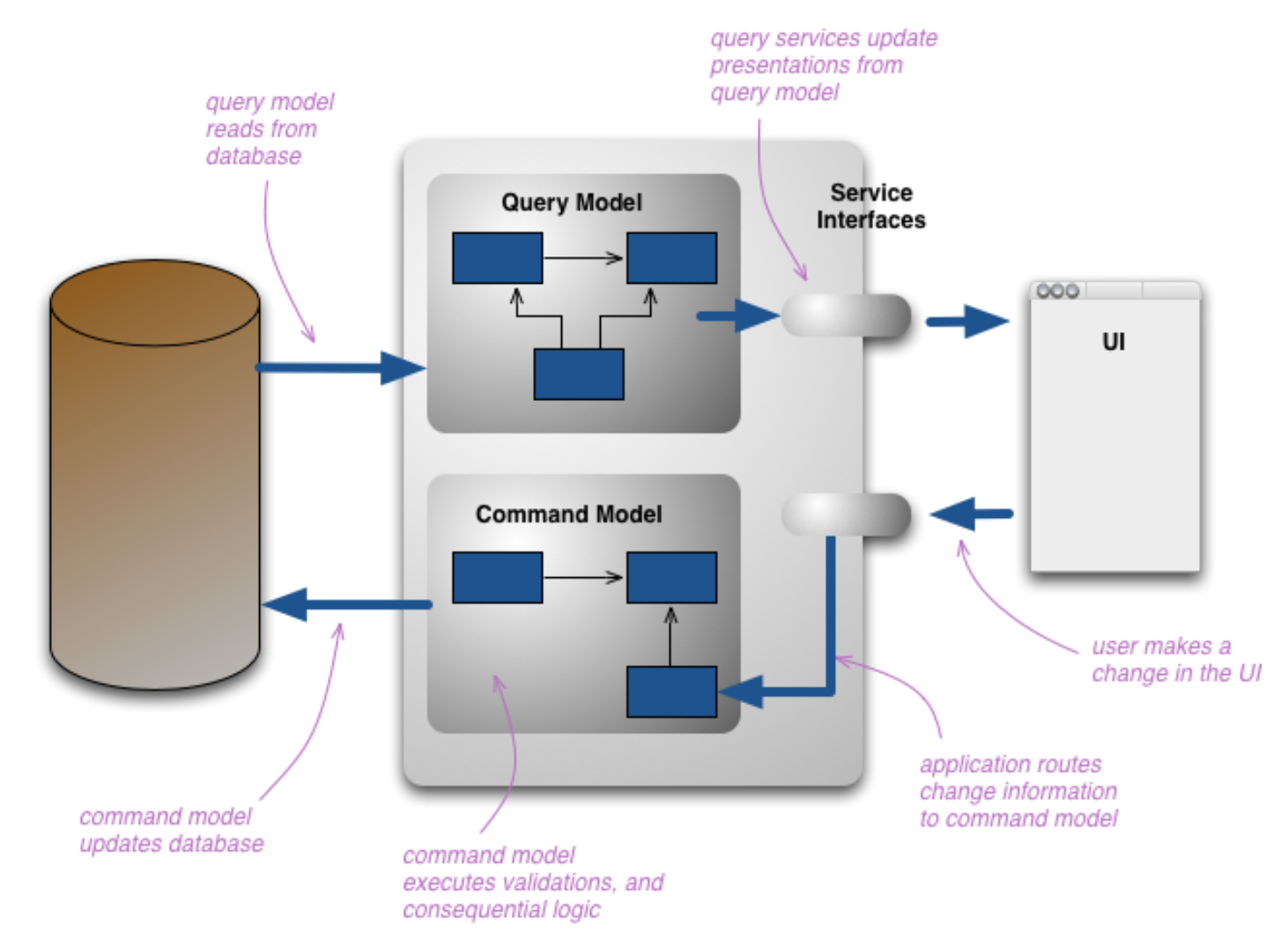
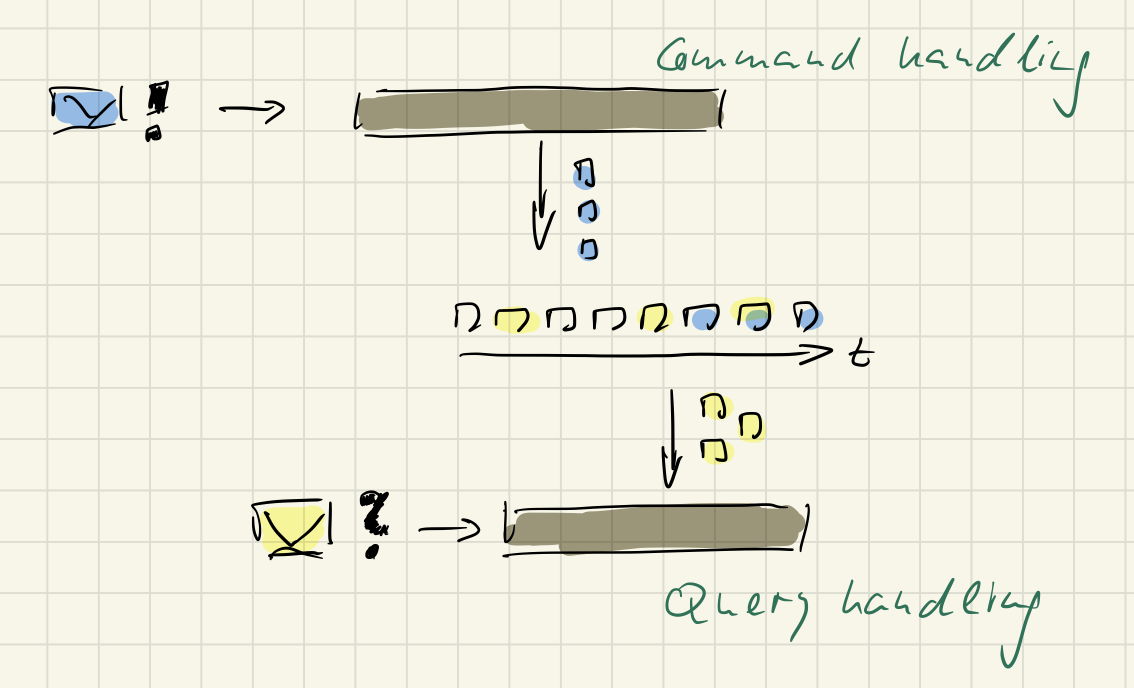
The CQRS pattern has recognized this by introducing a so called read model. That’s an individual data model to satisfy queries. See the right side of the following image by Pablo Castilla:
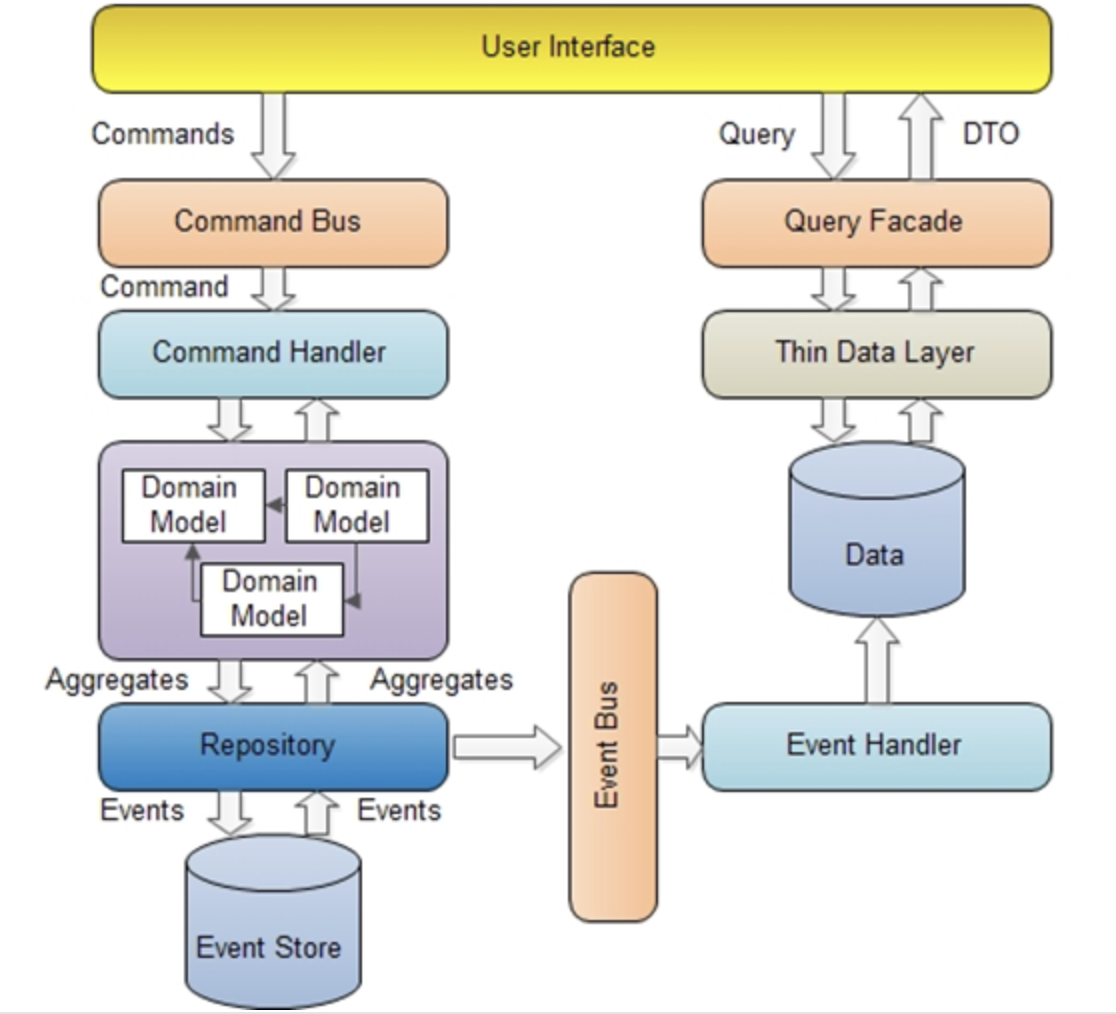
On the left there still is a domain model to support command handling. But queries just rely on read models stored in the „data“ drum.
That’s a step in the right direction, I think. Firstly the demands on data models for changing/writing and querying/reading are very different; this is acknowledge by dividing the „data model space“ into the left and right side. Secondly the one-size-fits-all thinking is given up by allowing any number of small and large read models to exist in parallel.
Event Sourcing and CQRS to me thus are a missing link in the traditional chain of architectural patterns. I believe it should be the default for any application. Yes, even for simple CRUD applications.
Most proponents of CQRS don’t view CRUD applications worthy of so much effort, it seems, though. To be honest, I don’t get why. Because if there’s one thing sure in software development then that’s constant change. In my experience today’s simple, local CRUD application is tomorrow’s enterprise wide tool growing every day. To be prepared for this surprise I’d say it’s prudent to default to CQRS and Event Sourcing.
Except… for my taste there is an inconsistency in this pattern.
Beyond CQRS: Event-Orientation
CQRS does not mandate Event Sourcing but benefits from it, I’d say. What I don’t understand, however, is why there is this distinction between a domain model on the left of the above image and read models on the right?
In Martin Fowler’s depiction it’s similar: a command model, and even a single query model.
He even blurs the distinction by saying:
The two models might not be separate object models, it could be that the same objects have different interfaces for their command side and their query side…
With that I very much disagree! The potential of Event Sourcing will not be fully tapped until the default is a share-nothing approach. All models are different, individual, local to a single message handler - until this proves to be cumbersome and some optimization seems worthwhile.
The evolutionary demands on software are so huge that I think the first and foremost requirement to fulfill is changeability, malleability. Flexibility first – that’s what Event Sourcing is about to me.
There was a slogan in the 1980s when user interfaces moved into the graphical realm: „Don’t mode me in!“ I even remember t-shirts with this printed on. It was a rallying cry to build different user interface, user interfaces with more flexibility for users.
Today I’m tempted to change this slogan into „Don’t model me in!“ Don’t create just one or few models to try serving very different and changing needs in a software.
In my view – and that of Sia Ghassemi who I’ve talked with a lot about this over asian lunches – the shift needs to be more fundamental than with CQRS. What’s needed is full Event-Orientation (EO). To Sia and me that means two things:
1. All messages are created equal
Why should there be just two sides to an application: a command handling side and a query handling side? Sure, this is already some kind of slicing (incremental architecture). But why stop there?
Why not treat each and every incoming message the same, i.e. with its own message handler? That’s what the Terminus Architecture is about.
And then: Why distinguish between commands and queries at all? Sure, there is a fundamental difference and I think it’s important – but not in a way to set up message handlers differently. In both images above the command handling and query handling sides are looking quite different. Why? Why is a domain model treated differently than a read model?
We think this is an unnecessary asymmetry. To us all messages deserve individual handling and the same basic treatment. Each message thus is assigned its own message handling pipeline:
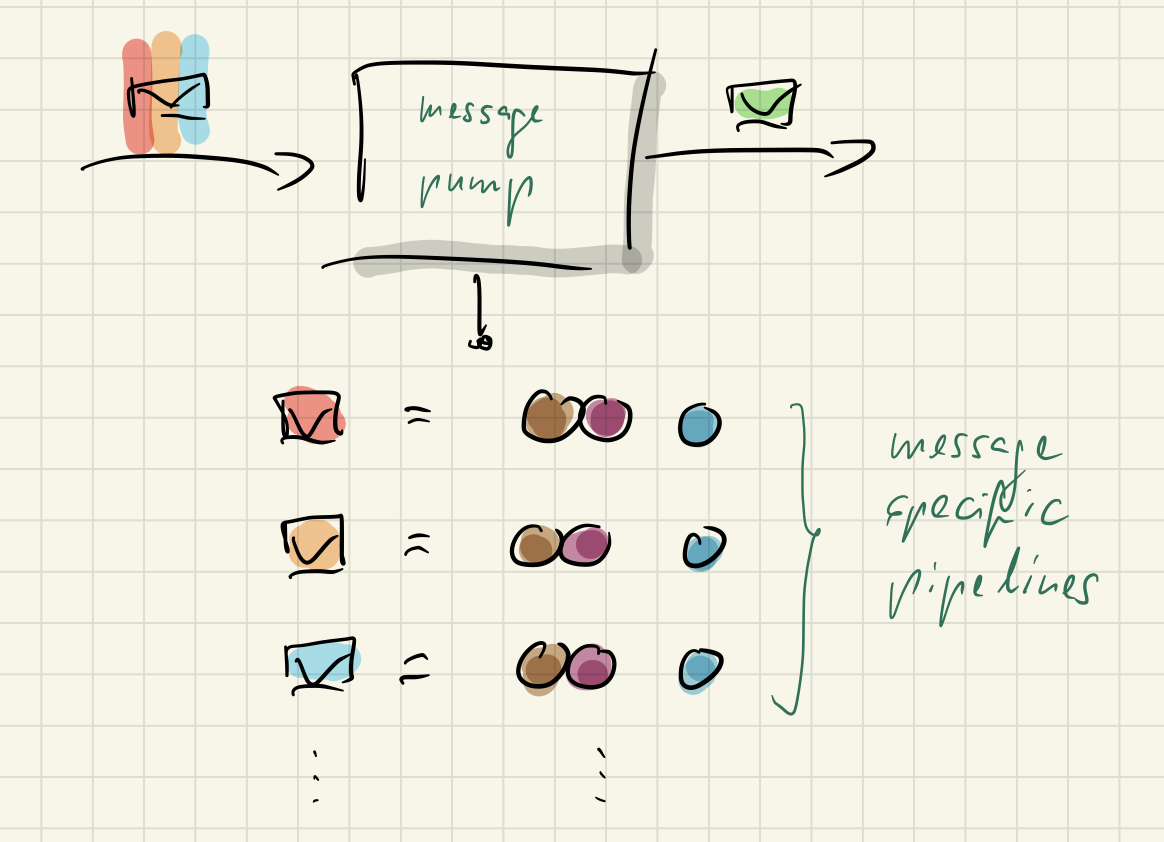
2. All messages deserve their own model
All message handlers should get their own data model by default. We call that the message context model. It’s an extreme form of what Martin Fowler describes as „multiple canonical models“. For EO every message represents a bounded context, you could say, albeit a small one.
A message context consist of all the events in the event stream relevant to handling a message. In sum they describe the current pertinent state of the application.
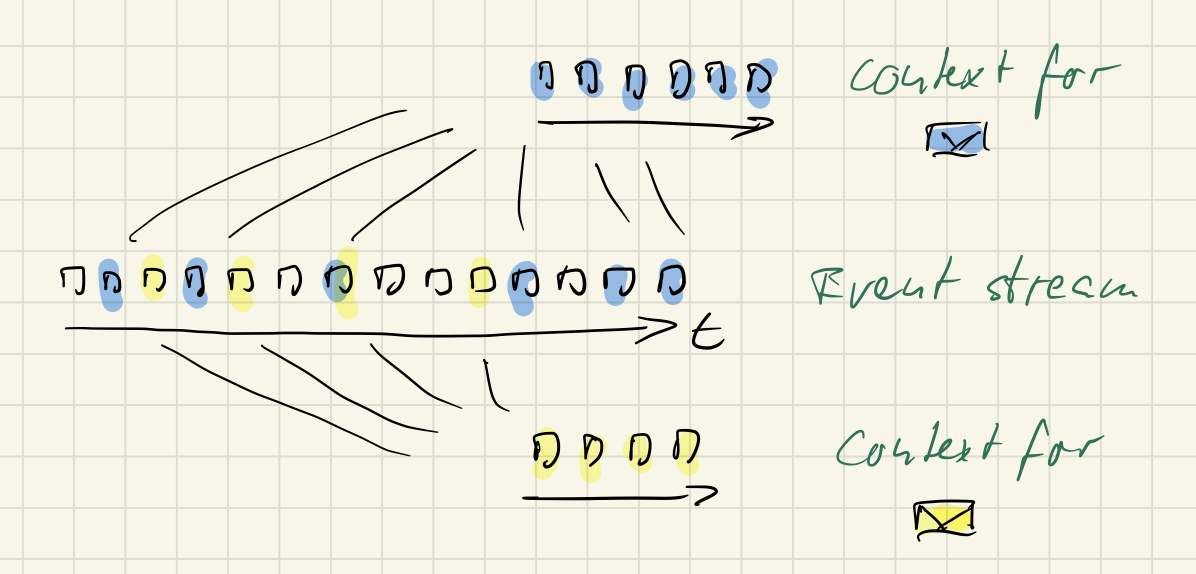
Message processing could work directly on the context, i.e. on raw events, but more conveniently it will work on a projection, i.e. some data model built from the context, the context model.
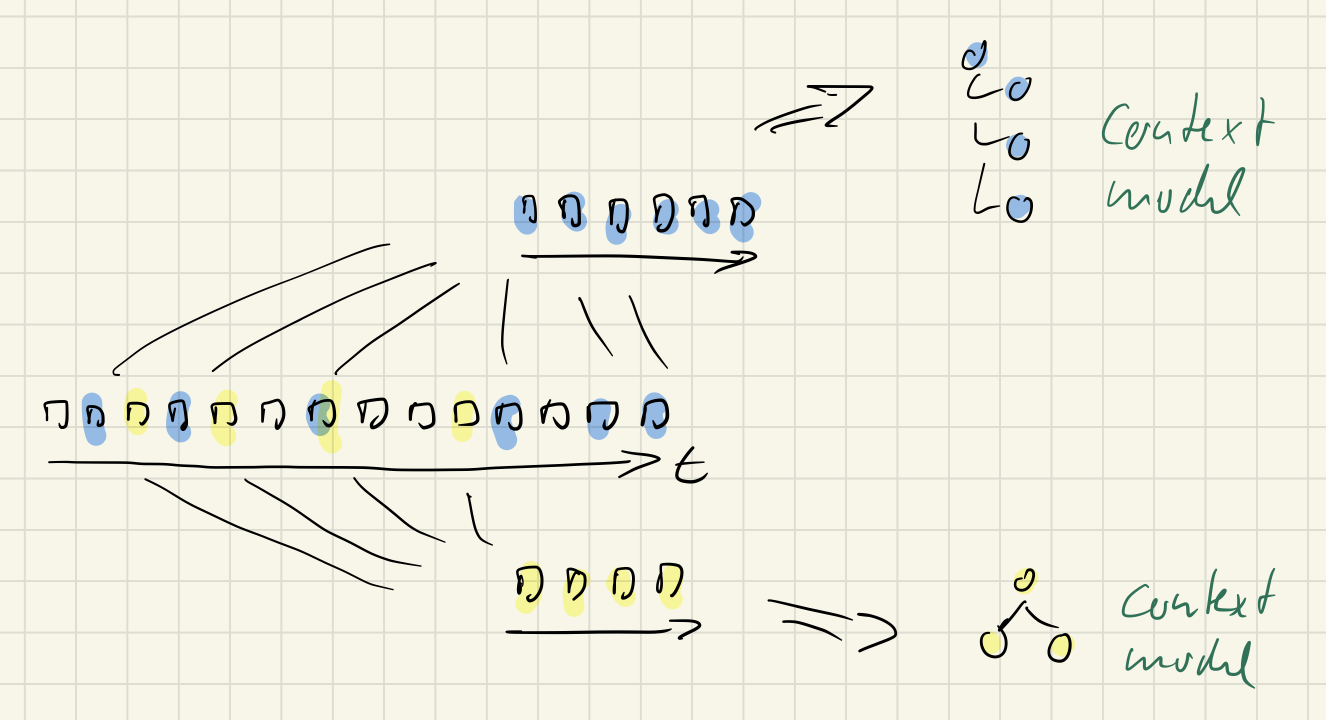
Every command, every query, every notification has its own context and context model. There is no fundamental distinction between them in content or form.
Commands and queries still differ in their purpose: commands change/write state, queries just read state. Only commands create events.
But both commands and queries base their message processing on a message specific context. The context or context model is a second input to command processing.
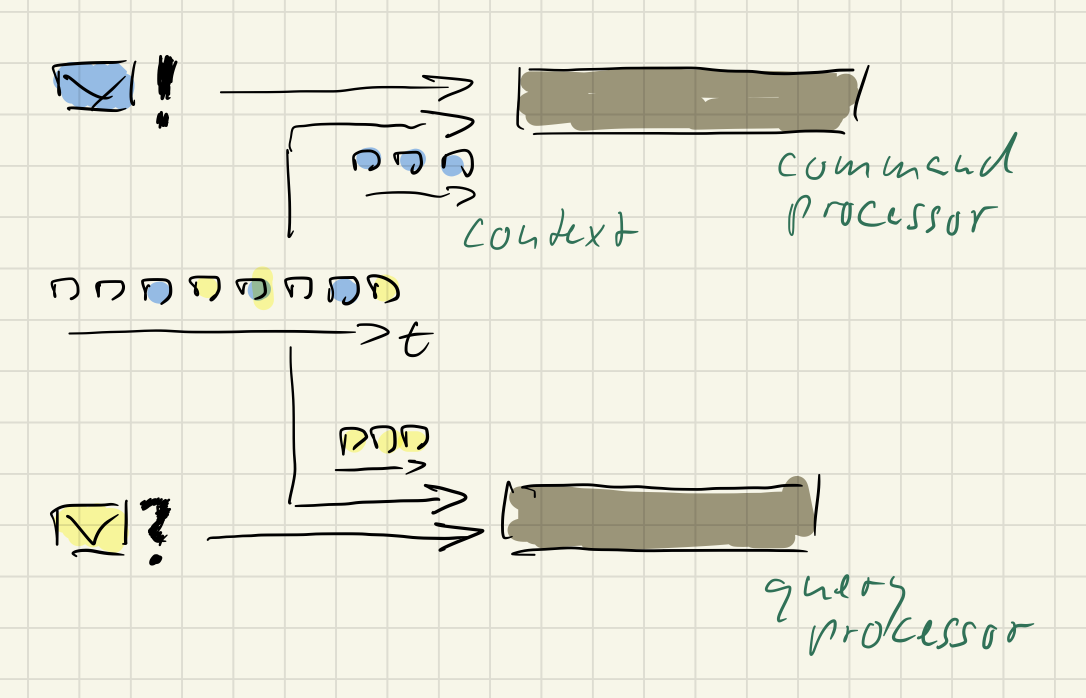
There is asymmetry in purpose, but there is symmetry in how commands and queries use the event stream to do their job.
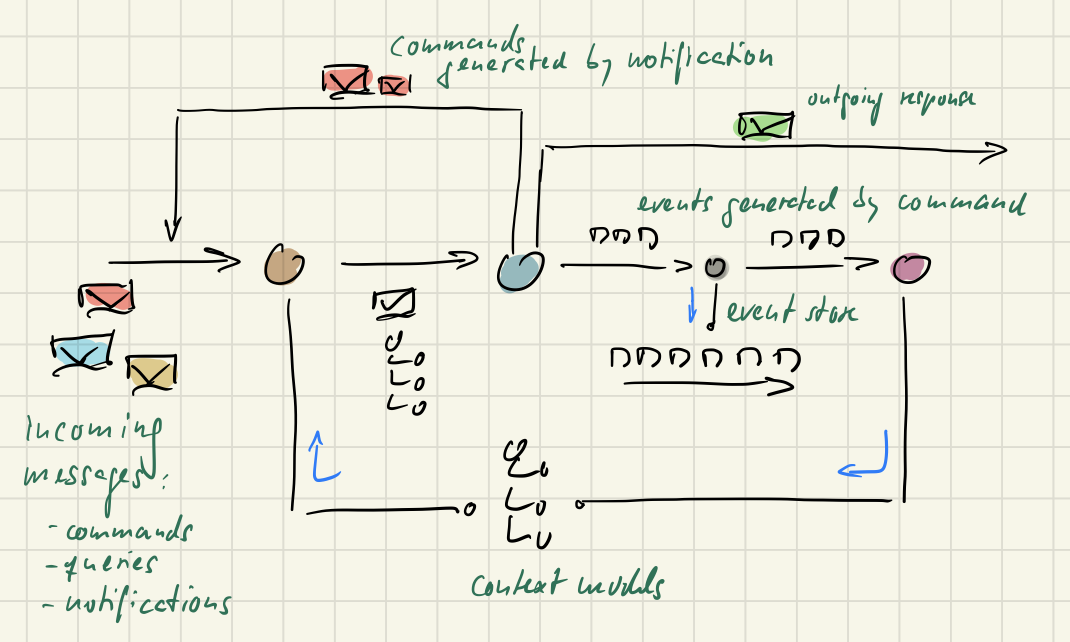
Process messages like a food truck
The image I have in my head for this is that of a food truck:

(image source: eat dring play)
Think of a restaurant as a comprehensive backend in a Sleepy Hollow Architecture. Then think of a food truck a a single message handler in a Terminus Architecture.
While an Italian restaurant offers dishes ranging from primavera bruschetta to pepperoni pizza, seafood linguine, aubergine parmigiana, and zuccotto di panettone, a food truck is focused on just one (or very few) dishes, e.g. pizza.
But more importantly in a food truck the order handling is transparent and following a simple process. Everything is happening right before your eyes:
- ingredients are prepared
- the pizza is made from them and baked
- the pizza is prepared for serving and excess ingredients are „stored“ for the next order
You can see the „order processing pipeline“ at work. Step by step your dish is prepared.
That’s how Sia and I are thinking of EO message handling: a pipeline of sequential steps through which every message gets pumped. The basic message handling stages are:
- Load the context model for a message
- Process the message in the light of the context model
- Update the context model
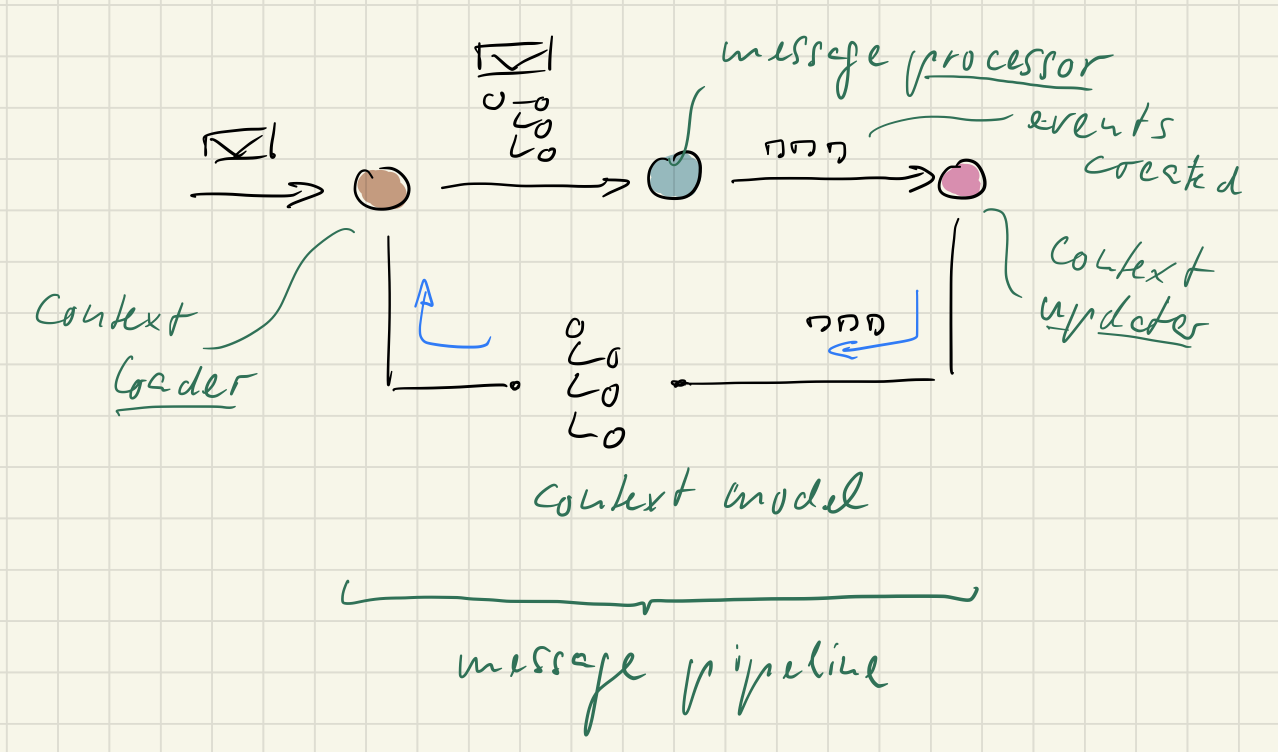
All processing steps are message specific by default. Only if patterns appear across message pipelines, abstractions should be introduced to extract common structures/stages.
This three stage pipeline is the same for commands, queries, and notifications. But the different purposes of these message types require a closer look:
- Only commands generate events to document application state changes; that means context models only really get updated after command processing.
- Notifications don’t create events directly, but commands which in turn create events. (This should also make clear that events are just internal data to record what’s happened. If something happened in the environment of a software system then that’s received as notifications. And since notifications by their very nature are no requests and don’t try to elicit a response, handling them can only mean producing commands.)
- All contexts and context models are read-only. If changes are made to them during the message processing stage, they will be discarded afterwards. Changes to the application state beyond processing a message have to be encoded in events written to the event stream. The event stream is holding the ever changing state truth of an application.
- Loading and updating context models is working only with events as data source. No other resources are used.
A Food Truck Architecture is about specific message handling like the Terminus Architecture. But this time the handling is more differentiated and based on a pattern. Each message handling pipeline is working the same.
That might look boring to you. But we find it fascinatingly relieving. We feel relieved because our thinking is guided. For each message we are asked the same questions:
- What’s the context?
- Which events are relevant?
- What does the context model look like? How little data is sufficient?
- How to build the context model? How do the events affect it?
- How to load the context model? How to query the context model with regard to a particular message?
- How to process a message in light of its context model?
We find this extremely focussing, extremely guiding. The SRP is embodied on several levels:
- Sleepy Hollow Architecture: Separate frontend and backend as two fundamentally different responsibilities.
- Terminus Architecture: Separate the different responsibilities of handling each message (representing distinct interactions with the software system).
- Food Truck Architecture: Within a message handler separate the responsibilities of representing the context model, loading the context model, updating the context model, and processing the message.
The result is a basic software anatomy made up of not only slices, but also dices:
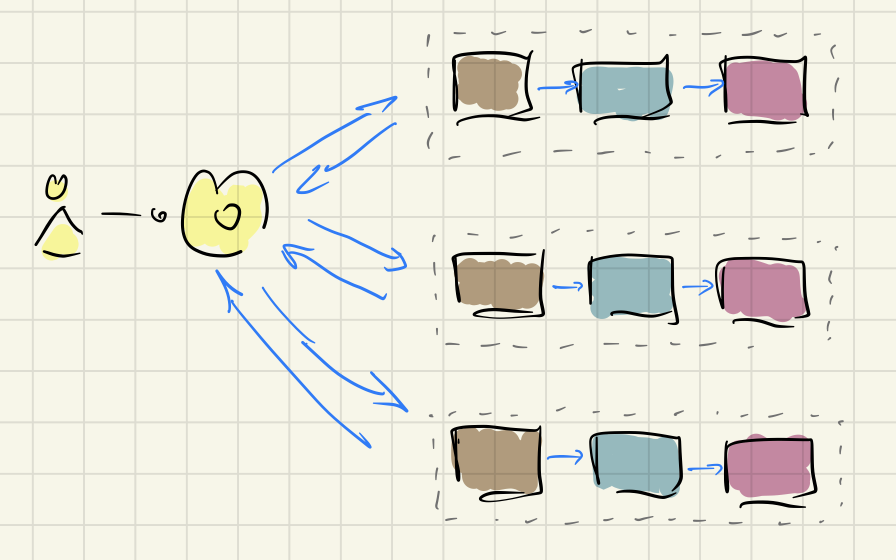
The one domain model, the few models (command+read) get dissolved into a growing stream of small events. What once was coarse grained and static now is fine grained and non-static. And all of a sudden time is very naturally manifested in the data!
To us message models – be it command models, query models, notification models – are just optimizations. They are no longer the default or what you think about first.
You don’t go hunting for data structures when you are faced with requirements. Instead you try to find the interactions with a software system, from that you derive messages, from commands you glean events, and from events you abstract contexts, from which you finally might distill models.
Event-Orientation is about all the benefits of Event Sourcing (which I don’t want to describe, but you can read about them for example here) plus the benefits of a very symmetric and consistent fine grained message handling.
This is not to say there is no domain model anymore. No, the domain model becomes even more important! So important that there are many, as many as there are messages to handle. You could call them „personalized domain models“. And since they are so message specific they look very different from your usual domain model.
The dependency between message handlers thus is fundamentally reduced. What a boon for evolvability! You can make changes to one message handler’s model without affecting others. You can add new message handlers with completely different context models without affecting existing ones.
Event-Orientation is about YAGNI and KISS for data models. Don’t do more than what’s absolutely necessary in the context of a message.
To be honest, in our experience that means, the need for treasured building blocks of tactical DDD like Aggregate and Entity diminishes. At least if you think of them as rich domain objects finely chiseled to match real world concepts. More so if you’re used to persisting them with a tool like Entity Framework or Hibernate.
If you don’t feel easy about that, we understand. But dissolving the one domain model pretty much is the point of Event-Orientation. A monolith is the quick thing to do at the beginning – but soon you find yourself painted into a corner barely able to move. „Thinking in events“ might be comparatively new, and we all certainly still have to learn a lot about it, but it’s too promising to dismiss.
Would you rather do a sculpture of a shape you’re not yet certain about from a block of marble or with clay? Maybe in the end marble is more durable. But until you know exactly how the sculpture should look, clay is much more malleable.
The difference between marble and clay? Marble is one piece, a solid monolith. Clay is millions of pieces and more like a fluid.
Our believe is that in the face of uncertainty it’s prudent to start data modelling not with a RDBMS as the default data store, and probably not even with a NoSql store like MongoDB. Don’t think „schema“, don’t even think „document“. The „clay particles“ of data modelling need to be smaller: events. From them you can build whatever you like on demand and more or less just in time.
An example application
This all might sound a bit abstract to you. So let me show you what Event-Orientation means by refactoring the stock portfolio management application from the Sleepy Hollow Architecture article to it.
Do you remember? I was able to include stocks in my portfolio (simulating a buy), update the current price of the stocks in the portfolio (by querying an online service), and eventually remove (sell) stocks from the portfolio. It’s pretty much a CRUD application with some additional online resource access.
The messages to flow between head and body, I mean frontend and backend, are as follows:
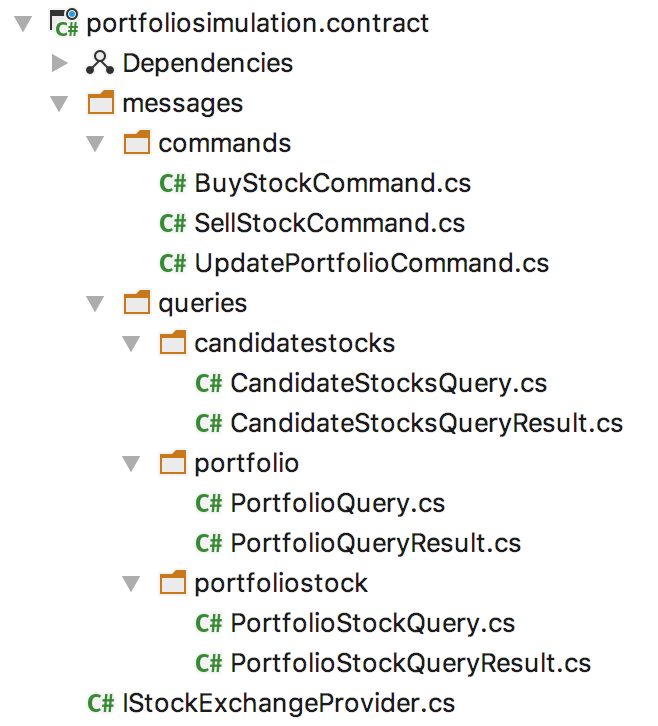
I defined them in a contract library shared by both „software body parts“. This does not change for the Food Truck Architecture.
What does change, though, is the definition of the backend interface. It’s gone from the contract. There is no single application specificIMessageHandling interface anymore like in the Sleep Hollow Architecture; there are not even message individual interfaces anymore like IBuyStockCommandHandling as in the Terminus Architecture. Instead all message handling is done by a generic infrastructure. I call it the message pump because it takes care of passing a message through its handling pipeline.

All messages are handled by the same message pump which selects the right pipeline of context model loader, context model updater and message processor from those registered.
Those pipelines are defined in the backend:
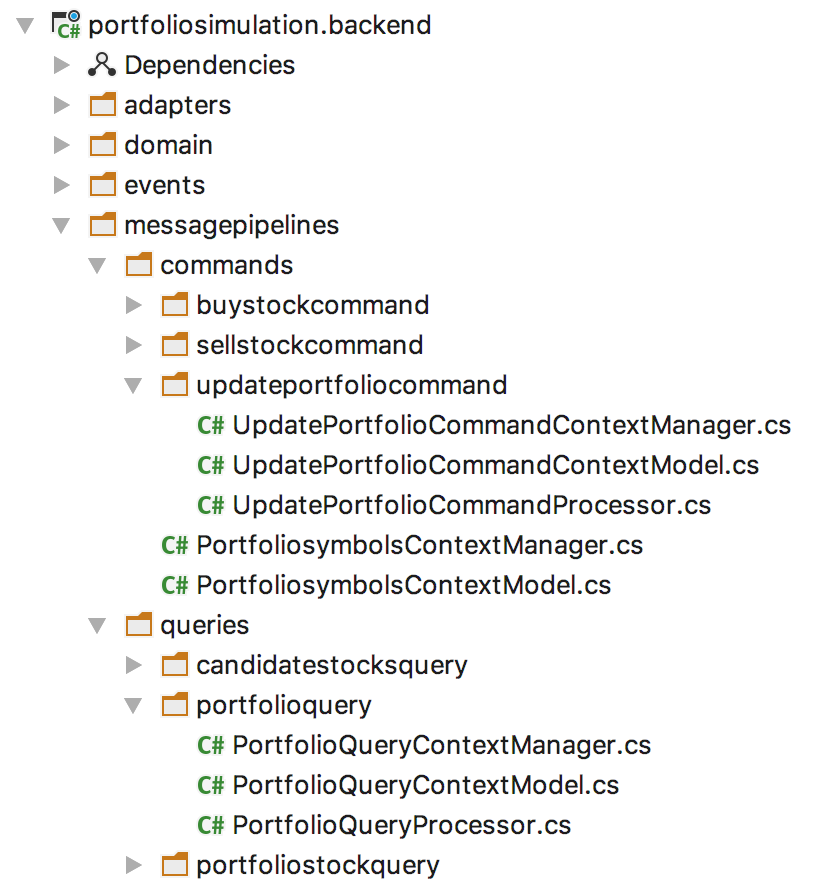
For each message there are three classes:
- the message context model
- the message context model manager responsible for loading and updating
- the message processor
Yes, that’s a lot of classes now. But that’s not a bug, it’s a feature. Because more classes mean more guidance and more focus. Look at the pipeline for the BuyStockCommand for example:
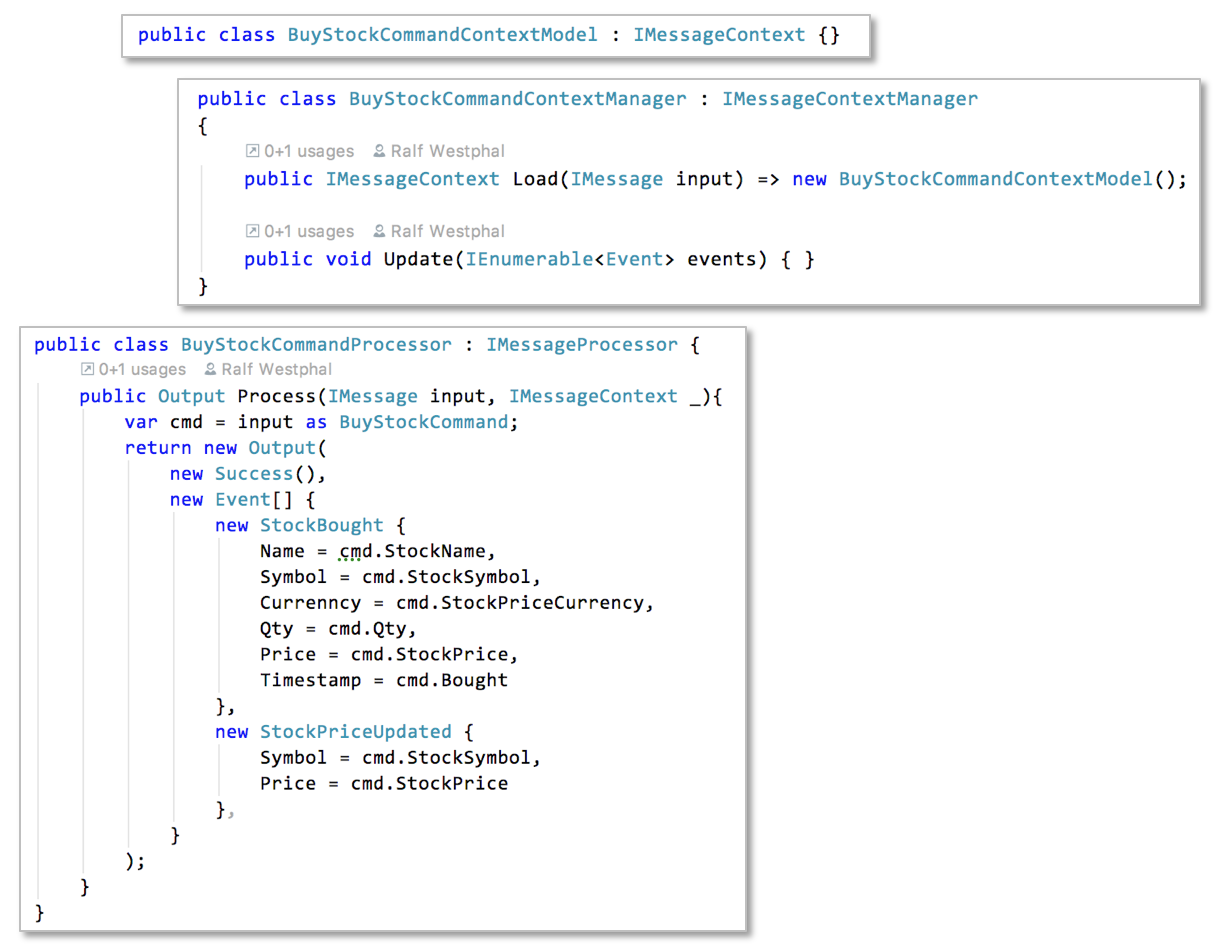
While working on handling this command I just needed to focus on the needs of its pipeline.
- What data does this command need to do its job? Commands can succeed or fail depending on the current state of the application. In this case my decision was: the command does not need any data at all. No context needed. It will always succeed. (Well, I could have come up with some validation logic (check for the quantity bought to be larger than zero, for example). But that still does not need any context.) Hence the context model class is empty and the context manager’s methods do nothing.
- How to process the message in light of its context? In this case just a simple mapping from message data to events is needed.
- Which events should be generated? I decided to record buying a stock with the
StockBoughtevent plus aStockPriceChangedevent. Why two events? Because actually two things are happening: One is, that a stock was bought. That’s obviously what the command is about. All pertinent data gets recorded with theStockBoughtevent. But then the command carries an information which could also have been acquired another way: a stock price. Usually stock prices get updated by querying an online service while processing theUpdatePortfolioCommand. But for whatever reason aBuyStockCommandmight carry a more current price; then that should be recorded appropriately. But why then not remove the stock price property from theStockBoughtevent? Isn’t that redundant? Yes, in principle. But I keep it in there to make both events independent of each other. Another example of decoupling.
Speaking of events: they are a matter of the backend only. Nobody is gonna see them so they are defined in the backend project:

The event store, which is part of the EO infrastructure like the message pump, defines an Event base class to derive all concrete events from:
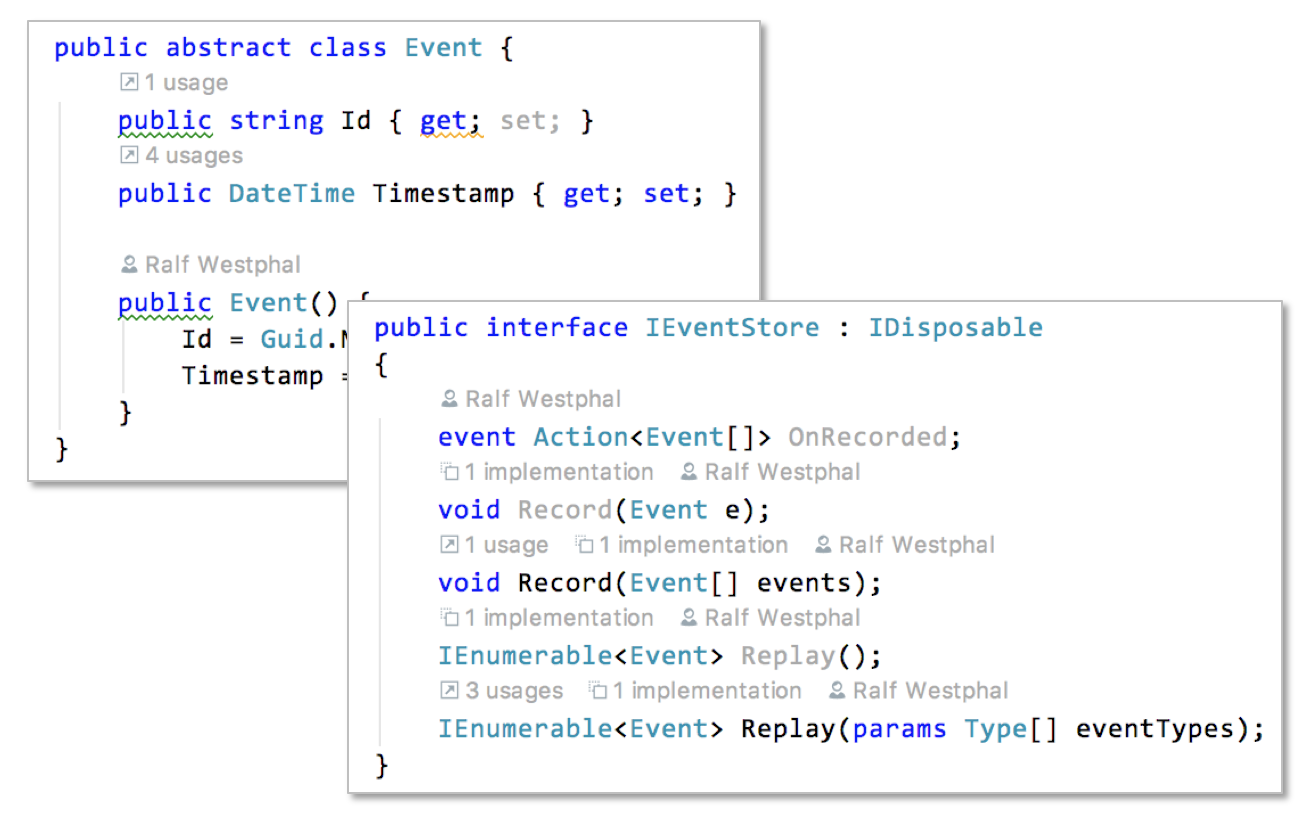
Which events there should be is a matter by itself I don’t want to dive into here. For a CRUD application like this they sure are few and simple. But to me that’s not a sign for a domain or use cases unworthy of EO. Right to the contrary! Let’s start simple to get used to the overall paradigm of EO and the Food Truck Architecture. If the application shows itself to be useful it sure will grow and soon move beyond simple CRUD. And then I’ll thank myself for betting on EO from the beginning.
Sharing a context model
The command for buying is trivial: no context model, just a mapping to events. Now for a command which actually needs a context model: the command for selling stock.
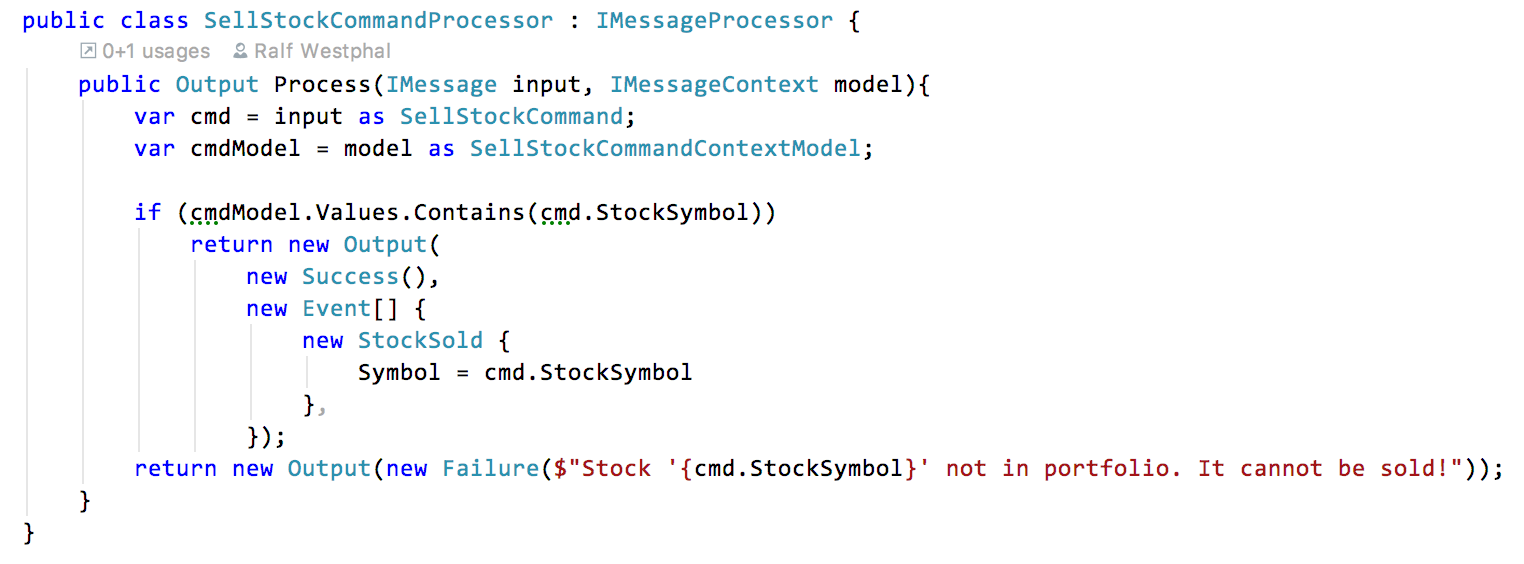
As you see the processor checks if the stock supposed to be sold actually is in the portfolio: if (cmdModel.Values.Contains(cmd.StockSymbol)) Only if that’s the case a StockSold event is recorded. (Remember: there is no change to persistent data models in EO! Changes are recorded „over time“ in the event stream by appending new events. This was different in the architectures before.)
Try to feel the beauty of this: While focussing on message processing I did not have to worry about where the model came from. It’s just there and has exactly the form and content as needed. Nothing more, nothing less.
And what’s the form and content of the message context model? That’s a matter of a different class: its context data class and its context manager class.

Interestingly they are „empty“. That’s because the SellStockCommand is sharing its context model and context model manager with the UpdatePortfolioCommand. Both need just the symbols (e.g. „MSFT“) of the stocks in the portfolio.
Yes, just the symbols! No special IDs, no price, no quantity, no „real“ domain data model. The context model is stripped down just the data needed in the very limited context of one message to handle. If a list of symbols is enough, then that’s what the context model contains. If more is needed like for processing the PortfolioQuery, then more is included. Contexts can encompass any number of events from the event stream: 0, 1, many. Contexts models can have any form: they can be empty, consist of just a single number, a list of strings, or intricate object graphs.
When I migrated the application from Terminus to Food Truck Architecture I first made the context model with the stock symbols specific to the SellStockCommand. Only when I started my work on the UpdatePortfolioCommand I realized its context model needs where the same and I move it and its manager to a base class. (Base classes and derived message specific classes are not needed. I just could have registered the same message context manager object for two messages with the message pump. But I found it more regular/consistent to have specific context model and manager classes.)

The context model is mainly managed in the Update() method. Whenever there are new events it gets changed. (And upon application start it’s initially „inflated“ from all past relevant events in the stream.) The context consist of all StockBought and StockSold events. And the model distilled from that is just a collection of symbols.
Loading the context model thus means just delivering the current list to the processor. It does not need to be further narrowed down.
What’s done with the context model in the command processors differs, however. When selling a stock the processor checks a symbol for existence in the list. When updating stocks the processor takes all the symbols in the list and for each retrieves the current stock price from an online service.
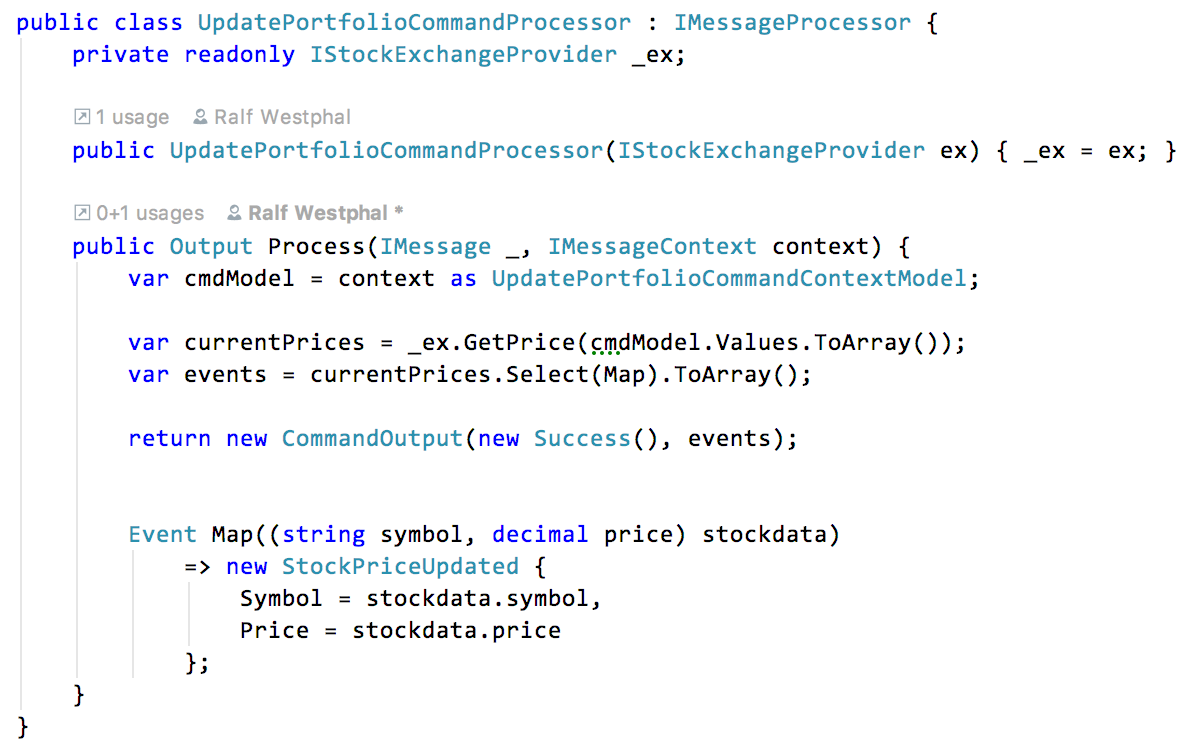
The message pump
Messages flow through their pipelines by virtue of a generic message pump.
On the outside the message pump only produces an IMessage as a response. It’s either a command status or a query result. That’s what a client (the triggering environment) wants to receive.
But inside the message pump the message processor returns an Output tuple. It’s a structure matching the needs of all message processors, be they command or query or notification processors.
- A command returns a status plus a list of events.
- A query just returns a result.
- A notification returns just a list of commands.
Using a structure like this makes downstream handling in the pipeline straightforward:

- A message gets handled by selecting the appropriate pipeline consisting of loading/updating the context and a processor.
- The message pump lets the message flow through the selected pipeline: first the context (model) is loaded, then the message gets processed with the context (model), finally the output produced gets „dispatched“…
- … which means it gets treated according to what it is:
- from a query output the query result is retrieved and returned
- from a notification output the commands are retrieved and handled individually by calling the message pump’s
Handle()recursively - from a command output the events are retrieved and recorded, and the status is returned
- Also the events produced by a command are used to update context models…
- … by calling all registered context updaters and offering them the events for assimilation. Some will be interested, some not.
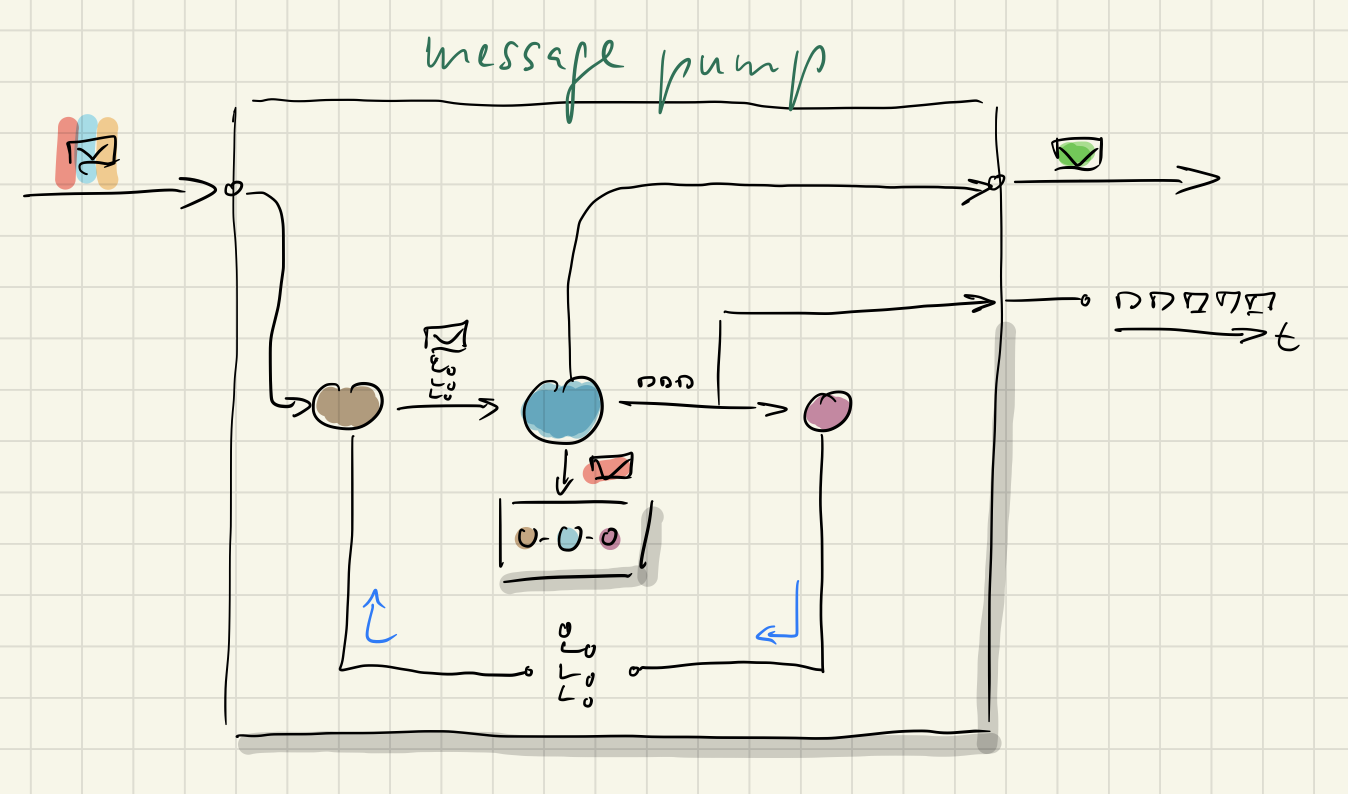
All together now
It seems there are many moving parts in the Food Truck Architecture. But as I said: that’s a feature. Many moving parts means small parts, dedicated parts. And it’s not difficult to keep them in your head, since there is clearly visible cohesion between the pipeline stages and obvious boundaries between pipelines.
So what needs to be done to get an application going is to register the pipelines with the message pump (1): create message processor and context managers and associate them with a message.
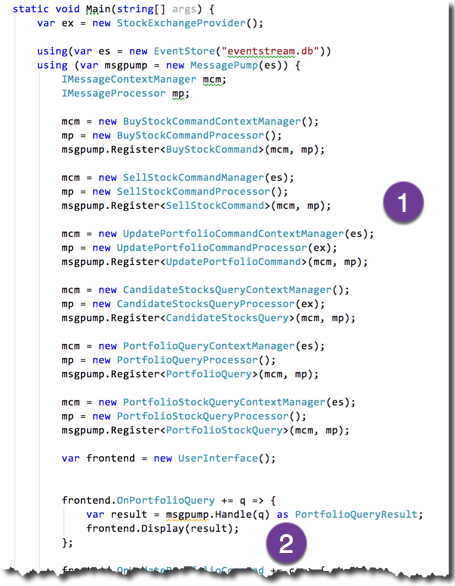
Once that’s done the actual message handling (2) does not differ much from the Terminus Architecture. It’s just that instead of different message handlers there is one, the universal message pump.
Summary
That’s a first basic implementation of the Event-Orientation concept. It sure can be improved. As can be the event store which is very, very simple and homegrown. But that would not change the overall approach which is, that software structure first and foremost is focused on message handling and that all messages are processed within a context of events which embody the incremental change of application state.
Refactoring the sample code to the Food Truck Architecture was a great experience. I really felt guided and focused; there were easy to follow steps.
- Find the messages to be processed by an application (Sleepy Hollow Architecture).
- Derive the events to be generated by the commands
- Select a message to focus on and a create a „compartment“ in the codebase for it (Terminus Architecture)
- Define the message handling pipeline for the message inside the „compartment“ (Food Truck Architecture):
- Define the message context model
- Implement the message context manager with its loader and updater
- Implement the message processor
- Go back to 2. until all messages are covered.
Sure, some challenges remain: you need to decide how to store any context models, and most importantly you need to implement message processing. But with the Food Truck Architecture this is presented to you on a silver platter. You don’t need to come up with that yourself again and again.
Software development is broken down for you. And what’s most important is delivered to your doorstep wrapped in a neat interface:
Output Process(IMessage message, IMessageContext context)
That is what every application revolves around. That’s the beating heart at its center. From that all else is derived by asking:
- What messages are there?
- What’s their message contexts?
- What events are there in the first place?
- What should the message context models look like?
- What events to generate from commands?
- What commands to generate from notifications?
- What results to generate from queries?
What messages there are is driven from the outside. It’s a matter of interaction with the application. What are the use cases? How should the UI look like?
The rest grows from them motivated by the core function signature of Event-Orientation for message processing.
Give it a try!

