Eventual Consistency for Mere Mortals
Developers shun it, if they can: Eventual Consistency (EC). Rather they jump through hoops and invest huge efforts and drive technologies through all sorts of contortions to avoid even small areas of EC in their applications.
What developers love is Immediate Consistency (IC). That’s what RDBMS are promising with their ACID transactions. Developers don’t want to give inconsistency any room (or better: time). Only Permanent Consistency is good enough for them. Yeah, sure, it matches the zeitgeist: PC ;-)
IC is easy to reason about, EC is hard. IC you can delegate to technologies. But with EC you have to take care of inconsistencies yourself, should they occurr.
I guess, in the end it’s a matter of blame: With IC you can blame technology for inconsistencies; with EC, though, the blame is not that easily deflected.
Plus, since developers are animals of possibility rather than probability they fear EC for all that could possibly go wrong, all the possible inconsistent states they would need to anticipate and take care of.
Only grudgingly they accept the CAP theorem which states that IC is not for free. You’re paying a price which increasingly becomes visible in growing and distributed systems.
I really empathize with this view. EC seems scary. Do I really have to deal with it? Can’t I keep using technologies which assure me IC without much effort?
Sure, I can. But that would limit me to certain applications. And, I think, it also limits the evolvability of even smaller applications. Because as soon as you consider Event Sourcing as the foundation of your software system, then you have to deal with EC, I’d say.
Yes, I think Event Sourcing helps evolvability at lot. You can be a SOLID developer, you can be a fan of Clean Architecture and what not, but unless you give up the notion of a central static domain data model you’re still living in a cage. Your flexibility is limited by a dominant structure in memory and/or on disk. Where there is a single domain data model at the core of an application, there are innumerable dependencies on it, which require it to be very stable.
Stability is good in some places, e.g. contracts; that’s the purpose of contracts as abstractions. But a domain data model - in my experience - is a bad place to demand stability. How domain data is structured is under constant pressure because it’s a mirror of your understanding of the domain - which is in permanent evolution due to new requirements plus more encounters with domain experts. New features, new use cases, new software system clients put ever changing demands on how data should be represented and presented to them.
If you want to respond to all this volatility you need fine grained data you can knead into very different shapes at short notice. Event Sourcing is providing exactly that. And with a Food Truck Architecture you’re exploiting this potential.
However… you have to become comfortable with EC. That’s the price of evolvability for high longterm productivity which you need to stay relaxed in software business.
But maybe EC isn’t that evil? I was a big believer in „ACID forever!“ ;-) Since then a lot of things have changed, though. And now I want to no longer fear EC, but embrace it. Because it has so much potential - and is so natural.
Eventual consistency is everywhere
Even though a developer’s fear of EC is understandable, I think it’s misguided. It’s misguided because it denies the very nature of the world. IC is an illusion. There is no IC in nature. The reason is simple: the speed with which information can travel is ultimately limited to the speed of light.
The notion of IC is man-made. It’s an artificial constraint which might make things better in the short term or in the small - but in the end it’s limiting and hard to keep up.
I saw a cartoon trying to explain EC in a tweet by Greg Young:

I liked it - however I find it pretty intellectual and thus not really helpful for overcoming „EC anxiety“ ;-)
EC is not that complicated to understand. Let me try to explain…
What is consistency in the first place?
According to the free dictionary consistency is:
Agreement or logical coherence among things or parts [and/or] correspondence among related aspects; compatibility
That means: Consistency is a matter of two (or more things) where the properties of one thing depend on properties of the other thing. How the properties here and there are related is a matter of some consistency criteria.
Take for example two shapes which should be of the same color:

Both pairs show consistency with regard to the criteria „being of same color“. But not the following ones:

The colors are inconsistent. The coloring of the shapes does not follow the consistency rule.
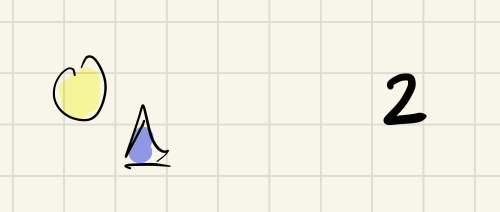
The things to be consistent and the consistency criteria can be of all different kinds. Here’s another example:
- a list of things
- a number
Consistency criteria: „the number should always be equal to the number of things in the list.“
Here things are consistent:
But not here:
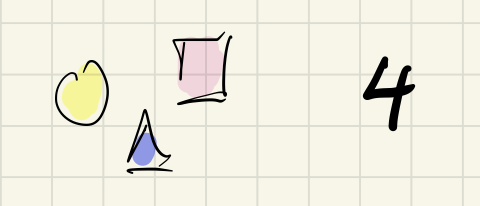
Consistency is in the eye of the beholder
Consistency might seem to be „in the things themselves“, but it’s not. Consistency is not a physical property, but a logical one. It thus requires an observer. Somebody must analyze a scene and interpret the observations according to the consistency rule. Consistency is of no matter as long as nobody is looking.
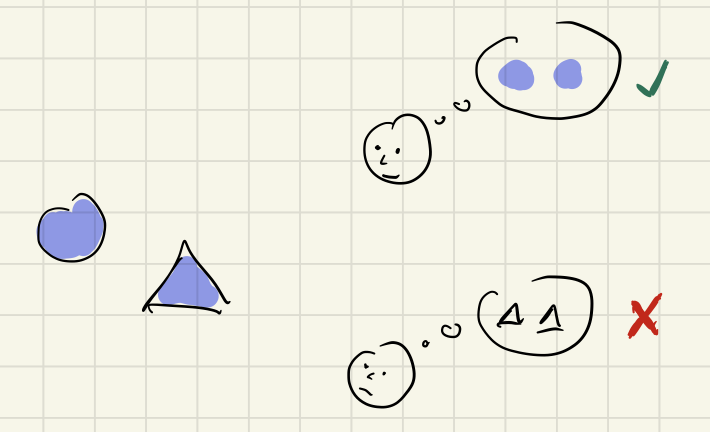
Two observers can look at the same things and both come to different conclusions regarding their consistency. It depends on the criteria each observer applies.
Evolving consistency
Where there is an observer there is time. Because observation takes time, even if it’s only a micro-second.
Take this scene from above for example:

In this trivial case your consistency judgement happens unconsciously and very quickly, you barely notice the passage of time. Your impression is, you „immediately“ (or „at a glance“) see the consistency of the shapes.
But when you look very, very closely, you’ll realize it nevertheless takes a bit of time:
- You look at the left shape
- You look at the right shape
- You compare your observations in your head and apply the consistency criteria
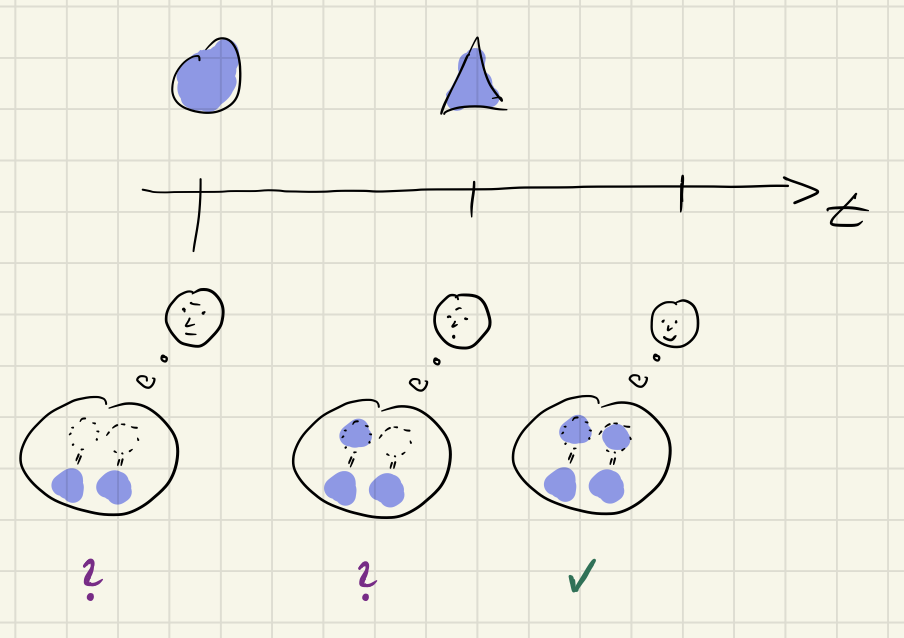
This is what happens „at the moment“ (which not really is just a single moment or point in time) when you look at things to check their consistency.
Now, let’s zoom out. Look at the same things at different moments:
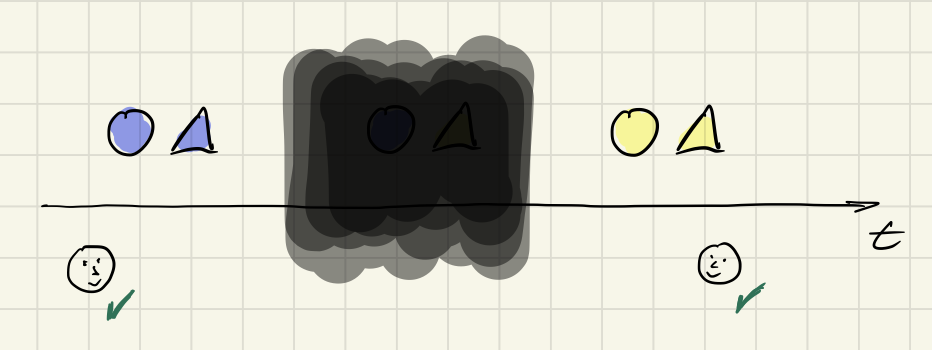
The blacked out period is a time where you did not look. You attention was elsewhere. Or maybe you just gave in to the urge to blink.
The shapes are consistent when you first looked at them and also when you looked at them again later. But between those points in time they have changed. The shapes evolved consistently.
That’s good, isn’t it. That’s what developers want. They like things to be changeable, but they also want things to always be consistent. Take a database for example:
- A record in an customer table
- A record in an invoice table with a reference to a record in the customer table. There reference is the customer name. (Yeah, I know, bad idea. But let’s go with it because it’s easy to understand.)
Consistency criteria: „An invoice record always needs to have a matching record in the customer table.“
Simple operations then would be:
- You add a customer with name „Wayne“.
- You add an invoice and reference the new customer by her name „Wayne“.
- You delete an invoice for another customer named „Kent“.
But what if customer „Wayne“ changed her name to „Flynn“ because she’s gotten married? Her name is in use in two places: in her customer record and in her invoice.
Right now there is an inconsistency between the customer as a person and here records in the database.😱 Yes, inconsistencies happen in the real world!
To correct this, the database has to be adjusted. But how? Changing the name first in the customer record would create an inconsistency with the invoice; the invoice would get orphaned. Changing the name first in the invoice, though, would also create an inconsistency.
Either way, doing both changes sequentially would lead to a (short) period of inconsistency:
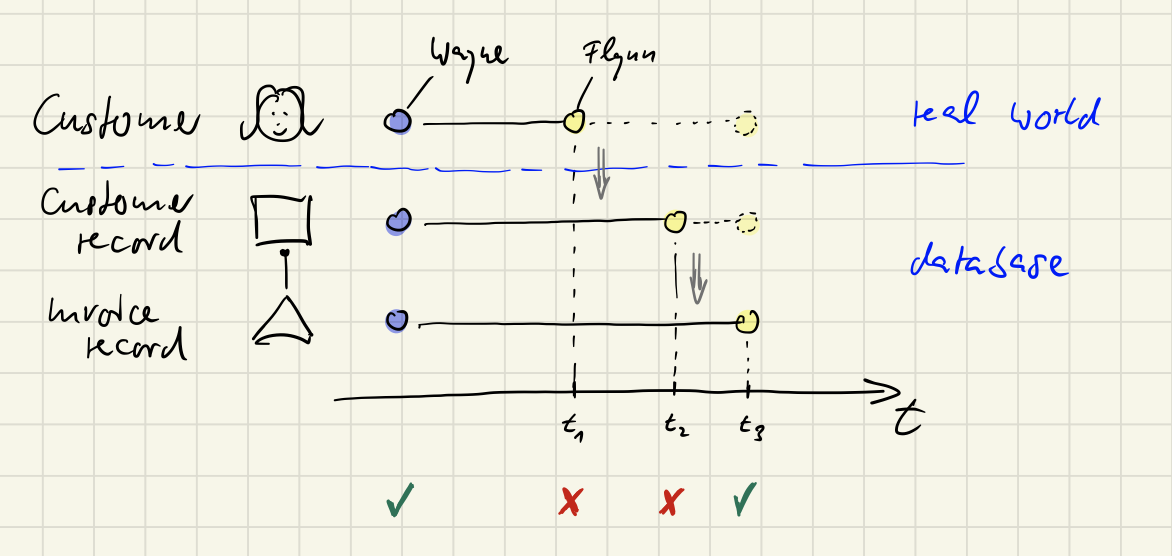
That’s where ACID transactions come in. With such a transaction both changes would still be done sequentially - but for an observer there would be no period of inconsistency. Afterwards either both records contain the new name „Flynn“ (success) or still the name „Wayne“ (failure).
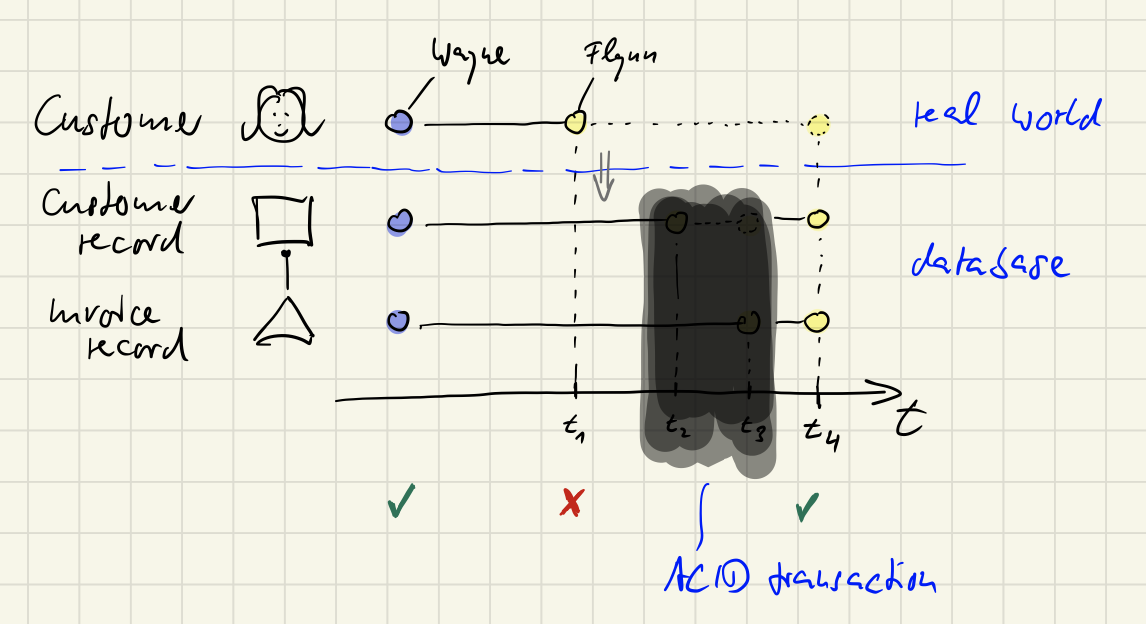
Keeping-up consistency always takes time. It takes time and it’s a matter of the observer.
So, please note: Even though the database is now guaranteed to always be in a consistent state due to ACID transactions the overall system, the world including the customer and the database, still only is eventually consistent. When the customer is getting married and signs the marital contract with the change of her name this information is not automatically or immediately sent to the company keeping the records in a database. Until the customer notifies the company the world is inconsistent. And it might be for quite some time, maybe years or forever. Is that bad? Is eventual consistency bad? No. Or more precisely: It just depends on the observer.
For a sales person inside the company looking at both records all’s well even though the customer already has changed her name. It’s well because the sales person does not know about the name change and does not care as long as he’s interested in monthly revenues. Things would change, however, should the sales person send out some sales brochure via snail mail with the now unknowingly wrong name – and the brochure cannot be delivered because the name on the customer’s post box has been already updated.
Eventual consistency can only be masked
As you might have realized: eventual consistency is everywhere. It cannot be avoided, it can only be masked or hidden.
- The customer’s real name and the name in the database were inconsistent for some time - until someone started the ACID transaction to change her name in the database.
- The customer’s name in her record and in the invoice record where inconsistent for some time - until the second record also was changed.
The physical inertia of objects in the real world is mirrored by an informational inertia of data structures in software at runtime. Information takes time to travel from one place to another: from customer to company, from one record to the other.
When you look at the colored shapes of the above example again and „don’t blink“, you can see how it takes time to switch them from one consistent state into another:
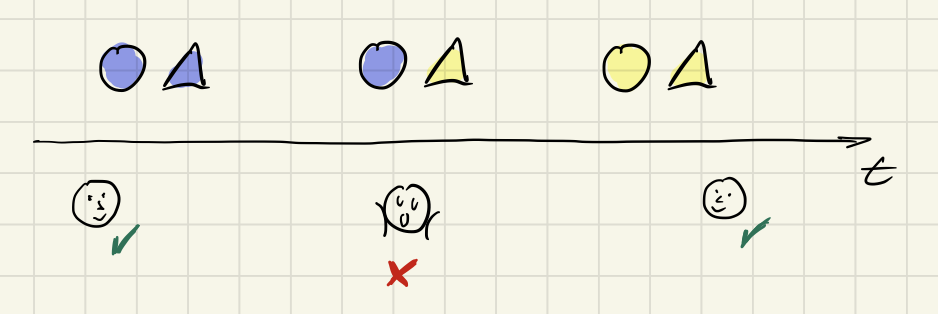
However, for some reason software development has decided it does not want to deal with this if possible by any means. Software development does not want to suffer from EC. Mere mortal developers should be shielded from such complexity of life. And this attitude worked. For a long time. For so long, even, that many have settled on the belief that IC is the natural state of the world or at least of data management inside of programs.
But it’s an illusion. IC is an illusion with a growing price tag. And the price is paid as a loss in evolvability and a decrease in productivity.
What are your consistency requirements?
EC literally is ubiquitous. So ubiquitous that you probably don’t even realize it most of the time and don’t bother. You just accept it as a part of life and have developed ways to deal with it. You’ve developed nuanced context dependent inconsistency tolerance even in the typically quite sensitive area of personal finances.
Exhibit 1: Amazon purchase. Occasionally I buy a used book via Amazon from some second hand book store in the US. During the order process it’s perfectly fine for me to already pay for the book - even though it might take weeks until it’s delivered to me by postal mail.
This creates an inconsistency between my bank account and my book shelf. The consistency rule is: „The total value of books on my shelf and money in my account stays the same.“ (For the moment I’m neglecting any other purchases, shipping fees, or any money I earn.) The books on my shelf currently might be worth some 5.000€ and on my bank account there might be 2.000€, which is a total value of 7.000€.
When I order a book from the US costing 30€ amazon gets that money immediately leaving me with just 1.970€ in my bank account and no increase in value of my book shelf. Then, maybe three weeks later, when the book arrives and I put it on my shelf the value of my shelf increases to 5.030€.
Eventually consistency got restored: 1.970€+5.030€=7.000€. But for three weeks I was forced to live with inconsistency. Was that painful? No. That’s perfectly normal.
Exhibit 2: The same is happening every day at the supermarket. Whenever you get your purchase totalled at the cash register and pay, there are maybe 20 seconds of inconsistency. This time it’s the vendor suffering it: You already have the purchase stowed away in your bag, but you haven’t paid yet. The supermarket has lost value to you but hasn’t received the money for it; you have received value, but also still have your money.
Eventually the transaction will be finished and everybody is happy. But there is a 20 second window of uncertainty and inconsistency… Is that bad? No. That’s perfectly normal.
These situations of eventual consistency are so normal we don’t even think about them. Consistency might even seem to be immediate - but it’s not. And we don’t really care.
So, why do we care so much in software development?
My guess is, because often times we don’t really think things through. And we take the illusion of IC for granted while running a synchronous monolith talking to an RDBMS with ACID transactions.
And that’s fine - as long as we don’t complain about hard to change growing webs of data.
What would it mean to think consistency needs through? If we could gain more evolvability by making our data more malleable, but the price was EC, maybe it would still be worthwhile.
Consistency is a matter of latency
Think about the supermarket checkout scenario: Why doesn’t the supermarket care about the temporary inconsistency? Because it’s short lived. Eventual consistency takes only some 20 seconds.
To create consistency always takes time. Look at this image again:
The latency between t2 and t3 is what matters to software developers; the latency between t1 and t2 might be of concern for the sales department. The bigger it is, the more you’re concerned. But for every EC scenario in the real world you have an idea of what’s an acceptable latency and what not.
For the Amazon purchase I’m fine with a couple of weeks or even months if the book price is below maybe 100€. But for an item costing 500€ I would not want to wait for more than a couple of days or so, if I had to pay for it in advance.
The supermarket is fine with 20 seconds of inconsistency, but it would not be that happy, if you wanted to start a tab and only pay every couple of months.
What makes latency relevant in these cases is trust. Does an observer trust the spreading of consistency to eventually finish reliably?
If the supermarket trusted its customers more, it could accept a higher latency and offer a tab to write up purchases. If I trusted the seller of an item more I would be fine with paying 500€ or more in advance.
And trust - or the lack of it - is what makes developer cringe with regard to EC. They think about all that could possibly go wrong while consistency is spreading; and should something happen then they’d have to deal with an inconsistent state. Of course the higher the latency the higher the risk that something goes wrong. No, thank you!
Consistency is a matter of frequency
But maybe trust is warranted. Maybe things don’t go wrong while consistency ripples through a system even if it takes a while.
In some situations that’s all what’s needed. But in others it’s not. Take the supermarket as an example again:
The supermarket trusts all its customers and allows them to pay later. The immediate gain is a speedier checkout which means more throughput for the cash registers. Great! Take away: Trust is speed!
The downside to this, though, would be less money in the bank for a longer while. Maybe the supermarket only bills its customers every month. That means it’s lacking the money for all the purchases during that period. In effect it’s granting its customers a loan.
That money is not available for buying new goods to sell.
Trust is not the only thing needed to allow EC. What’s also needed is availability. Consistency is a property that needs to be available at certain times. The question is: when?
What’s the frequency of consistency checks? If consistency is checked only once a day than a 20 second inconsistency is of no concern. At the end of the day the money in the cash register and the sold goods are balanced out.
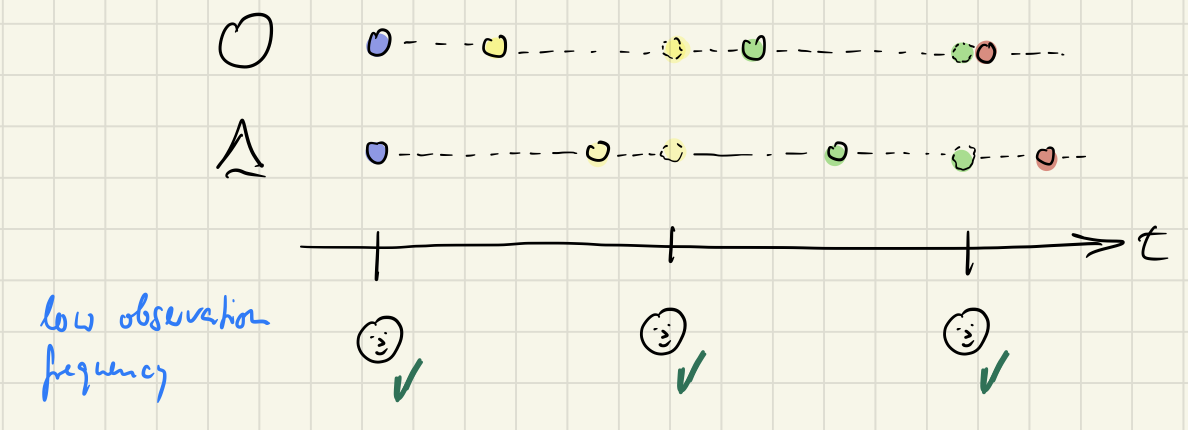
But if customers may pay at the end of the month and consistency is checked every day or even every week then inconsistency would be noted. Not good! In this case it would manifest itself in the form of lack of money for buying new goods.
If the observation frequency is so high that it’s likely for an observation to fall right between two consistent states, the observer will see inconsistency. That means: lower frequency and lower latency means less inconsistencies to stumble across.
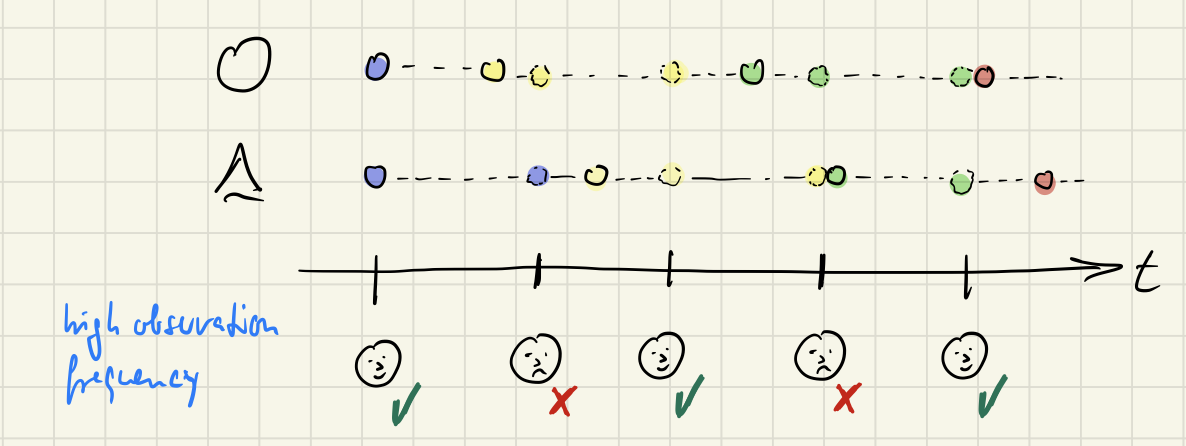
That’s what’s bothering developers, too. Even if they’d manage to spread consistency reliably, they fear they’d observe inconsistent states in between. They fear there could be an observer checking up on some data while it’s in the process of switching from one consistent state to another. That’s what the the sad faces in the previous image stand for. Think of the customer record already having been changed, but not the invoice. During the latency period of the spreading name change it would seem there was no invoice for the customer. That must not happen, right?!
Inconsistency is a matter of probability
How long does it take to eventually establish consistency? And how often does someone look? That’s the two questions developers are faced with when evaluating the EC-option. And that’s what they don’t really want to think about and decide upon – because if they get it wrong, then it’s gonna be their fault when inconsistencies show up. Better to not think about it and use some synchronous way of applying changes or better even ACID transactions.
Maybe, though, just maybe it would be worthwhile pondering these questions? Because there is a prize to be won: higher longterm productivity.
In my experience developers are people who are always considering the possible and not the probable. They are like preppers: they prepare for the worst. And they like to cover their asses because blame can hit them from all sides at any time.
Let’s make thought experiment. Just for a moment let’s look closer at consistency requirements:
The mentioned company has in its database 5.000 customers with 100 invoices each on average. That makes 500.000 invoices in total. The database is growing by 50 customers every week. At the end of the year it will be 7.600 customers with some 750.000 invoices. And so on.
Now let’s assume a customer name change happens once every 100 customers. That would mean 50 name changes so far and 26 in the coming year.
With 260 working days the likelihood of one of the name changes happening on a given day is 26/260=1/10=0.1.
So much for the real world. On the technical side a name change takes 1 second on average to ripple through from customer record to all invoices. After a user presses ENTER in the name change dialog another user could open the customers invoice list one second later and see all the invoices still (or again) linked to it. (I know, nobody really would link invoices to customers by name. It’s just for the simplicity of the example.)
However, should another user open the invoice list less than a second later she might be wondering why some or all of the invoices are missing. That’s a possibility in this EC scenario without ACID transactions.
Now my question is: How probable is this?
If a name change has a probability of 0.1 per day then its probability for a certain second between 9:00 and 17:00 is 0.1x1/28.800=0,000003472=3,5x10^-6.
Hm… that’s a pretty small probability, isn’t it?
But wait, there’s more. Even if there is just a 3,5 in a million chance of a name change happening just this second with a 1000ms inconsistency window, that is only relevant if somebody was actually looking.
If the invoices of every customer were listed once every day, then that would be 7.600 per day at the end of the year with a probability of 7.600/28.800=0,26 for the invoices of a certain customer to be looked at in a certain second each day.
Now for the really interesting question: How likely is it that the invoices of the customer with a name change are actually retrieved while the name change is going on so that an inconsistency becomes visible? 0,26x3,5x10^6=0,00000091=9,1x10^-7.
Wow! That’s a small probability, isn’t it? It’s less than 1 in a million.
Think about how much you care about 1 in a million probabilities. The risk to die in a car traffic accident in Germany for example is 0,00004125=4,1x10-5 or at least 10 times higher - and still Germans drive their cars, ride bikes in car traffic, and cross a street etc.
I think you get what I mean: Just because something is possible – a temporary inconsistency - does not mean it’s probable or even relevant.
Hence the fear of EC to me largely is irrational. At least as long as no closer look has been taken at the so much feared scenarios.
Please get me right: I’m not saying consistency was not important. To the contrary! Also I’m not saying IC wasn’t helpful or even cheaper than dealing with EC sometimes.
What I’m saying is: Let’s relax and open our minds. Maybe EC could be an option (much?) more often with all its benefits, than developers dare to imagine.
What to do in case of an inconsistency?
In software development consistency is about keeping the same data in two (or more places). It might be exactly the same data or a transformation of data.
If for example customer data is kept in two locations (e.g. in a database for book keeping and in another database for sales, or on a mobile device and in an inhouse database, or in a database and on a screen), then data changes in one location will take time to travel to the other location(s). During that time an inconsistency exists.
Or if for example invoice data is aggregated into revenue reports then that will take some time. During that time there will and afterwards depending on the update frequency of the reports there might exist an inconsistency.
And one such inconsistency might spawn another: If you and me are both viewing the same invoice record we might issue two different commands: you add an item to the invoice and I delete the invoice. Without further measures this will lead to an inconsistent state in an event store. In this case inconsistency #1 is your screen not showing the new state of affairs in the event store where a deletion has been recorded; inconsistency #2 then is your changes getting stored by adding another event. (Yes, with an event store you can store change to data that have been deleted. An event reporting a deletion is independent of an event reporting an update.)
What can be done about this? What can be done about this if application state is based on Event Sourcing?
Using a versioned event store might help to thwart the inconsistency in the first place: the events of your command might arrive first in the event store, cause its version to change, and then my events won’t be recorded because I’m expecting an older version of the event store. My client would have to update its view of the persistent state first which would give it the opportunity to re-evaluate the validity of executing my command. The same would be true for your client if my events would have reached the event store first.
But this is a very broad brush approach to consistency, I’d say, albeit one which is easy to understand and is trying to nip inconsistency in the bud.
Somewhat more fine grained it would be if there wasn’t just one version number but several for subsets of data; if you like call these subsets „aggregates“. But since „aggregate“ is a somewhat contentious term I’d rather speak of „consistency horizons“.
However what if an inconsistency arises despite such low level technical counter measures? The probability for that may be very, very low, but nevertheless it might happen.
Here are a couple of different responses to inconsistencies, I see:
- Maybe the inconsistency is only temporary. Then an observer could wait a bit and look again. The inconsistency could be gone.
- Maybe the inconsistency can be resolved by the observer. The observer would issue compensating events or otherwise correct its view.
- Maybe the inconsistency cannot automatically be resolved. Then the observer should flag it and notify some authority which/who can deliver compensation.
You see, I don’t think, all’s lost just because there is some potential for noticeable inconsistencies in EC. We can deal with it on several levels – like we do in the real world.
Summary
You’re used to merge conflicts in Git; you’re of course trying to avoid them - but in the end they happen. Then somebody will resolve them manually. That’s frustrating, but inevitable, if you want to reap the benefits of Git. The possibility of inconsistencies does not drive you away from it. Accepting eventual consistency has turned out to be very useful and has „conquered the world“ of VCS.
I imagine this to become true for Event Sourcing, too. Yes, Event Sourcing requires a change of mindset; that won’t be easy for everyone. And it will lead to more situations with a potential for inconsistencies due to EC. But we can learn to accept that and deal with it constructively, because – as I believe – the benefits of Event Sourcing outweigh its drawbacks.
Maybe our approach to user interface design has to change, too? Maybe we need to let go of the certainty that pressing a command button will always lead to a consistent state immediately. Maybe we need to introduce ways for users to deal with rare inconsistencies themselves. Yes, we should not try to abstract EC away fully. Users are used to EC with regard to the real world; why not dis-illusion them about the world of software - because that will enable us to more easily evolve code for the sake of the users.
True, it’s not all roses with Eventual Consistency and Event Sourcing. But I view that as a challenge to look closer, to learn to deal with it. A paradigm change is always hard. It will take some time, it will take better technologies, and techniques and patterns. But we’ve come a long way from manually dealing with multiple threads to the actor model and abstractions like Erlang or Akka. Why not be optimistic and hope for the same to happen for Eventual Consistency and Event Sourcing? CQRS was just a start.
Let’s embrace Eventual Consistency for our benefit!
