Messaging - The Missing Ingredient
Robert C. Martin wrote an interesting article on the orthogonality of Object-Orientation (OO) and Functional Programming (FP). There is no rivalry between the two, or at least should not be. Both approaches have their merits.
FP and OO work nicely together. Both attributes are desirable as part of modern systems.
I can only agree. And I like how Martin distills an essence from both paradigms. OO to him is:
The technique of using dynamic polymorphism to call functions without the source code of the caller depending upon the source code of the callee.
And FP comes down to:
Referential Transparency – no reassignment of values.
He’s sure that both approaches used together will lead to better software. Not in terms of functionality or efficiency, but what I call „sustainable productivity“:
A system that is built on both OO and FP principles will maximize flexibility, maintainability, testability, simplicity, and robustness. Excluding one in favor of the other can only weaken the structure of a system.
In order to be able to deliver new features swiftly not only today but also in the future, software must be:
- correct
- malleable
Firstly it needs to be „provable“ correct, i.e. needs a reasonable test coverage. That’s what Martin hints at with robustness, I suspect. Automatic tests are the measuring stick for code base’s maturity and freedom of regression. They answer the questions „Is the code already correct?“ and „Is the code still correct?“.
Secondly code needs to be easy to understand, it needs simplicity. Understanding is the prerequisite for change. It’s the first ingredient of flexibility and maintainability or malleability for short.
And thirdly code needs testability, i.e. logic pertaining to a particular aspect of the solution should be easy to address with an automated test. That’s the second ingredient of malleability and a tangible manifestation of modularization which always has been a hallmark of malleability.
But although I like Martin’s article I’m not entirely satisfied with his argument. There’s something missing. And that’s what Alan Kay, the godfather of OO, called „the big idea“:
The big idea is "messaging" […] The Japanese have a small word - ma - for "that which is in between" - perhaps the nearest English equivalent is "interstitial". The key in making great and growable systems is much more to design how its modules communicate rather than what their internal properties and behaviors should be.
So it’s not just about whether a function is called directly or indirectly (OO) or whether it changes state or is pure (FP) or whether it contains loops or is recursive (FP). It’s also about how functions are „wired together“, how they interact with each other.
Let me explain what I mean with a couple of examples. Here’s a tiny scenario for which I will present you with different solutions based on Martin’s OO and FP essences:
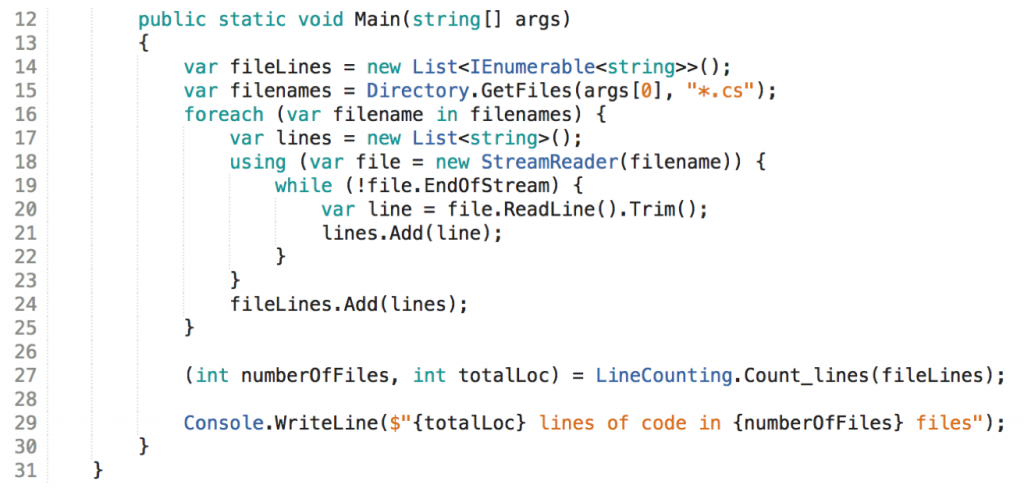
A program to count the non-empty and non-comment lines in source files within a directory. A root directory is specified upon program start. As a result the program displays the number of files analysed and the total number of relevant lines found. Example usage:
$ loccount /repos/someproject
4,926 lines of code in 12 files
$
„Pragmatism“
Let’s start with a straightforward solution as it might be written by someone not much concerned with lofty theories.
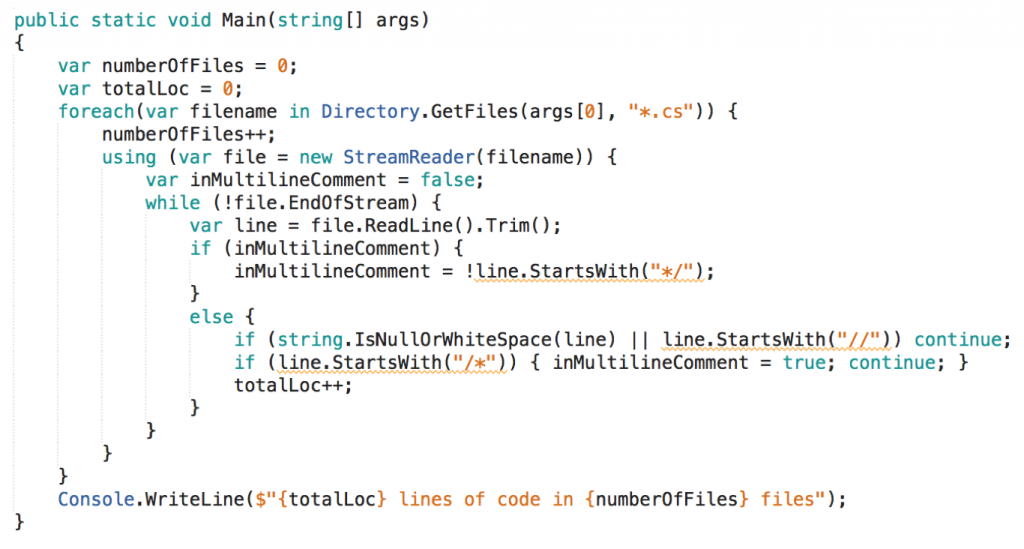
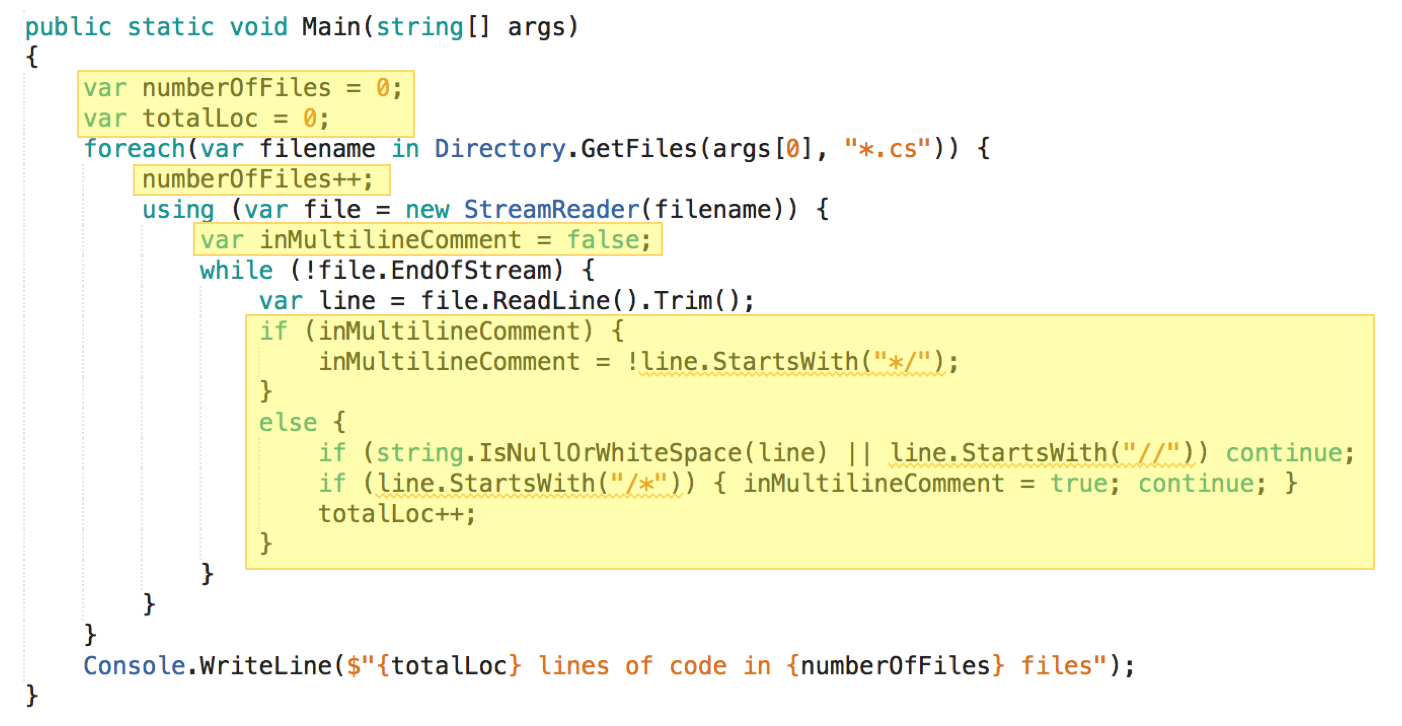
This is pure logic. The function Main() wrapped around it (and the class Program{} around that) is negligible.
The code is to the point; it delivers the desired behavior. This can be called simplicity - from the point of view of the writer. The writer did not spend time on modularization or recursion.
But does the code show simplicity from the point of view of a reader? I guess not.
Sure, this is a toy example, but even those 20 lines of logic are hard to understand. That’s the nature of logic. It’s devoid of meaning by itself. It has to be interpreted by a reader, it has to be mentally simulated; only by that understanding is generated.
And what about correctness? The pragmatist has not wasted any time on code to check for that either. Starting the program a couple of times while coding was sufficient for him to determine maturity (and as he progressed also freedom of regression). Unfortunately this won’t help a later reader to understand what’s happening nor is „robustness“ supported.
However, I’d say it’s no small wonder there are no tests since testability is virtually non-existent. The individual aspects of the solution cannot be tested in isolation. Which aspects (or responsibilities) could that be? I count at least the following on the highest level of abstraction:
- Accessing the file system
- Accessing the console
- Analysing file content
And of these file content analysis is the center piece, that’s the domain logic of the program.
Even though you might argue this all is so simple it needs not more structure to be quickly understood, I hope you agree something should be done about testability. At least the domain logic should be put under test.
Here I’m highlighting what I consider domain logic:
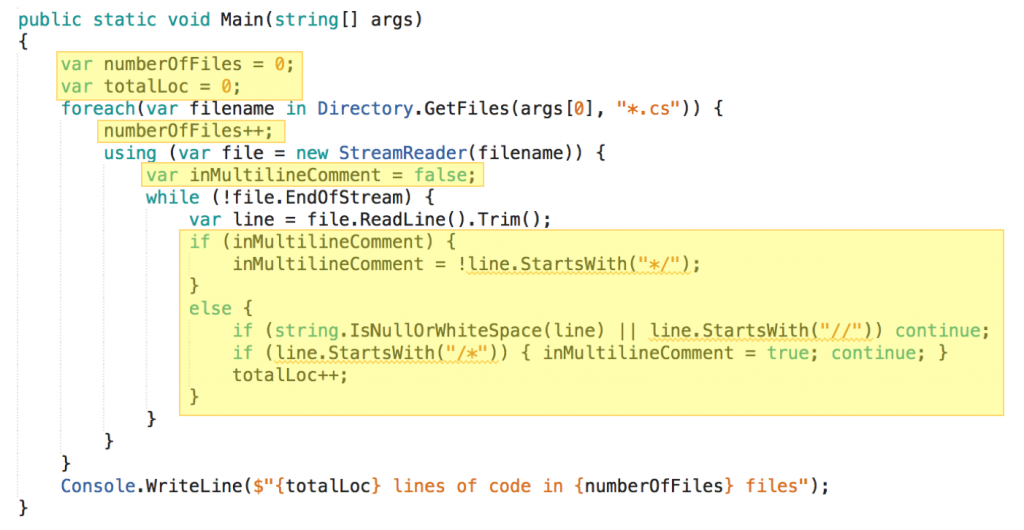
You see it’s pretty scattered throughout the function. Domain logic and other aspects are intertwined. Even though there are no goto statements I’d call this spaghetti code.
How can a test possibly be focused on just the domain logic?
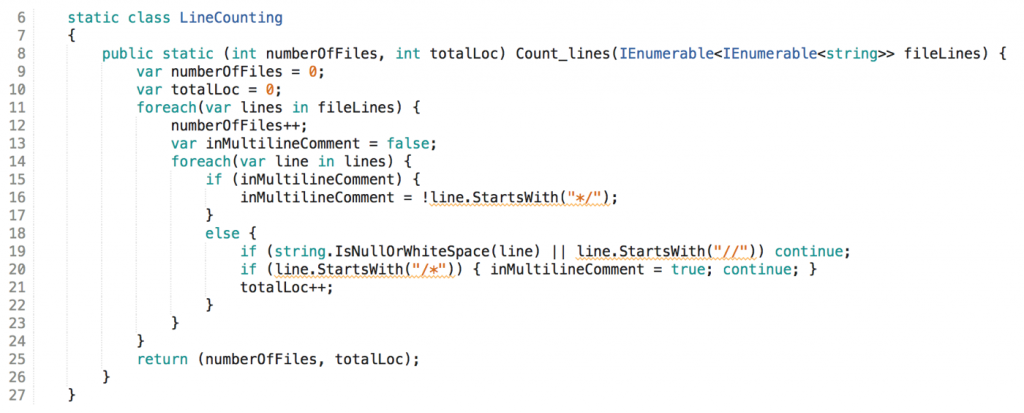
Object-orientation
OO to the rescue. Testability can be increased by encapsulating non-domain logic in objects and then replace these at test runtime with some kind of test double.
To enable this kind of polymorphism the Dependency Inversion (DI) and Inversion of Control (IoC) principles are employed.

Accessing the file system and displaying the results on the console are non-domain logic, both involve I/O. In the OO code this kind of logic is encapsulated in respective classes: Filesystem{} and Presenter{}. Calling it requires going through an object (highlighted in green). That’s an indirection, an inflection point.
By making the domain logic not depend on these classes directly but just on abstractions (interfaces, DI), different implementations can be injected at runtime (IoC) (highlighted in yellow).
And to make injection orthogonal to logic execution the domain logic is wrapped in its own class, App{}.
That way testing just the domain logic becomes possible:

Instead of „real“ file access and display logic a stub provides file data and a mock checks if it was called with the expected parameters.
This is polymorphism in action. The calling domain logic is not bound statically to specific logic. Its functional dependency can be resolved at runtime with any object living up to the expectations in terms of syntax and semantics.
At test runtime the test doubles conform to that specification. And at production runtime it’s objects instantiated from real file system and console adapters:

Functional Programming
Introducing inflection points is one way to make the domain logic testable. Disentangling and extracting it from the non-domain logic is another way. That’s what FP would do.
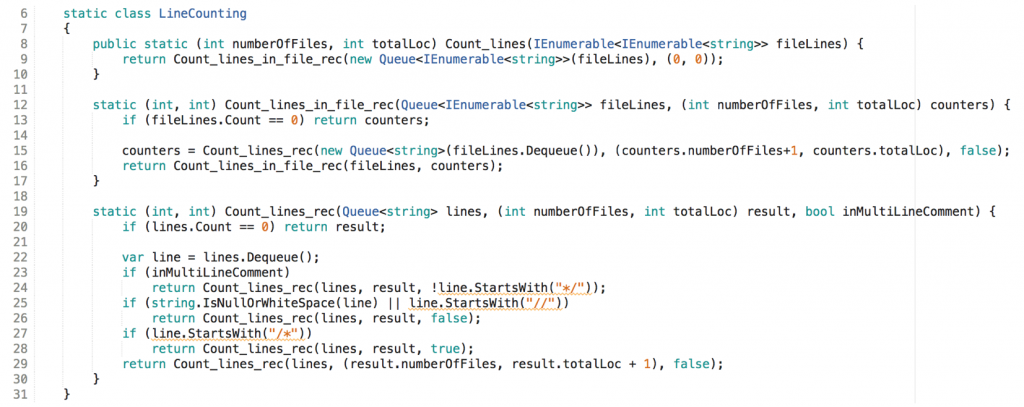
Here all data from files get delivered to the doorstep of the domain logic. And results are just returned to the caller. Side effects like access to the file system or writing on the console happen outside the domain logic. That way the domain logic can be encapsulated in a pure function which is referentially transparent:
f(a) == f(b) when a == b.
Hence you’ll find the domain logic looking quite different from before. It’s now free of (re)assignments. There are no variables whose values get updated. Names like line (line 22) or counters(line 15) are just labels for immutable values.
To avoid variables I had to get rid of loops and use recursion, though. You decide whether this improves the understandability of the solution or not.
In any case this way the domain logic is free of resource dependencies and can be easily tested. To underline this I even made its functions static.
What happens outside the domain logic is of no concern to it. To make it testable I just need to lump together the side effect laden logic:
Some of it runs before the domain logic function, some after.
Martin writes:
[I]f we exclude the hardware, and any elements of the outside world, from our referential transparency constraint, then it turns out that we can create very useful systems indeed.
That’s what this solution does.
[I]f we say that function [LineCounting.Count_lines()] represents all functions in the system – that all functions in the system must be referentially transparent – then no function in the system can change any global state at all.
This is true for this solution. So I indulge in thinking it’s a FP solution.
Messaging
As I said at the beginning: I’m missing something from Martin’s explanation. Even though he expounds the importance of testability and malleability I find the OO and FP approaches lacking.
Functional dependency
Sure, they have been boiled down to just an essence and there’s more to them. But even if I take that into account the situation does not improve. Both do not tackle a fundamental problem which has been haunting software development since the invention of subroutines: functional dependency.
Functional dependency to me means: logic calling another function to offload some work, waiting for a result, and then to continue with the result of that function.
This is so natural to programmers, so prevalent in code bases, why should that be a problem? Because it makes code difficult to understand and hard to test.
Functional dependencies to me are the number one reason why functions grow almost indefinitely. 1000, 5000, even 10000 lines in a function are not even possible but common - and a huge impediment for reasoning about the code and changing it.
Functional dependencies violate the Single Level of Abstraction (SLA) principle. Logic in a function always is on a lower level of abstraction than calling another function.
Functional dependencies split logic in parts which cannot be tested independently. Also the logic can only be tested by itself if the dependency gets „defused“ by using a test double.
As you can see functional dependency is present in both the OO and FP solutions:

In the OO solution it got defused in order to test the domain logic. In the FP solution it got ignored by extracting the domain logic.
Defusing by using DI/IoC introduces complexity, and does not solve the problem of unbounded function growth and violation of the SLA. Extraction of the „system under test“ on the other hand leaves the surrounding logic untestable by itself.
Functions as objects
Functional dependency stems from a time without objects. Encapsulation and polymorphism were no virtues. Software was behavior creating logic interspersed with subroutine calls.
But then came object-orientation. Alan Kay envisioned it like this:
I thought of objects being like biological cells […] only able to communicate with messages[,] so messaging came at the very beginning
Two things are notable about his definition:
- Objects are like cells, i.e. they contain all that’s needed to accomplish a task, albeit a small one. They encapsulate logic, but do not depend on other objects’ logic.
- Objects are like cells, i.e. they „do their thing“ upon reception of a message and send on results as messages. They neither know where input is coming from, nor do they know where output is going to. Message flow is unidirectional like the flow of molecules across the synaptic cleft between a nerve cell and a muscle cell.
To put it bluntly: Alan Kay envisioned software built from parts without functional dependencies. Because there is no such thing in nature. Biological cells are not connected in request/response relationships.
Although this might sound a bit esoteric it is not. Rather it is very pragmatic advice and easily implemented. The most difficult part is to leave mainstream object-orientation behind for a moment.
Here’s some procedural code, even though technically an object is involved:
int f(int a) {
var x = … a …;
var y = o.g(x);
var z = … y … a …;
return z;
}
This code is procedural because it contains a functional dependency. The logic in f() depends on the logic in g() of object o.
The logic before and after the function call is hard to test in isolation. And it cannot be tested independently of each other.
Even though f() might belong to a class and be called through a mainstream object - e.g. p.f(42) - it’s not object-oriented along Alan Kay’s notion of OO. f() cannot just „do its thing“. It can start, but then needs to stop and wait, and can only continue after it received some result from some other function. Messages between f() and o don’t flow unidirectionally but bidirectionally.
This might seem like a small thing. After all this is how almost all functions look like; they are a mixture of logic and calls to other functions of the same code base. Nothing has changed in this regard since the mainstream adoption of object-orientation.
That’s my point: The most important aspect of OO - at least according to Alan Kay - is still missing. We don’t build software on the notion of messaging. And the negative effects of that are numerous.
So let me add to Martin’s definition of OO:
OO is messaging plus polymorphism. Where messaging means functions free of functional dependencies.
How can this be accomplished? Very easily: Just have functions either contain logic or just calls to other functions of the same code base. Here’s the OO version of the above code:
int fv2(int a) {
var x = f_before(a);
var y = o.g(x);
var z = f_after(y,a);
return z;
}
int f_before_(int a) => … a …;
int f_after(int y, inta) => … y … a …;
The new function fv2() does not contain any logic. I call that kind of function an integration. Its job now is only to pull together three functions into a message flow.
Since fv2() does not contain any logic it cannot - by definition - be functionally dependent.
The logic from f() has been moved to two new functions. Their job is to just execute this logic. They are focused on what I call operation. They play the role of objects in Alan Kay’s analogy. Messages flow in, get processed, results flow out. Operations don’t know where they get their input from or where their output goes to. Of course they also are not functionally dependent; they don’t call a function.
This is, I think and experience every day, a huge improvement over the usual way of connecting functions through functional dependencies.
- Improvement #1: High testability of operations. No dependencies have to be replaced with test doubles.
- Improvement #2: Easy to understand integrations. They better conform to the SLA. The absence of loops requires less mental state while studying them.
- Improvement #3: Very short functions. Without functional dependencies functions do not grow because an integration of dozens of lines is hard to read and easy to refactor; there’s no reason not to do it. And because an operation of dozens of lines cries for extraction of some logic into another function - but as soon as that’s done all logic has to be extracted and the operation turns into an integration.
All together now
After this detour into theory let me show you what that means applied to the solution of the line counting problem.
Starting from the FP solution the first step is to extract the I/O logic into their own methods, operations that is. This makes it individually testable in general. Main() thus becomes an integration:

The second step would be to overhaul the FP line counting. Check above: Count_lines_rec() is a mess in terms of functional dependencies, even though recursion looked so intriguing.
I’d rather not use recursion and don’t follow FP lore if the code was easier to understand. So maybe go back to the OO solution and improve it? How about removing the functional dependencies and make line counting an operation?
This is still least easy to test, if not even easy to understand. No functional dependencies; even a pure function in the FP sense.
From the messaging point of view this would be a sufficient solution: I/O extracted into operations, line counting made into an operation, Main() an integration. The glaring concerns are testable in isolation. Each operation is focused. All operations easily fit on the screen.
But how testable is the whole? Since all functions are static so far and Main() does the integration, the whole can only be tested manually by running the program.
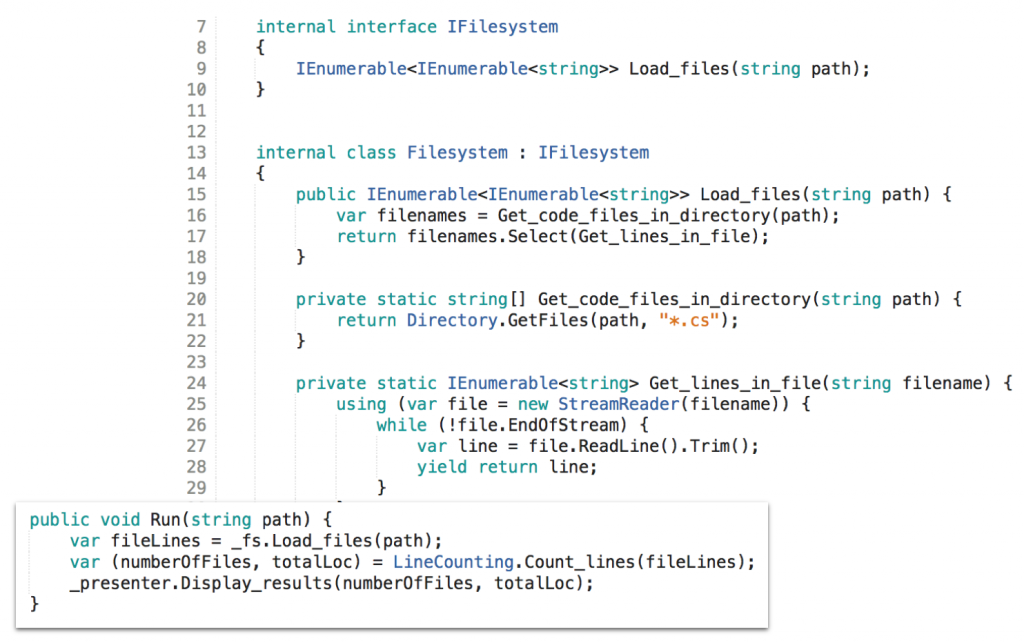
So after the application of some messaging I’d say some polymorphism is in order, too. The original OO solution had its merits. Why not keep that and improve on it by applying some messaging?

The App{} class returns to make IoC possible. The Filesystem{}and Presenter{} classes together with their interfaces return for DI. But with messaging the Run() method now looks clean. For that though, another method needed to be introduced which integrates the two file system methods previously needed when resource access still was scattered across the OO domain logic.
Not bad, I’d say. However Load_files() is striking me strange. Firstly, is it really a true integration? Doesn’t the Select() look like a loop, i.e. logic? Yes, that’s close to logic, but it does neither hamper understandability nor does it compromise testability. It’s a form of declarative programming. I count it as a form of integration.
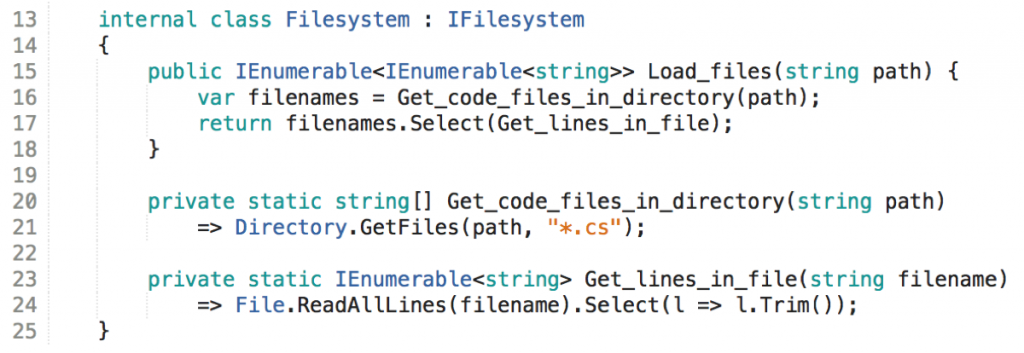
Secondly why have this method in App{} when it integrates two functions from the same object? Yes, that does not make sense. The method can be moved to Filesystem{} thereby leading to even more encapsulation.
Please note that I now made the two former methods of Filesystem{} static. To me that’s the default. The reason is simple: static methods are easier to test. I need compelling reasons to make methods non-static. And the only compelling reasons I can think of are a need for polymorphism or shared state.
FP thinking drives me away from shared state, and polymorphism is mostly needed just to increase testability which is also increased by messaging. Hence you’ll find many more static method in my code bases than usual.
Summary
There is no contradiction between OO and FP. There is no either-or. Both can and should co-exist in the same code base. But don’t mistake these labels for the real thing. It’s always about purpose, about beneficial effects.
Hence I’d rather leave the labels behind and focus on the principles. However, to me most helpful there are not just the two Robert C. Martin distilled, but three:
- messaging
- polymorphism
- referential transparency
In this order:
- First apply messaging systematically and you’ll see how understandability and testability go up tremendously.
- Then add polymorphism to increase testability where needed.
- Finally use referential transparency to further isolate logic from side effects in order to gain understandability and testability.
To underscore it even more let me say: Without messaging, i.e. the absence of functional dependencies, all else stays a struggle in attaining correctness and malleability.
Addendum I
Of course I know that Get_lines_in_file() can be replaced by just one line of code. But I used more logic to have a bit more „logical meat“ on this small example solution. The file system adapter could look as simple as this:
Even merging the two static methods into Load_files() would be ok, I guess. But of course then independent testability of the respective logic would be gone.
Addendum II
Even after application of the above principles there’s one part of the solution I’m not really satisfied with. It’s the domain logic. Despite being confined to a pure function and easy to test, it’s quite a lot to test. There are at least two responsibilities blended together in the function:
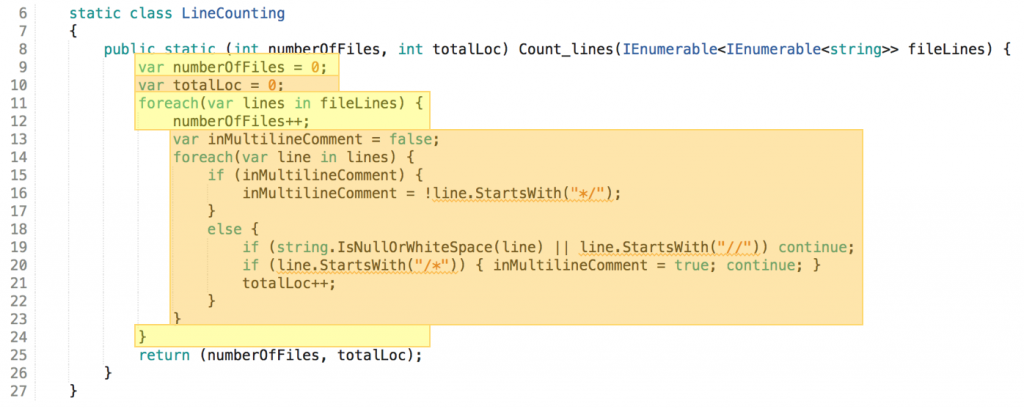
It’s handling files (enumeration and counting) and handling lines (enumeration, classification, counting).
To improve the conformance to the Single Responsibility Principle (SRP) for more testability and understandability I would like to refactor the logic a bit.
I could extract the inner responsibility into a method of its own:
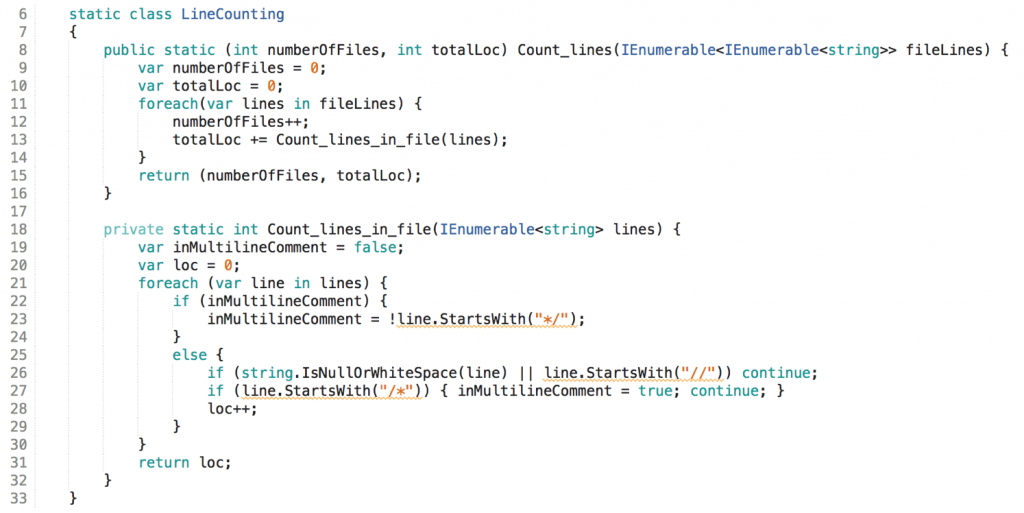
This does not look bad. The operation now is smaller, more focused, and the calling method is smaller too, although it’s not a true integration. But the „pseudo-integration“ is so simple, maybe that’s ok for understandability and testability. Its logic cannot be tested standalone, but with simple input data the call to Count_lines_in_file() is negligible.
However I feel the messaging principle urging me to think again. So I come up with this:

The logic in Count_lines() is gone. The imperative foreach has been replaced by declarative looping with Linq. Also no more incrementing of any counters. This has been extracted into a pure function which can be tested even more easily. Count_lines() now clearly shows its nature of a map-reduce processing step. It has become an integration. Messaging is established: fileLines.Select() is sending blocks of lines to Count_lines_in_file() which in turn is sending LOC counts on to Aggregate() which sends them on to Total().
But what about Count_lines_in_file()? To be honest, I now find it comparatively complicated and mixing responsibilities. Enumeration and classification and counting are happening all within a single function. That’s not very SRP.
But when I again try to apply the messaging principle I’m able to pull the different responsibilities apart into a message flow:

lines.Select() produces a stream of single lines which are passed into a state automaton to be classified as relevant or not. And this result then flows into a counting operation.
The state automaton is a real object even in the mainstream OO sense. It encapsulates state which is shared across calls to its single method. To me that’s a perfect example for the co-existence of OO and FP in the same program, even the same class. Count_relevant_lines() is a pure function (FP), but IsRelevant() is the opposite: a stateful function made possible with the help of OO features.
And why not? It’s easy to test with a little help of an internal constructor:
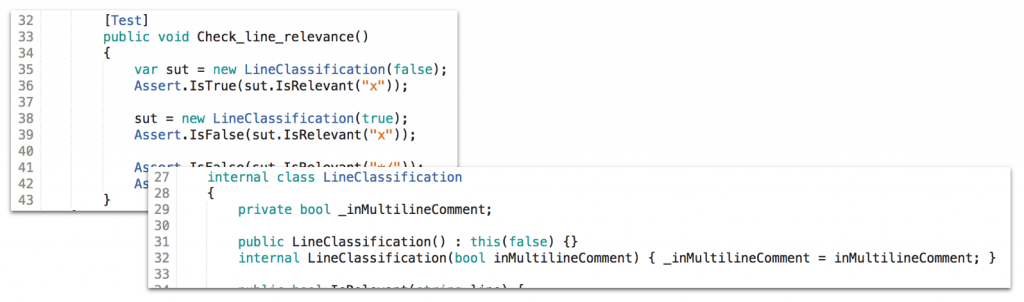
Alternatively I could use a second parameter to a static function and a closure, I guess. But that to me would be less encapsulating. I’m happy to mix FP and OO in the way shown.
But note the driver behind these refactorings: it’s the messaging principle. I want to get rid of functional dependencies wherever I can.