
FeatureForecast: Sagst du schon vorher oder schätzt du noch?
Eine beim Management beliebte und bei Entwicklern gehasste Frage: „Wie lange dauert das?“ Als Antwort darauf wird dann eine absolute Schätzung erwartet, aus welcher auf die eine oder andere Weise ein Fertigstellungsdatum abgeleitet wird.
Das funktioniert so gut, wie es gut funktioniert, dass man jeden Tag zwei Packungen Zigaretten raucht und 96 Jahre alt wird: eher nicht.
In einem anderen Artikel habe ich schon dargelegt, warum ich denke, dass jeder Versuch einer Antwort darauf in der Softwareentwicklung auf Sand baut. Fragender und Antwortende unterliegen drei wesentlichen Illusionen:
- Kontrollillusion - dass man die Anforderungen unter Kontrolle hätte oder die Aufmerksamkeit über längere Zeit
- Erfahrungsillusion - dass man solide technische und fachliche Erfahrung hätte, die sich auf das Abzuschätzende übertragen ließen
- Qualitätsillusion - dass man am Ende sicher sein könnte, alle wirklich geforderten Qualitäten auch zu liefern
Dazu kommt, dass ich nur sehr selten höre, dass in Bezug auf Schätzungen eine Reflexion stattfindet. Denn wer zur Herstellung einer Schätzung auffordert, sollte am Ende auch schauen, ob deren Qualität gut war. Das bedeutet: Wo geschätzt wird, muss auch gemessen werden, wie die Realität anschließend aussieht. Kommt sie der Schätzung nahe?
Wo also keine Datenbank mit Tupeln mindestens der Art (Schätzung: 3 Tage, Aufwand: 4 Tage, Dauer: 7 Tage) entsteht, geht es nicht wirklich um professionelle Planung. Es ist nämlich kein Wille zur Verbesserung erkennbar.
Und schließlich: Schätzungen kommen immer ohne jedes Risiko daher. Wenn der eine 5 und die andere 8 und der nächste 13 sagt, was ist dann das Risiko, also die Wahrscheinlichkeit, dass die Realität nicht mit der Schätzung übereinstimmt? Ist die Wahrscheinlichkeit für die Erreichung des Mittelwerts 8,67 50% oder 67% oder 90%?
Bauchgefühle sind eben das: Bauchgefühle. Sie sind nicht exakt und schon gar nicht mit Wahrscheinlichkeiten versehen.
Schlechtes Glücksspiel
Entscheidungen auf der Basis von Bauchgefühlen sind damit nicht einmal mehr Glücksspiele. Denn bei Glücksspielen wie Roulette sind wenigstens die Wahrscheinlichkeiten bekannt. Nach Tagesform oder Persönlichkeit kann man ganz bewusst auf hohes Risiko oder niedriges Risiko setzen - und weiß gleichzeitig, dass auf lange Sicht „die Bank“ immer gewinnt.
Doch selbst in dieser eigentlich rationalen Situation droht schon die Sucht, die Spielsucht.
Schlimmer ist es in der Softwareentwicklung. Das beliebte Schätzspiel kommt ohne Wahrscheinlichkeiten für Risiken daher. Und was macht die Softwareentwicklung: Sie setzt einfach blind nach Bauchgefühl. Wahnsinn, oder?
Überlege einmal, was du tun würdest, wenn du in einem Casino an einem Tisch mit einem dir unbekannten Glücksspiel stehen würdest. Das Spiel läuft, du darfst teilnehmen, es gibt unterschiedliche Optionen, auf die du setzen kannst, der Gewinn ist allerdings immer gleich: du bekommst das Doppelte deines Einsatzes zurück. Leider ist da aber niemand, der dir die Regeln erklärt. Was machst du?
Du beobachtest. Du führst ein Protokoll der Häufigkeit, wie die Optionen gewinnen. Dann berechnest du die Wahrscheinlichkeiten, mit denen die Optionen eintreten. Und erst dann entscheidest du, auf welche Optionen du setzt.
Das wäre rationales Verhalten.
Doch so agiert die Softwareentwicklung nicht. Sie setzt blind. Ohne Risikobewusstsein. In einer merkwürdigen Melange aus Misstrauen und Naivität.
Misstrauisch ist die Softwareentwicklung, wenn eine Entwicklerin sagt, sie könne nicht angeben, wie lange sie für die Umsetzung einer User Story brauche. „Das musst du doch wissen, du bist Entwicklerin!“ ist dann der erstaunte Ausruf hinter dem der misstrauische Gedanke steht, dass da jemand sich einfach nur keinen Stress machen will.
Naiv ist die Softwareentwicklung, wenn sie anschließend mit ein wenig „Nachhilfe“ die Aussage bekommt „Naja, ich glaube, das kann ich in 2 Tagen schaffen.“, sich daraus das Ergebnisversprechen schnitzt, „Ok, dann ist es also übermorgen um 15:00 Uhr fertig. Das sage ich dem Kunden.“ und auch noch glaubt, dass das 100% eingehalten würde in punkto Zeit und mit aller langfristig notwendiger Qualität.
Sorry to say: Das ist kein Glücksspiel, das ist schlicht Dummheit. Vielleicht noch gut gemeinte oder verzweifelte, aber dennoch Dummheit.
Aber ich will mich gar nicht mehr aufregen. Lieber helfe ich, die Situation zu verbessern.
Einen ersten konkreten Vorschlag habe ich mit dem vergleichenden Schätzen über Totalordnungen gemacht. Dabei kommt zwar auch keine Risikowahrscheinlichkeit heraus, aber es sind auch keine absoluten Schätzwerte mehr im Spiel und also auch keine Ergebnisversprechen.
Mein zweiter konkreter Vorschlag lautet nun:
Vorhersagen statt schätzen
Beim Schätzen wird eine absolute Zahl aus der Luft gegriffen. Es gibt keine Idee, vorher die kommt, warum sie bei verschiedenen Leuten verschieden ausfällt oder inwiefern sie risikobehaftet ist.
Vorhersagen hingegen basiert auf realen Zahlen. Bei denen ist klar, woher sie kommen, worauf sie sich beziehen und es gibt es klare Risikoaussage.
Vorhersagen funktioniert so:
- Es werden ständig reale Werte gemessen. Was immer man später vorhersagen will, das muss man erstmal messen, sei das Wert in Relation zu User Stories oder vor allem natürlich Aufwand oder Dauer. Wenn man in dieser Weise schließlich eine Datenbasis von reale Werten angehäuft hat (ich nenne sie historische Daten), dann und erst dann kann man Vorhersagen berechnen lassen.
- Man stellt eine Menge von User Stories zusammen und holt exemplarisch dazu vergleichbare Daten aus der Historie. Wenn man das viele Male zufällig tut (Monte Carlo Simulation), dann entsteht eine Wahrscheinlichkeitsverteilung von möglichen Verläufen der Entwicklung. Das ist die Vorhersage, in der die Daten mit einem Risiko versehen sind.
In zwei Artikeln (hier und hier) habe ich darüber schon ausführlich geschrieben - konnte allerdings noch kein Unterstützungsangebot machen. Das ist jetzt anders.
Wie du historische Daten sammelst in deinem Projekt, ist dir überlassen. Benutze ein digitales Werkzeug wie Toggl oder mache das auf Papier und sammle die Daten in Excel. Egal. Am Ende solltest du eine lange Liste von kategorisierten Werten haben.
Jeder Wert besteht aus einer Zahl (z.B. für den Aufwand, der tatsächlich in eine User Story geflossen ist) und einer oder mehreren Kategorien. Ist der Wert durch Arbeit an einem Bug oder an einer Erweiterung entstanden? Ging es um Arbeit im Frontend oder im Backend oder im ganzen Durchstich? Haben Peter, Paul oder Maria daran gearbeitet? Du entscheidest, was für Kategorien du protokollierst.
Am Ende gilt: Vorhersagen können nur so genau sein, wie die Kategorien, die du in den historischen Werten zugeordnet hast.
Wenn du eine Aufwandsvorhersage mit einer Wettervorhersage vergleichst, dann entsprechen die Kategorien vielleicht der Jahreszeit oder der Weltgegend, um die es geht. „Wie wird das Wetter in Hamburg im Juni wohl aussehen?“ ist mit Breitengrad und Monat so „kategorisiert“, dass man auf der Basis von historischen Daten dazu eine Vorhersage machen kann. Schau dir als Beispiel eine Klimaübersicht für Hamburg an.
Dasselbe ist für die Softwareentwicklung auch möglich. Wenn du kategorisierte historische Daten hast, dann benutzt du einfach die Web-App FeatureForecast, die ich mit Kollege Florian Böhmak entwickelt habe.
Schau dir das Video an, das dir in 2,5 Minuten demonstriert, wie es geht:
- Du erfasst die Historie deiner Werte entweder einzeln oder en bloc.
- Du erfasst die vor dir liegenden User Stories in der Menge, wie sie bestimmten Kategorien angehören.
- FeatureForecast berechnet daraus eine Vorhersage mit Wahrscheinlichkeiten für ihren Eintritt. Dafür simuliert FeatureForecast 1000 unterschiedliche „Projektverläufe“ auf der Basis deiner historischen Daten (Monte Carlo Simulation).
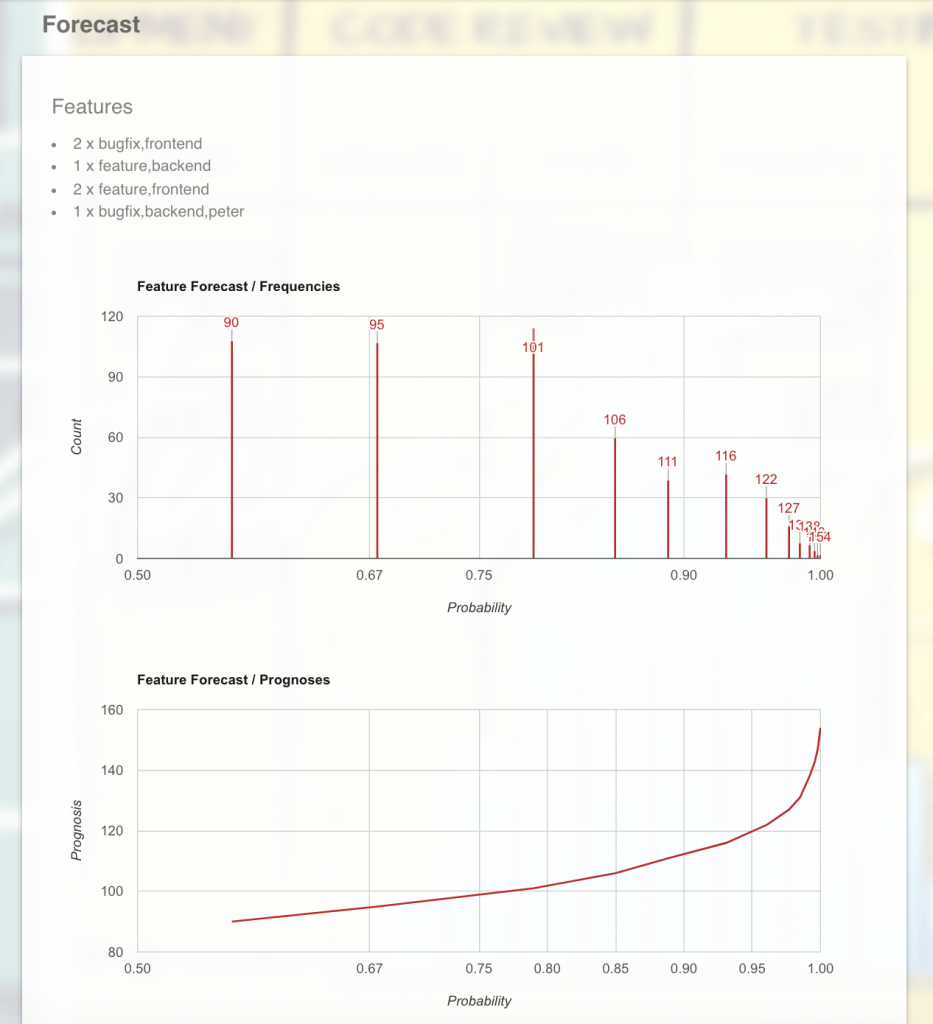
Oben siehst du das „geplante Projekt“ mit seinen kategorisierten Features, darunter die Vorhersage.
Zuerst die Verteilung der Vorhersageergebnisse. Beispielsweise tauchte das Ergebnis 95 ca. 110 Mal (Y-Achse) in den 1000 Simulationen auf, das Ergebnis 122 jedoch nur 30 Mal.
Wie wahrscheinlich das „Projekt“ nun mit einem Ergebnis abgeschlossen werden kann, zeigt die X-Achse. Dass das Ergebnis 95 erreicht wird, hat eine Wahrscheinlichkeit von 0,67 (oder 67%). Dass es aber mit 122 geschafft wird, hat eine Wahrscheinlichkeit von 0,95 (oder 95%).
Umgekehrt liegt das Risiko - also die Wahrscheinlichkeit, dass ein Ergebnis nicht eintritt - für 95 bei 33% und für 122 nur noch bei 5%.
Um ein Gefühl dafür zu bekommen, was diese Wahrscheinlichkeiten bedeuten, denke an einen Münzwurf oder das Rollen eines Würfels.
Wie verhältst du dich bei einer Kinoverabredung für 20 Uhr, wenn deine Begleitung sagt, sie würde eine Münze werfen, ob sie pünktlich da ist? Bei Kopf trifft sie pünktlich ein - bei Zahl kann es allerdings auch viel später werden. „Wie viel später?“ fragst du? Die Antwort: keine Ahnung, 5 Minuten oder 20 Minuten.
Wie verhältst du dich hingegen, wenn deine Begleitung sagt, sie würde einen Würfel rollen und nur bei der Augenzahl 6 in der eben beschriebenen Weise unpünktlich sein?
Das erste Beispiel birgt 50% Risiko für dich, das zweite nur knapp 17%. Was wäre dir lieber? Welcher Typ bist du? Wie viel Glück traust du dir zu?
Die Vorhersage von FeatureForecast verspricht also keine Ergebnisse, sondern zeigt nur auf, wie Ergebnisse wahrscheinlich aussehen würden, wenn die Features im „Projekt“ denen ähneln, die bisher umgesetzt und protokolliert wurden.
In der unteren Grafik siehst du dieselbe Vorhersage, aber jetzt mit dem Fokus auf den Werten statt auf ihren Häufigkeiten. Hier ist erkennbar, wie stark die Werte mit zunehmender Wahrscheinlichkeit wachsen.
Wie du siehst, bekommst du zuerst auch bei nur geringem Anstieg der Werte eine Menge mehr Wahrscheinlichkeit. 90 oder 100, das ist vom Wert her fast egal (ca. 10% Unterschied), aber 45% Risiko oder nur noch ca. 22%, das ist nicht egal, das sind weniger als 50% weniger Risiko!
Gegen Ende der Vorhersage jedoch, da ist die Risikoabnahme nur noch gering, auch wenn die Werte stark steigen. Weniger als 5% Risiko würdest du mit sehr hohen Werten erkaufen.
Aber wie gesagt: dies ist eine Vorhersage und damit genauso sicher wie die Wettervorhersage. Die 100% am Ende sind keine Garantie, sondern stehen nur für eine große Wahrscheinlichkeit unter der Voraussetzung, dass die Umsetzung der geplanten Features dem ähnelt, was schon in der Vergangenheit umgesetzt wurde.
Aber auch wenn das wie eine enttäuschende Einschränkung klingt - ich sehe es als ehrliche Aussage und als Feature, nicht als Bug des Ansatzes. Diese Klarheit ist viel wert. Solche Klarheit bieten die üblichen absoluten Schätzungen nicht.
Auf die Kategorisierung kommt es an
Mit der Verhersage verlagert sich der Fokus von den Zahlen auf die Inhalte. Das scheint mir auch ein wesentlicher und wichtiger Unterschied. Damit kommt nämlich in den Blick, worüber du Kontrolle hast.
Solange noch geschätzt wird, lautet die Frage an dich als Entwickler z.B. „Wie lange brauchst du dafür?“ Ob damit der Aufwand oder die Dauer gemeint ist, ist unklar. Aber egal. In jedem Fall geht es um eine Zahl. Wie du zu der kommst, ist im Grunde dem Fragenden einerlei.
Sobald jedoch vorhergesagt wird, wirst du als Entwickler nicht mehr nach einer Zahl gefragt. Stattdessen lautet die Frage: „In welche Kategorien fällt das?“
Wie fein du dann Kategorien schneidest, ist dir überlassen. Bleibst du auf einer Ebene mit „Bugfix“ und „Erweiterung“ oder gehst du tief mit „Bugfix/Frontend/Registrierungsdialog“ und „Erweiterung/Backend/Repository/Benutzerdaten“? Du könntest sogar anfangen, etwas zu zählen, z.B. die voraussichtlich betroffenen Module.
Die Notwendigkeit zur Kategorisierung für Vorhersagen könnte sogar eine Kraft sein, die die Diskussion über Anforderungen beflügelt. Du bleibst länger im Gespräch mit dem PO, weil du Anforderungen mindestens so fein schneiden willst, dass du Pakete in der Hand halten willst, deren Umsetzung sich klar messen lässt und die leicht zu kategorisieren sind.
Mach es, wie du magst - nur mach es konsistent. Kategorisiere, was du umsetzt und miss, wie lange du brauchst (Aufwand und/oder Dauer). Tu das fleißig über längere Zeit, so dass du Dutzende oder gar Hunderte Datenpunkte bekommst.
Über beides hast du volle Kontrolle. Kategorien unterliegen keiner Spekulation, Messungen auch nicht. Du kommst endlich raus aus dem Bauchgefühl.
Und wenn dann jemand eine Vorhersage will, dann musst du auch nur wieder kategorisieren. Kein Bauchgefühl im Spiel. Das ist Entspannung für dich!
Mit Zahlen hast du als Entwickler sozusagen nichts mehr am Hut. Wer eine Zahl will, der muss sie sich selbst ausrechnen. Dafür ist FeatureForecast da - auf der Basis der von dir bestimmten Kategorien für das, was umgesetzt werden soll.
Und für das, was dann bei der Simulation herauskommt, kannst du nichts. Wer fragt, muss sich selbst einen Reim darauf machen und wissen, welches Risiko er eingehen will. Als Entwickler versprichst du nichts. Genauso wenig wie das Wetter etwas verspricht.