Sleepy Hollow Architecture - No application should be without it
There is a basic structure of software systems I’m drifting towards more and more. To me it’s more fundamental than MVC or Layered Architecture or Clean Architecture. I call it the Sleepy Hollow Architecture because it’s about dissecting code into two parts: a body and a head.
Do you remember the movie Sleepy Hollow by Tim Burton? Starring Johnny Depp and Christina Ricci among other well-known actors. It’s revolving around a headless horseman terrorizing the town of Sleepy Hollow.

I’d call the headless horseman one of the main characters, even though it’s just a body without a head.
But the movie also tells the story of how he lost his head. So the head also plays a role in the movie, albeit a small(er) one, even though Christopher Walken is the actor in those scenes.

In Sleepy Hollow what usually is seen as a single unit – or a monolith, I could say – is fundamentally split into two sub-units of unequal importance.
And that’s what I think should be done with software, too. Let me even be so bold as to say: with every software.
A fundamental distribution of code
In my view software should consist of a body and a head, too. And the really important part then is the body. It can even be used without a head. Or it can be given different heads.
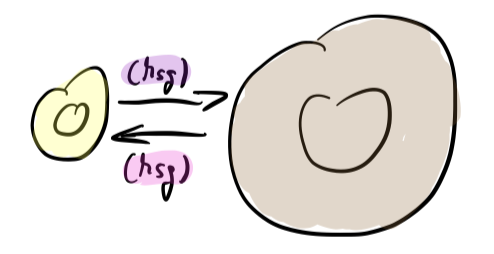
Usually a software is seen as „one thing“ with a basic anatomy working in an environment:
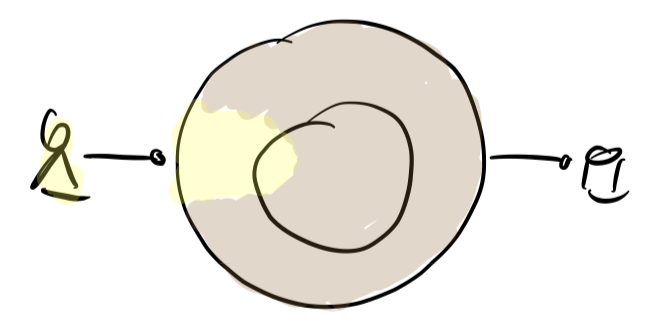
There is a user interacting with it (left side), there are resources used by it (right side).
The code inside is partly dedicated to the interaction with the user, it’s (G)UI code and maybe some validations; let’s call that the frontend (yellow area in above image). But mostly it’s domain logic and resource access; let’s call that the backend (brown area).
Unfortunately both aspects of the code are often quite entangled. And even if they weren’t it would be hard to test the bulk of the code, the backend. Testing frontend code or testing the backend through the frontend is technically possible, but usually not much fun and brittle.
That’s why I suggest a fundamental separation of both aspects! Frontend and backend should be physically very distinct, if not not even two processes. We should pull out the frontend from the software. We should unstick it from the backend.
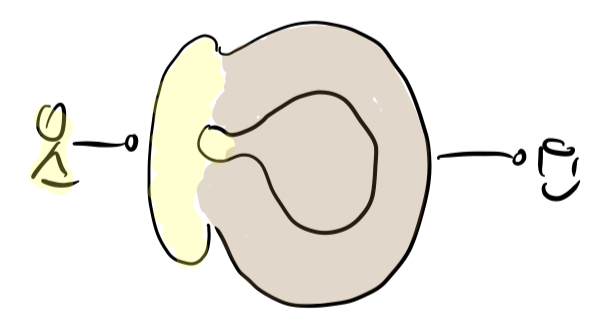
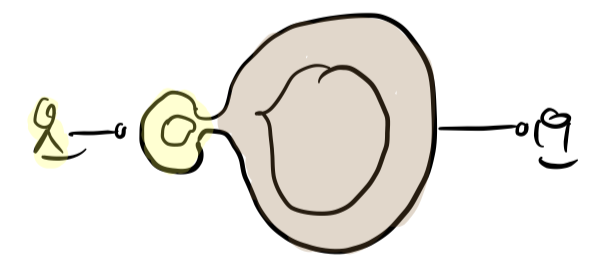
Until it’s a free standing aspect - and why not in it’s own process. Head and body separated. The backend now being headless domain and resource logic.
The minimal version of this would be frontend and backend being two components with a distinct contract. But even two processes running on the same machine would not hurt much in most cases, I guess. The frontend process could host the backend process; no additional infrastructure required.
That would mean distribution, but on a small scale. This kind of distribution would be not for scalability or security, but for increased testability and adaptability/flexibility.
Communication would happen in a message oriented manner:
That way even different heads „could be screwed on“ the backend.
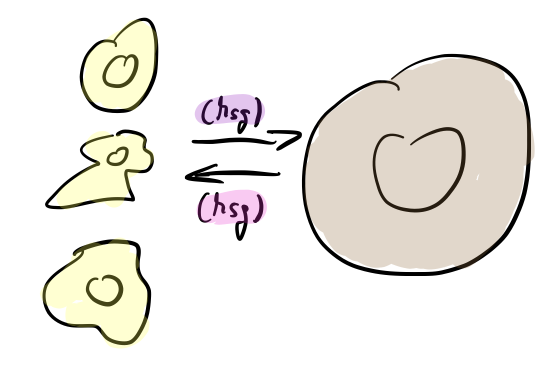
Again, this is not about the usual client-server distribution for scalability purposes. It’s more fundamental!
I strongly believe that one of the most common fallacies in software development is that the frontend should be „welded to“ the backend. Up to the point of SQL statements in button click event handlers. (Yes, I have seen horrible stuff like that.)
There are two problems with this: aspects get scattered all over the codebase and testability is low.
With the Sleepy Hollow Architecture it’s different. Two fundamental aspects are clearly separated with a distinct contract between them.
The head is where users interact with the software: they trigger behavior by pressing buttons or clicking a menu item or just hitting ENTER. Behavior is an observable change of state. Software reacts to input data with output data.
How the input data is gathered from the user is a matter of the frontend. How the output data is presented to the user is a matter of the frontend.
The backend is only concerned with transforming input data into output data while using resources. It’s oblivious to how the arriving data structures got built or how leaving data structures are used.
Head-body communication
The contract between head and body is a set of messages. I’ve come to like the following classification. It’s based on the CQS principle.
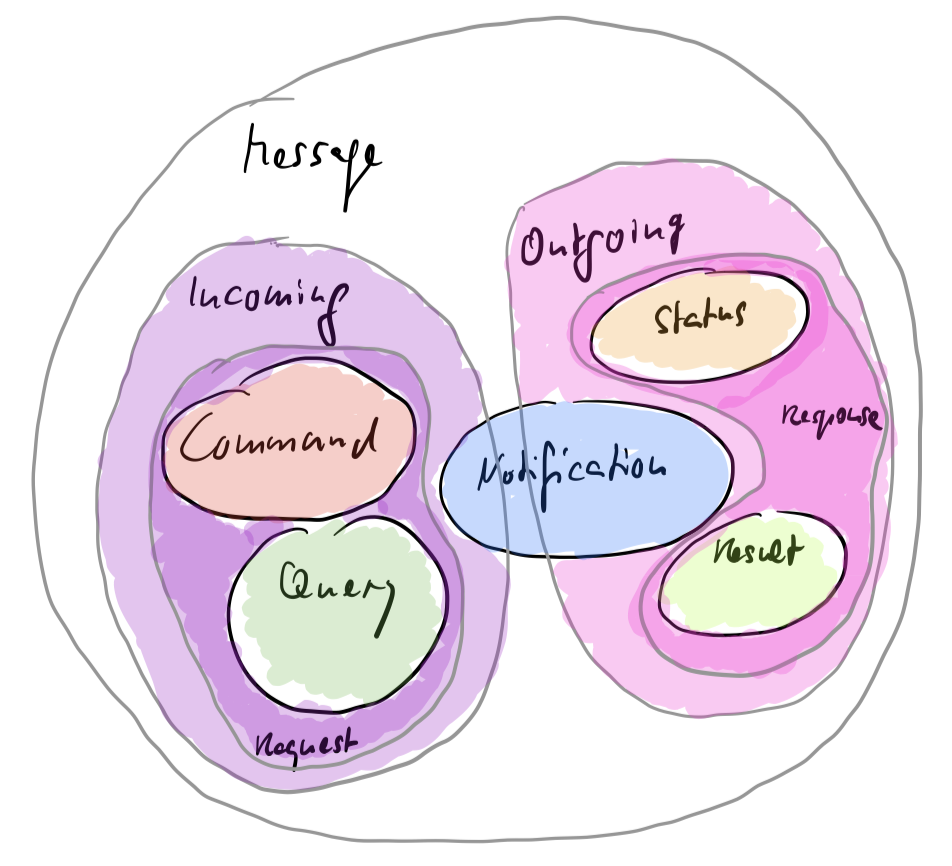
Incoming messages at the backend are either commands or queries. They both are requests.
Commands trigger some kind of state change in the backend (or connected resources) and return a status information about how that went.
Queries just work on the state as it is. They cause the delivery of a result as an outgoing message.
Status and result both as responses to requests.
Notifications are events received from the environment (i.e. other software systems). They are not issued by a user with the intention of „hearing back“ from the receiving system.
But notifications don’t just flow into a backend. Backends might also send out notifications with the intention to inform other interested parties (of which they don’t know) about what’s going on.
Notifications are usually not created by visual frontends, I’d say.
The purpose of the backend now is very focused: message handling. Whether messages arrive through an in-proc call or through HTTP or a named pipe is of no concern to the Sleepy Hollow Architecture. It’s the mindset that counts. It’s the will to a clear separation of frontend and backend while connecting both with an explicit message contract.
So much for theory and concepts. But how does that look in code?
An example application
Here’s a scenario:
I’d like a software to help me observe the stock market. I can create a portfolio of stocks and check how the portfolio is doing. Adding a stock is like simulating a buy.
From that I derive a simple UI:
$ portfoliomanager
1. Microsoft (MSFT), bought: 3x99.00=297.00, current: 3x115.00=345.00 - +48.00 / +48,5%
2. Apple (AAPL), bought: 5x156.00=780.00, current: 5x179.00=895.00 - +115.00 / +14.7%
Portfolio value: 1240.00 / +15.1%
::: B(uy, S(ell, D(isplay, U(pdate, eX(it?: B
Identification?: Thermo fisher
1. Thermo Fisher Scientific Inc
2. Thermo-electric power station Maritza 3 JSC
3. Vikram Thermo (India) Ltd Dematerialised
...
Choose no.?: 1
Name: Thermo Fisher Scientific Inc
Symbol: TMO
Current: 243.90
Qty?: 4
Total paid: 975.60
::: B(uy, S(ell, D(isplay, U(pdate, eX(it?: S
Identification?: apple
1. Apple (AAPL)
Index of stock to sell?: 1
Sold 'Apple (AAPL)'!
::: B(uy, S(ell, D(isplay, U(pdate, eX(it?: D
1. Microsoft (MSFT), bought: 3x99.00=297.00, current: 3x115.00=345.00 - +48.00 / +48.5%
2. Thermo Fisher (TMO), bought: 4x243,90.00=975.90, current: 4x244.10=976.40 - +0.50 / +0.00%
Portfolio value: 1321.40 / +3.8%
::: B(uy, S(ell, U(pdate, eX(it: X
$
(Sorry, it’s no fancy GUI. But I’m not into WPF/WinForms anymore since I’m only using a Mac.)
Messages needed
What messages would flow between frontend and backend for this?
- A command to update the portfolio with current stock prices. A call to some online service will be necessary, e.g. Alpha Vantage.
- A query to get the current portfolio.
- A command to buy.
- A query to list candidate stocks matching the identification provided. A call to some online service will be necessary.
- A command to sell.
- A query to find the stock in the portfolio best matching a search pattern.
With these incoming messages in hand I can now start building the application incrementally message by message. And I can even start building it starting from the backend. Or I could outsource the frontend to be worked on in parallel.
Admittedly some more details are needed for the incoming (and respective outgoing) messages. But that’s not the point here. I want to show you how I think this could look in code with a Sleepy Hollow Architecture.
Code structure
The Sleep Hollow Architecture is a „poor man’s Layered Architecture“, you could say: it consists of just two layers instead of three or four. This is mirrored in the basic code structure. I created 2+1 C# assemblies (libraries) to represent head and body, frontend and backend:

And both libraries depend on a third: the contract. It’s there that the backend’s main interface is defined plus all the messages.
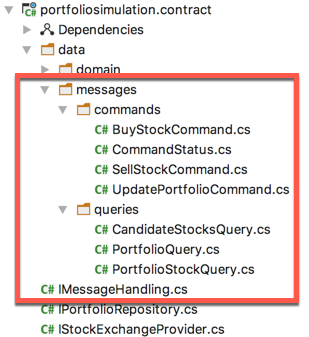
In addition it contains some more interfaces and data types, but that’s not really of concern here. It’s a detail of the backend implementation.
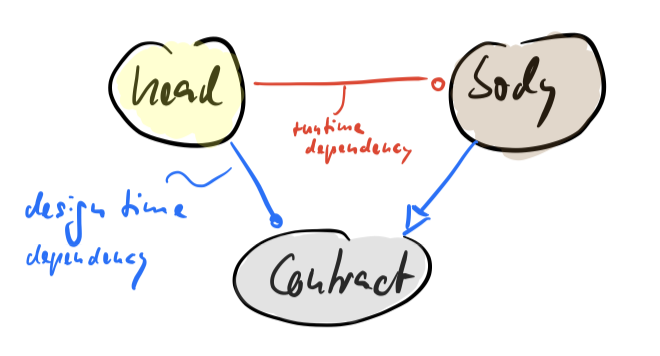
Although head and body don’t know of each other due to the Dependency Inversion Principle (DIP) – the body implements the common contract, the head uses the common contract –, at runtime there still exists a dependency: the head is calling the body because the head alone is pretty useless. Its sole purpose is to make interaction of the user with the body easier.
Over the past years I’ve developed this strange view that user interfaces are data structure editors and data structure projectors. Human users only need them because they don’t want to or cannot (due to complexity and time constraints) edit and interpret JSON data structures. In principle only backends are needed to create desired output data from input data. In principle humans could feed the input data as JSON text and receive output data as JSON text (or XML or any other data format you like). It’s just that it would be more tedious and error prone. That’s why (graphical) user interfaces were invented: they are tools which allow mere mortals to create data structures and view data structures without even realizing it. No more, no less.
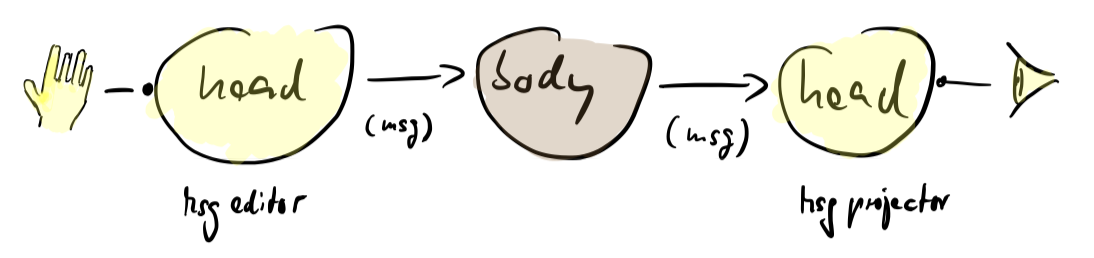
That’s not to say user interface are not important. Right to the contrary! Without them most backends would be useless. It’s an art to design a truly helpful user interface! We need more people being good at that.
However that should not mean user interfaces need to be „close to“ their backends in any way. Also right to the contrary! User interfaces – heads – and backends – bodies – are so different as two sides of the software medal they should be very, very clearly separated. That’s what the Sleepy Hollow Architecture is about.
If you don’t have much of a clue as to how to architecture your software, do yourself at least the favour of chopping the head off! You’ll be rewarded with
- better testability
- easier incremental development
- more options for further decomposition
- a starting point for division of labor
But now on with the code…
The head needs the body at runtime. How is the body attached to it? That’s the responsibility of an „integrating code unit“ I put into yet another assembly:
And there you have it: that’s how the Sleepy Hollow Architecture can be implemented.
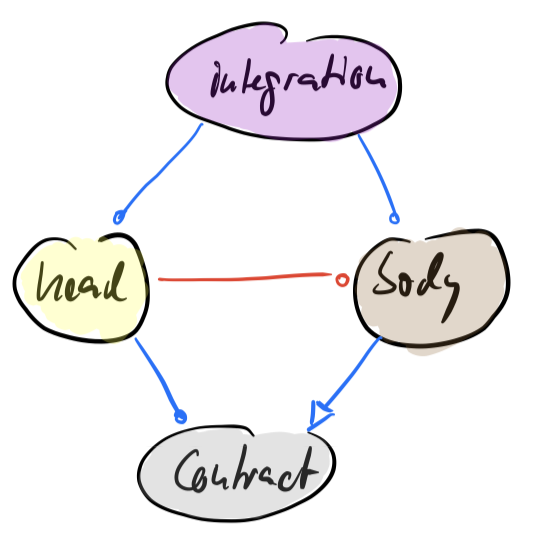
But that’s only the start! With a clean contract between head and body you can do more:
Distribution
Do frontend and backend need to be implemented with the same programming language/platform? I’m using C# for both, but that’s not really necessary. Since head and body are based on a common contract which defines messages flowing back and forth it’s easy to separate them even further.
Yes, that’s the secret of the Sleepy Hollow Architecture, I’d say: a shared message contract instead of a shared stateful data model. Whatever state is needed is a private matter of head and/or backend. No state is „leaked“ to the other code body part.
I’m not against state in any way. In-memory state in the frontend is just fine for me. Likewise I’m not offended by in-memory state in the backend. Maybe things would be better without it, but that’s not a matter of the Sleepy Hollow Architecture. Use in-memory state or just persistent state to share information across incoming messages or between different message handlers. The really important thing is:
There is no state shared between head and body!
If you manage to do that, then head and body can be pulled further apart into different processes.
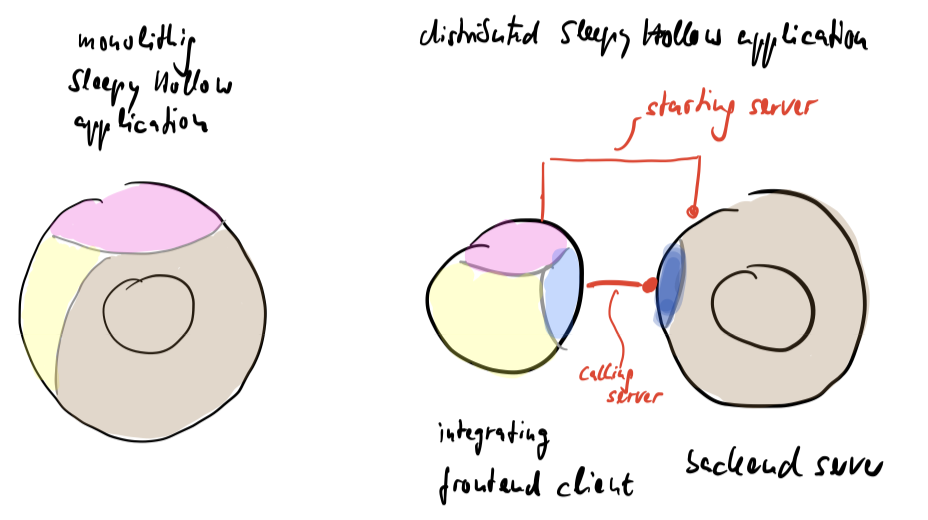
Technically this is a client-server or 2-tier architecture. But how far apart head and body are located is not a matter of the Sleepy Hollow Architecture. They could reside on different devices or on the same. Yes, even on the same device would make sense to me: a frontend process could start its own backend process. Why not? Google Chrome is doing that for every page you open.
The benefits would be stability, productivity, flexibility or just independence in general because now you’d be free to use whatever programming platform you like to implement them. Use C# with WinForms for the frontend and Rust for the backend. Or use JavaScript and Java? Or Java and F#? Whatever suites you best. (If you ever wondered whether micro services are for you here’s a scenario to get you feet wet with. To me head and body processes are micro service because the purpose behind them is evolvability, not runtime efficiency.)
Also you can start with either body part. I, for example, started with the backend. Only after the backend was finished and covered by acceptance tests exercising the message handler I started working on the frontend.
Since I used C# for head and body I hosted both in the same process at first. A monolithic, yet component oriented application still is easiest to build. Once that was working, though, I separated the body from the head.
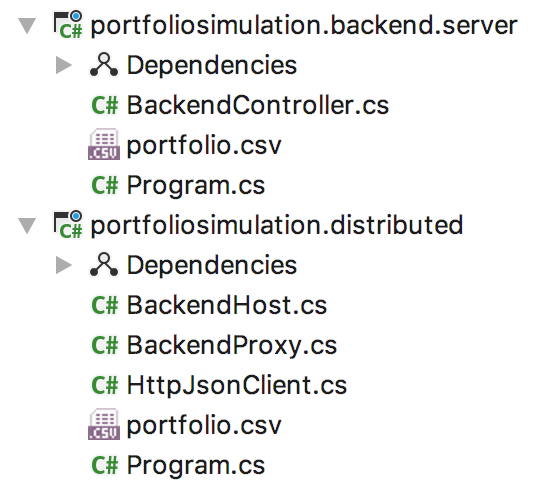
I built a backend server to host just the backend and make it accessible through a HTTP controller.
And I built an integrating server to host the frontend – and also start the backend server.
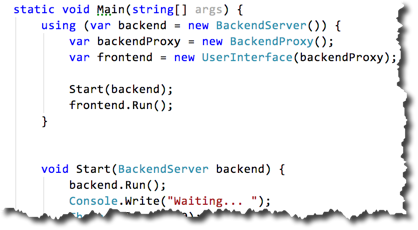
The user interface does not realize it’s now talking to a backend in another process. The proxy injected into it is looking like „the real thing“.
To be able to do this trick with head and body – almost like a magician sawing a woman in half – I like to use dedicated types for the messages flowing to and from the backend. Here’s an example:
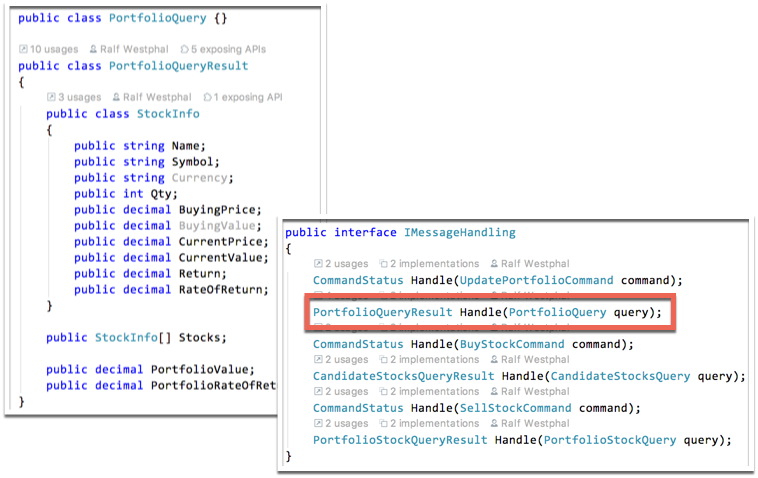
This seems to be an overhead at first. Wouldn’t a method do with a more specific signature, e.g. Portfolio Load()? Sure that would do the trick, too. But it’s less versatile/flexible and requires me to think more.
- With individual method signatures I’d need to think more because I’d immediately need to decide which name and parameters to give the method. To follow the CQS and define two messages is much less of a mental burden. With message types I just have to define two classes with a pretty obvious name following a simple convention.
- And I find methods with a variable number of parameters harder to use in different scenarios. If backend message handlers follow the rule of always being functions with exactly one parameter lot’s of things become easier (tooling, distribution). Also messages packed into data structures are easier to route or cache if need be.
The Sleepy Hollow Architecture does not require such message types. But whenever I started without them, trying to optimize for some crude notion of productivity, I came to regret it sooner than later. Maybe, just maybe, such a contract with explicit message types makes you somewhat slower in the beginning. In the long run, though, I’ve come to realize it was always worth it – and should be done right from the start.
Summary
To me the Sleepy Hollow Architecture is the default architecture for any software. Less structure, less separation of concerns don’t work for me. I’d almost say, it’s the first architectural pattern to teach newbie programmers.
Distribution of head and body is not necessary. But „near-tier“ isn’t that difficult, either. Maybe it’s even a motivation to introduce simple cross-process communication in the first place, since the efficiency demands are not high in this relationship between client and server.
In any case the Sleep Hollow Architecture is an easy means to make the different responsibilities of frontend and backend clear. And not the least it’s an excellent foundation for test-first development and putting much of an application under automatic test. The real workhorse, the real warrior is the body, the backend. That needs to be tightly monitored, there’s lots of refactoring about to happen. The head, the UI, might look horrible, but in the end it’s useless without a solid body. And I’d even say it’s easier to focus on if a body does not „dangle“ beneath it all the time.

