The SRP is not about „extract till you drop!“
I have been chasing a better definition for the Single Responsibility Principle (SRP) for quite a while. „A reason to change“ is too fuzzy for me. And even Robert C. Martin’s latest explanation does not fit the bill, I think, even though I like it more than previous definitions:
In order for a function to do “one thing” it must be so small that no meaningful function can be extracted from it. Any function from which another can be extracted clearly does more than “one thing”.
The other day I came across his article „One Thing: Extract till you Drop.“, which seems to be an early appearance of his above definition. And now I know why I don’t like it as much as I first though.
Let me explain...
A dirty code example
Look at the dirty code Robert C. Martin presented:

What’s so dirty about it? It’s mainly some 7 lines of logic in replace(). Do they need refactoring? Does the whole class need refactoring?
What bothered me most when I looked at that code first was not that it violated the SRP in some way. Besides being not so familiar with Java I rather stumbled over:
- the lack of at least a single automated test
- the missing function
getSymbol()
I did not really get what the code was supposed to do for quite a while. The explanation given
It’s not too hard to understand. The replace() function searches through a string looking for $NAME and replaces each instance with the appropriate translation of NAME. It also makes sure that it doesn’t replace a name more than once.
still left me with question marks over my head. And I think a simple test or some other form of application/example would have helped me to get what the overall purpose (responsibility) of the code was.
So what I did before reading on was set up a JDoodle project and play around with the code. I got it to run with a small main() function and sample data as I imagined it:

For that, though, I had to come up with a getSymbol() of my own. What was that method about? And why was translate() just redirecting to it?
In the end I settled for a trivial implementation:

I assumed the method to translate a placeholder like „$X“ into some other text. For understanding the workings of replace() such a translation would not have to be sophisticated. The resulting string then looked like this:
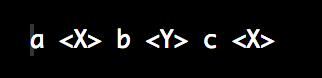
„Aha!“ I thought, now I understood😀
Garbage analysis
Only after I had gained understanding could I really assess the level of dirtiness the code represented.
Sure, it was legacy code because it lacked tests. But that was easy to fix now. And Robert C. Martin should have done that before starting to refactor, I guess.
But since I’m no Java buff I first translated the code to C#, then I added a simple „acceptance test“:

At first I did not make any changes beyond the necessary to get it run under C#. But then when it was „secured“ I looked closer. What was wrong with the class?
Robert C. Martin was hinting at a violation of the SRP:
For years authors and consultants (like me) have been telling us that functions should do one thing. They should do it well. They should do it only. The question is: What the hell does “one thing” mean? […] Of course the words “It also…” [in ‚It also makes sure that it doesn’t replace a name more than once.'] pretty much proves that this function does more than one thing.
Unfortunately I still was at a loss. As the tests showed, replace() clearly replaced each placeholder more than once. Both „$X“ were replaced by the corresponding symbol.
But upon further analysis of the logic I saw that there was an alreadyReplaced list to record the placeholders already replaced by their respective symbols. That’s probably what he meant: there was not just replacing going on but a certain kind of replacing. And also (!) there was finding going on, finding of placeholders.
That the overall replacing actually consisted of two activities - finding and a special kind of replacing - was not obvious. Good point!
But besides this and the lack of automated tests I found something else more severe: the application of object-orientation.
What in all the world was an instance class necessary fore in this case? Why introduce a global variable (stringToReplace)? Why make alreadyReplaced a global variable?
My only explanation for that was, Robert C. Martin must have found the code like this in some legacy code base. I don’t want to think he thought it was a good result of OO principle application.
On the other hand the one thing that might warrant the use of an instance class wasn’t anywhere to be found: getSymbol. Clearly the code depended on it, but it was not part of the code. Why not treat it as a strategy and get it injected?
Refactor to injection
That’s the first thing I tried: I refactored the code to a more adequate use of OO features - at least in my view:
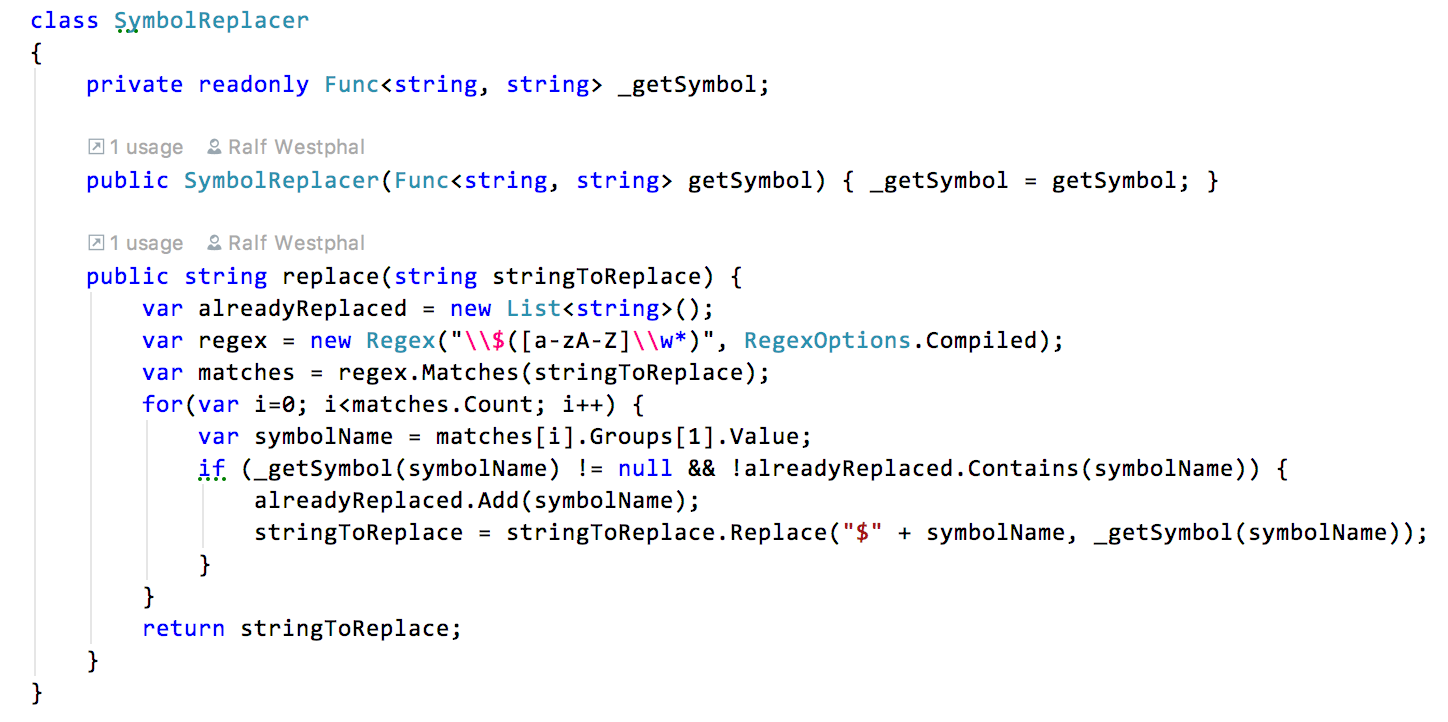
All the logic is now gathered in replace(). No mysterious translate() anymore, and no more global variables. Instead just a pointer to a function doing the symbol lookup. (Use an interface instead if you don’t like typed function pointers.)
A single SymbolReplacer object now can process several source strings, given that the relevant symbol set is the same.
The single responsibility of the class that way is easier to call upon, I’d say.
Yes, I think the responsibility of the class is pretty single. The class is conforming to the SRP.
But what about the method replace()?
It’s about decisions and insights
The remaining method is not long. I sympathize with John Ousterhout when he writes
This might be the crux of my disagreement with Uncle Bob. To me, "do one thing" refers to the abstraction visible to callers: the method appears to have a single "tight" function (something that can be described and understood very simply). The original code meets this definition.
in a Google group focused on his book „A Philosophy of Software Design“.
Does it really need refactoring?
Well, maybe not for practical purposes. Not anymore, at least, if there is at least a test making the purpose tangible and spanning a safety net for changes, might they become necessary.
But since Robert C. Martin’s article was an educational one trying to elucidate his understanding of a principle why not be a bit more sensitive?
So, yes, I too think there is room for improvement. But what are the different „things“ assembled under the roof of replace()?
„Extract till you drop“ is a very formal recommendation. It sets a form goal, it‘s about code shape. But the SRP is about content, purpose. „Form follows function“ is valid here too, I guess.
To me there are two aspects important for clean code:
- Is the code understandable (easy to reason about)?
- Is the logic easy to test?
Understandability and testability is what I’m looking for.
Understandability is high when I can easily understand what the code is trying to achieve and how it’s trying to accomplish that.
Testability is high when I can pick a piece of code, especially logic, and easily can apply a test to it.
In example case I can easily see that some replacement is to be achieved. There is an aptly named method telling me that: replace(). But how is replacement done? To understand I cannot just „read a story“. A name (like a headline) is telling a story. That’s why good names are so important. replace() is good enough for me here in conjunction with the class name.
But logic, i.e. the content of the above refactored replace() method, is not telling a story. I need to simulate its execution, I need to interpret it. How easy that is depends on its size, the control structures, the conditions, its levels of abstractions.
The size is small in this case. But there are control structures, and even a regular expression. One man’s relief is another man’s burden: that’s what I keep seeing when it comes to language features/technologies like regular expressions, lambda functions, Linq expressions in C# (or Streams in Java) etc. Even just 8 lines of logic thus might not be that easy to understand.
But how to improve that? Extracting methods is one way to do it. That’s what Robert C. Martin is suggesting. And I agree wholeheartedly! But the question remains: What’s to go into a function? How many functions are enough?
„Extract till you drop“ to me is not sensible advice. It focuses on the form.
Rather the focus should be on content, on function, on a problem/solution aspect which can clearly be distinguished.
But what is an aspect of a problem/solution?
I have found, that good guidance is given by two questions:
- Which design decisions are encoded in the logic?
- What insights flashed up in my head when I studied the logic?
Two questions plus a bonus question: What’s the basic flow the transformational logic is standing for? What are the processing steps?
Let’s apply these criteria to the example:
- A major decision (in relation to this tiny scope) is the use of regular expressions. The purpose: compiling the symbol placeholders in the source text.
- Another decision is to use a certain approach to replacing placeholders, i.e. to use the
String.Replace()function. - And an insight it was (for Robert C. Martin) that replacement is done in a special manner: „just once“.
- And it should not be forgotten, that also the format of a placeholder in the source text is a decision; it’s
"$" <Identifier>. - Also how placeholders are translated into symbols is a matter of its own with several pertaining decisions. But the code already encapsulates all those details in a special method
getSymbol(). Or you could say, the decision is to have a translation of symbol names to symbols at all.
In my experience it greatly helps understandability and testability to wrap decisions and insights into distinct functions. That would mean:
- A function to compile the placeholders to replace.
- A function to actually replace placeholders with their symbols.
Or to encode them in a data structure. That could mean:
- A data structure to represent the „just once“ insight.
And what about the placeholder format?
Have a look at the refactoring to decisions and insights I’m suggesting:

The first thing to jump out should be the simplicity of replace(): it’s just 2 lines of code telling a story by calling two well named functions. That’s the process of how the overall transformation is done.
The single responsibility of replace() now is to just integrate both functions into a larger whole. The partial and complementary functionality is put together to form the overall functionality.
Both functions represent a decision from above. And one can be even static which makes it easier to test, if need be. (Should you not like the use of Linq for replacing, then you could just put in whatever looping construct you find easier to understand. The beauty of the refactoring is, that the decision pro Linq is encapsulated in its own function.)
How about the „just once“ insight? It’s represented by the Dictionary<string,string> (or hash map) data structure. It ensures each placeholder is recorded only once - with its symbol.
Compile_symbols() also is the only place where the placeholder syntax is encoded. I did not extract it into a data structure or function of its own but rather limited the knowledge about it to a small(er) scope.
Do it again, Sam?
What’s a decision or insight? Does it have a structure, i.e. consist of nested decisions and insights?
One man’s atom is another man’s structure. So, yes, maybe after some more contemplation I would feel better by extracting the „just once“ insight also into a method and not let that know about the structure of a placeholder.
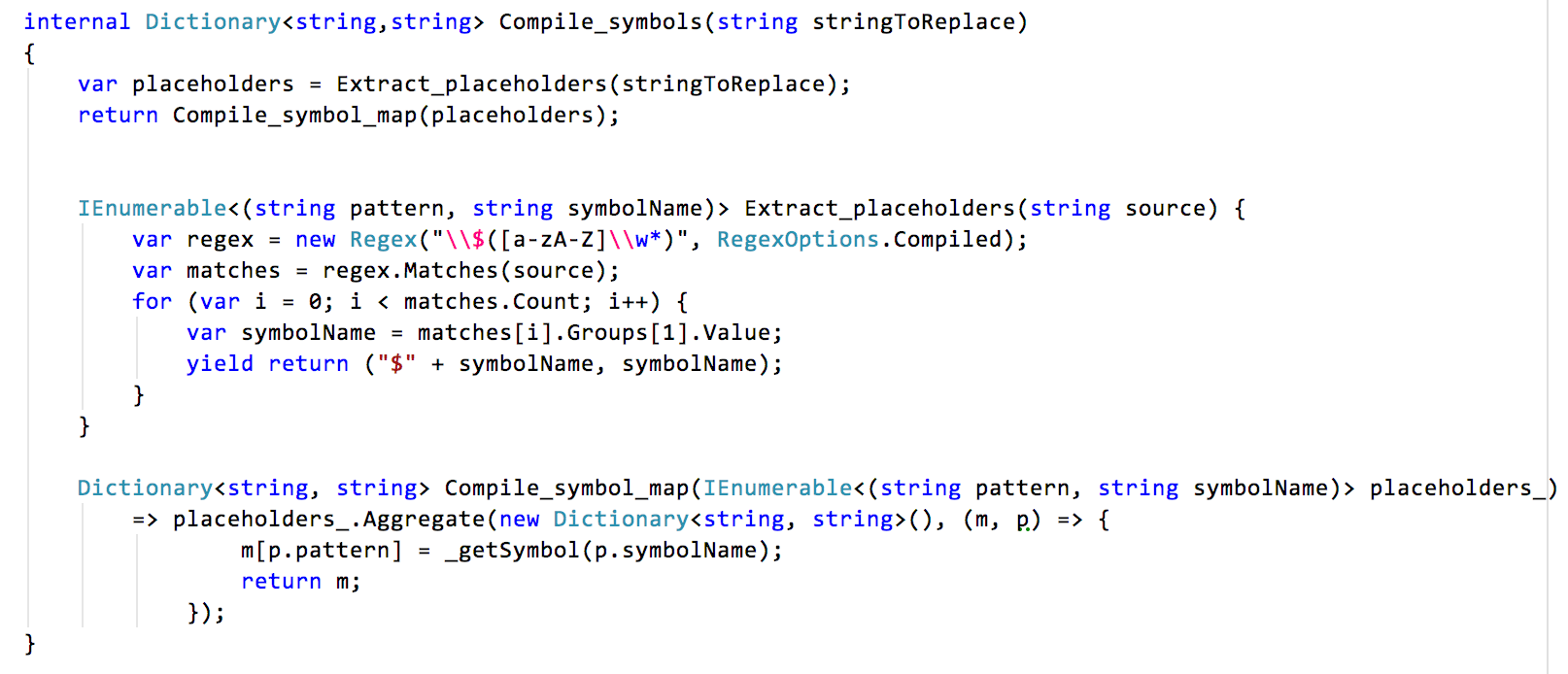
In this case I’m using (C#’s) local functions, though, to make clear that to me this is not that a big deal.
But still, as you can see, there could be another two step process to describe how Compile_symbols() is accomplishing its task.
And there is another data structure: a tuple hiding how a placeholder is structured (pattern) and what the symbol name in a pattern is. And an even smaller method now knows about the placeholder syntax (Extract_placeholders()).
This refactoring to me is optional in this case, however. I don’t need to drop while extracting.😉
Extraction: depth vs breadth
That said let’s take a quick look at the different results of „massive extraction“ Robert C. Martin and I got.

Can you spot the fundamental difference? It’s not the difference in the number of functions. That’s only a secondary effect. The primary difference I see is that understanding Robert C. Martin’s code requires you to traverse the function call tree depth first (left hierarchy). Whereas my intention always is to make it understandable by traversing it breadth first.
Can you get an idea of how a function does its job by reading only the names of the functions it calls?
- Try it with
replace()on the left side:replace()is done by… doingreplaceAllSymbols()? What does that mean? What’s the difference between the two functions? Is there something missing? Interestingly, no. - Try it with
replaceAllSymbols(): that’s accomplished doingnextSymbol()andreplaceAllInstances()? How does that fit together? Is there something missing? Yes, a loop is missing.
Now the right side:
replace()is accomplished byCompile_symbols()and thenReplace_symbol_names(). Nothing is missing - except for the data this is working on.Compile_symbols()is processing data byExtract_placeholders()and thenCompile_symbol_map(). Again, the only thing missing is the data this is working on.
Also please note, on the right side getSymbol() is only called once.
On the left side processes are spread across the depth of the function call tree. Whereas on the right side they are kept together inside an integrating function.
The solution on the right can be read on different levels of abstraction. Each level is complete in that the full behavior is realized by calling the functions in that order. I use the Unix | symbol to suggest data flowing from one function to another:
replace()Compile_symbols() | Replace_symbol_names()Extract_placeholders() | Compile_symbol_map() | Replace_symbol_names()
I call that a stratified design.
This is in stark contrast to Robert C. Martin’s approach:
replace()replaceAllSymbols()- there is no gain in calling just one function. How is this on a different level of abstraction thanreplace()? There is not even any logic missing.nextSymbol() | replaceAllInstances()- this does not work, since logic is missing;nextSymbol()is not on the same level of abstraction asreplaceAllInstances().replaceAllSymbols()thus violates the SLA.- It’s becoming worse going further down the function call tree.
Summary
Extraction of functions till you drop is not necessary to clean up your code, it might even be harmful. It focuses to much on the form.
Rather the question is: Which meaningful units of code should be wrapped into functions? To me that’s decisions (and insights).
I could thus rephrase the SRP as:
Each function or module should represent only one decision on its level of abstraction.
A decision is always present if something could be done in a different way. Whether you know what this other way could possibly be or not is of not much importance, though. That’s why in the above definition the term „insight“ is missing. Insights also are concerned with decisions. When you gain an insight you think: „Ah, it’s this way (and not another way)!“
I still like the term „insight“, though. Because it fits the situation better when studying code. Decisions are more of a thing when designing/implementing code.
P.S. I like semi-functions
One word about the functions which got extracted in my approach and in Robert C. Martin’s. Roman Leventov calls them „semi-functions“ because the are only used once. They are lacking re-use - which seems to be the purpose of functions for many developers.
But I don’t mind such functions. In fact I like them very much. Because to me functions are not primarily about re-use. They might have been for a long time due to memory scarcity. But those times are gone.
Trying to avoid duplication (application of DRY) is different from looking for opportunities to re-use. Re-use is about productivity: you want to avoid writing code. DRY is about consistency: you want to avoid bugs.
Both are valid reasons for extracting (or designing) functions. To me there are - not surprisingly - yet two others, though: understandability and testability.
I extract (or design) a function for the sole purpose of making the calling one easier to understand. See my code above for that. Whether the extracted function then is only called once or in several places, I don’t care. I’m content with its signature hiding details and telling me a part of a story where it’s used.
Or I extract (or design) a function even if it’s going to be called just once for the purpose of making its contents easier to test. I don’t want them to be buried somewhere in some other function.