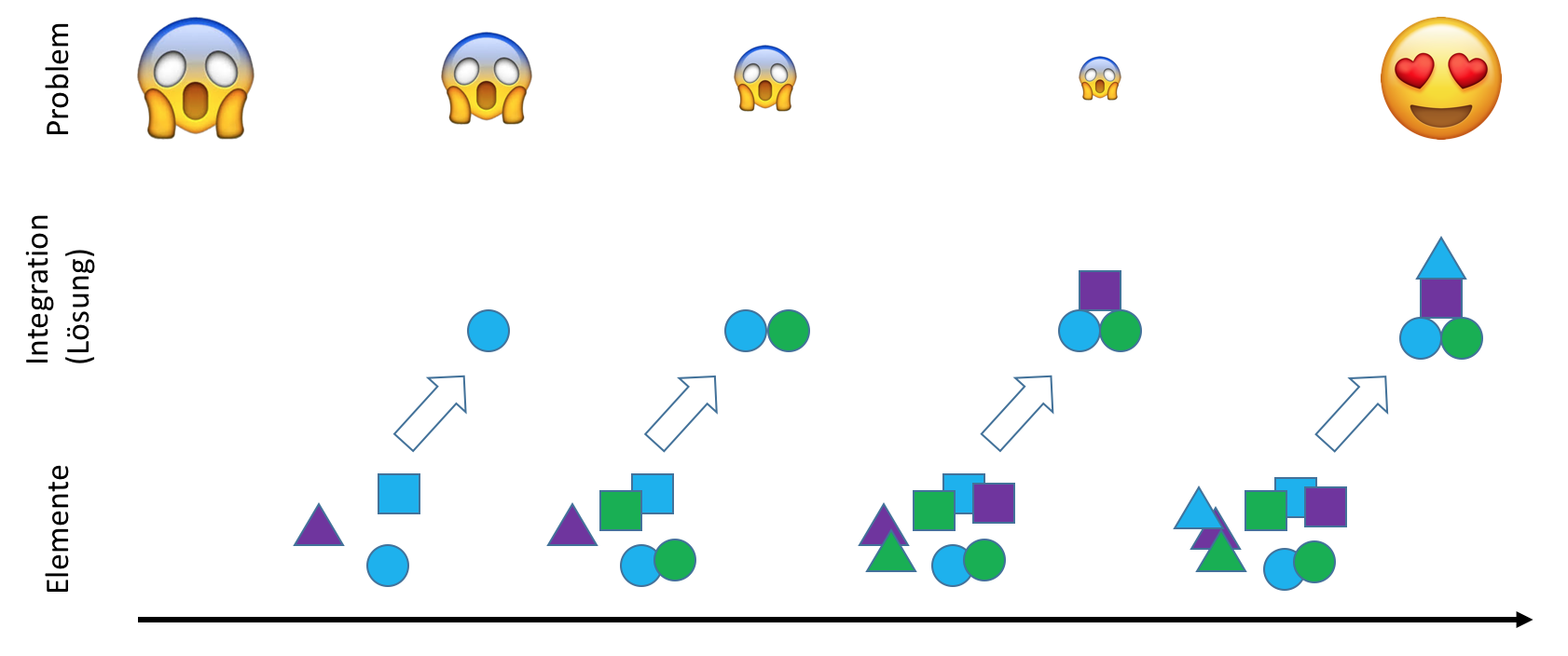
All together now - Schrittweise abstrahieren
Aggregation, Destillation und Integration sind alle wertvoll für die Softwareentwicklung. Es ging mir bei der Differenzierung im vorherigen Artikel also nicht darum, die eine oder andere Abstraktion herabzusetzen. Allerdings liegt mir am Herzen, dass tatsächlich alle Abstraktionsarten benutzt werden und zwar in einer möglichst hilfreichen Weise.
Aus dem Gesagten sollte klar geworden sein, dass das nicht der Fall ist, solange erstens die Integration keinen gleichberechtigten Platz neben Aggregation und Destillation bekommt. Und zweitens gehört die Integration an den Anfang der Softwareentwicklung - nicht weil sie „besser“ oder „wichtiger“ wäre, sondern weil schlicht nur für sie am Anfang überhaupt Material vorhanden ist.
Wer Softwareentwicklung startet mit der Suche nach Aggregaten oder gar Destillaten, arbeitet mit leeren Händen. Es fehlt eine Grundmenge, aus der in dieser Weise abstrahiert werden könnte. Das Ergebnis: vorzeitige Abstraktion als Spezialfall der vorzeitigen Optimierung.
„[P]remature optimization is the root of all evil.“, Donald Knuth
Klassen und Interfaces am Anfang der Softwareentwicklung halte ich aus diesem Grund für einen Irrweg. Mit ihnen zu beginnen bedeutet, sich der Spekulation hinzugeben und stellt eine Einladung an die Verkrustung dar.
An einem Beispiel möchte ich meine Sichtweise nun konkret erklären. Ausgangspunkt sind folgenden Anforderungen. Sie sind notwendig sehr einfach, doch das tut dem Thema keinen Abbruch. Bei umfangreicheren Anforderungen kann es nur umso wichtiger sein, sauber mit Abstraktionen umzugehen.
Entwickle eine Anwendung, die die durchschnittliche Anzahl der Worte ab 3 Zeichen Länge pro Zeile in einer Textdatei bestimmt. Worte sind dabei Ketten von non-whitespace Zeichen und ohne übliche Sonderzeichen. Die Textdatei wird der Anwendung bei Start auf der Kommandozeile mitgeteilt.
Was würde die gemeine Objektorientierung hier jetzt für Abstraktionen entdecken? Ich habe diese Art der Spekulation inzwischen verloren. Deshalb will ich mich daran gar nicht mehr versuchen.
Anwendungen als Integrationen von Logik
Es sollte offensichtlich sein, dass Anwendungen selbst Abstraktionen sind. Sie stellen Integrationen dar. In ihnen sind komplementäre Funktionalitäten zu einem Ganzen verdrahtet, das dem Benutzer das Leben einfacher macht. In diesem Fall muss er sich nicht mit den Details der Textbeschaffung, Wortbestimmung und Wortzählung sowie Durchschnittsberechnung befassen. Software ist insofern ein Werkzeug wie eine Waschmaschine oder ein Rasenmäher, das sich über eine Benutzerschnittstelle bedienen lässt.
Für eine Integration stellt sich die Frage, welche Teile von ihr zusammengefasst werden. Darauf gibt es zwei Antworten. Die triviale lautet: Anwendungen integrieren viele verschiedene Logik-Anweisungen. Ein Beispiel:

Die entscheidenden Zeilen sind die von 12 bis 24. Sie enthalten die Logik, die das gewünschte Verhalten herstellt. Die Anwendung abstrahiert von diesen Details indem sie das Verhalten über textstats.exe als Ganzes zugänglich macht.
Dass hier eine Funktion Main() nötig wird (die sogar noch einer Klasse zugeordnet sein muss), ist eine vernachlässigbare Eigenheit der Sprache C#. Eigentlich geht es nur um die Logikanweisungen, die durch den Compiler zu einer ausführbaren Einheit übersetzt werden.
Software ist eine Abstraktion, die zunächst keine weiteren Abstraktionen braucht. Die Bausteine, die sie integriert, sind die Logik-Anweisungen einer Programmiersprache.
So einfach könnte es sein mit der Abstraktion in der Softwareentwicklung – wäre da nicht eine klitzekleine Schwierigkeit: Logik als Bausteine von Anwendungen lässt sich nur sehr schwer bestimmen.
Für das obige Problem mögen Sie es einfach finden, die passenden Anweisungen zu finden. Doch schon wenn die Anforderungen etwas umfangreicher und/oder komplizierter werden, ist es damit vorbei.
Wir werden der Logik innerhalb einer Anwendung schlicht nicht Herr ohne weitere Abstraktionen. Software muss deshalb weitere in sich haben. Eine Anwendung muss abstraktere Bausteine integrieren als Logik-Anweisungen.
Anwendungen als Integrationen von Funktionen
Die erste Abstraktion innerhalb von Software sind nicht Klassen, wie es die Objektorientierung gern hätte, sondern Funktionen. Wenn die Logik schwer handhabbar wird, dann bekommt man sie nicht mit Aggregaten in den Griff, sondern mit weiterer Integration.
Dafür gibt es drei Gründe: Zum einen bietet die reine Logik keinen Stoff, aus dem Aggregate abstrahiert werden könnten. Aggregate, d.h. Module, fassen Funktionen (oder andere Module) zusammen. Reine Logik ist jedoch unstrukturiert, es gibt darin keine Funktionen.
Zum anderen haben Aggregationen eher keinen Wert für den Kunden. Sie machen die Entwicklung nicht spürbar produktiver; sie erzeugen keine Bequemlichkeit für die Entwicklung.
Und schließlich stellt Logik ganz natürlich den Baustoff für Funktionen dar. In einer Menge von Logik-Anweisungen die zu finden, die in ihrer Verschiedenheit und Komplementarität zu einem Ganzen integriert werden können, ist einfach. Logik hat für einzelne Funktionen die passende Granularität als Baustein.

Als Ergebnis entstehen Funktionen, die ausschließlich Logik enthalten; ich nenne sie Operationen.
Anwendungen werden dadurch zu einer integrierenden Abstraktion mit zwei Ebenen (strata). Auf der obersten Ebene ist weiterhin die Anwendung (hier repräsentiert durch Main()). Die integriert jedoch nicht mehr feingranulare Logik, sondern Operationen mit einer gröberen Granularität. Und diese Funktionen wiederum integrieren Logik.
Funktionen als Integrationen von Funktionen
Sie sehen: aus Logik, die unzweifelhaft zur Lösung des Problems des Anwenders nötig ist, ergeben sich ganz natürlich Abstraktionen. Aber nicht, wie es die Objektorientierung denkt, Aggregationen, sondern Integrationen. Sie stellen vereinfachende Zusammenfassungen von Teilfunktionalität dar, die sich der Verwendung in unterschiedlichen Zusammenhängen anbieten - und zudem die Logik besser verständlich macht, weil sie sie mit Bedeutung auflädt. Funktionsnamen sind abstrakte Platzhalter für Details. Über die Signatur einer Funktion lassen sich diese Details bequem bedienen. Das schafft Produktivität.
Für mich ist das ein Abstraktionsrezept, das der Fortsetzung lohnt. Warum bei Operationen als Integrationen stehenbleiben? Main() zeigt ja schon, dass sich nicht nur Logik integrieren lässt. Funktionen sind wunderbare Integrationsbausteine.
Wenn auf unterster Ebene Logik-Anweisungen integriert werden zu Operationen, dann können auf darüber liegenden Ebenen Funktionen ebenfalls integriert werden. Funktionen, die Funktionen integrieren, nenne ich Integrationen.
Angewandt auf den bisherigen Code kann das z.B. so aussehen. Die grünen Funktionen sind Integrationen, die roten Operationen.

Main() als Repräsentation der Anwendung ist jetzt eine sehr einfache Integration geworden. In drei Zeilen ist dort ausgedrückt, was vorher 13 Zeilen gebraucht hat. Aber auch LoadData() und ExtractRelevantWordsFromLines() stellen bequeme Integrationen dar. Und wenn sich irgendwo Funktionen zeigen, die zusammen wiederum eine nützliche (oder auch nur gut verständliche) Integration ergeben, dann können sie sehr leicht zusammengefasst werden, z.B.

Wichtig ist es, bei der Integration darauf zu achten, dass die Granularität der Bausteine angemessen ist. Funktionen und Logik in einer Integration zu mischen, passt nicht. Nur wenn integrierende Funktionen keine Logik enthalten, bleibt die Testbarkeit von Code hoch. Logik ist dann ausschließlich in Operationen versammelt, die nicht weiter funktional abhängig sind - und insofern leicht zu testen. Wenn Funktionen so strukturiert sind, dann folgen sie für mich dem Integration Operation Segregation Principle (IOSP).
Klassen als Aggregationen von Funktionen
Integration ist für mich die initiale und sogar primäre Abstraktion in der Softwareentwicklung. Durch Integration entstehen Funktionseinheiten, die mehr und mehr Verhalten bündeln und bequem verfügbar machen. Details der Herstellung von Verhalten werden verborgen. Integrationen bieten quasi „Verhalten auf Knopfdruck“.
Doch so produktivitätssteigernd Integration ist, früher oder später braucht es eine weitere Art der Abstraktion. Zur Beherrschung von wachsenden Mengen an Bausteinen ist Aggregation nötig, sonst verlieren wir die Übersicht.
Das ist schon der Fall im obigen Beispiel, würde ich sagen. Neun Funktionen „in einer Reihe“ sind nicht mehr gut zu überblicken, allemal, wenn sie nicht alle gleichzeitig auf den Bildschirm passen.
Als physische Aggregation würde sich zur Herstellung von Übersichtlichtkeit eine Verteilung der Funktionen auf Dateien anbieten. Dadurch würden Funktionen Kategorien zugewiesen, die durch Dateinamen bezeichnet sind.
Leider lassen das jedoch nicht alle Programmiersprachen zu. In Java und C# ist eine solche Verteilung z.B. nur möglich, wenn Funktionen als Methoden in Klassen zusammengefasst sind. Deshalb lasse ich im Weiteren Dateien als Abstraktionsmittel außen vor und konzentriere mich auf Klassen (bzw. allgemeiner Module).
Aggregationen abstrahieren von Unterschieden, indem sie das existierende Gemeinsame hervorheben. Inwiefern haben also die Funktionen im Beispiel etwas gemeinsam, inwiefern unterscheiden sie sich andererseits?
Ich finde für neun Funktionen zunächst fünf Aggregate, d.h. Klassen:

Meine Kriterien für die Zusammenfassung in einer Klasse einerseits und die Verteilung auf verschiedene Klassen andererseits, will ich hier dahingestellt lassen. Ich habe mich leiten lassen von einem Architekturmuster, das ich [IODA Architektur] nenne.
Wichtiger als die genauen Kriterien ist mir an dieser Stelle, dass es überhaupt welche gibt. Wer auf die Funktionen blickt, wird durch seine Brille bei manchen irgendwelche Gemeinsamenkeiten finden und bei anderen keine. Manche Funktionen sind durch eine kohäsive Kraft miteinander verbunden, andere nicht. Und das wird durch die Aggregation in einer Klasse formal hervorgehoben.
Wie die Klassen auf Dateien verteilt und diese in Verzeichnissen zusammengefasst sind, ist dann eine zweite Sache. Damit kann die Aggregation noch physisch unterstrichen werden.

Klassen als Aggregationen von Integrationen
Zunächst sind Klassen nur Aggregationen. Sie fassen verschiedene Funktionen auf der Basis von etwas Gemeinsamem in einer programmiersprachlich relevanten Weise zusammen. Sie geben dieser Zusammenfassung einen Namen, eine Bedeutung. Sie spannen einen Namensraum auf.

Was in Klassen aggregiert ist, steht ohne weiteren Zusatz gleichberechtigt nebeneinander. Es stellt allerdings eine überschaubarere Menge dar als das, was vorher ohne Klassen auf einem Haufen lag.
Spannend wird es, wenn das Gemeinsame einer Anzahl von Funktionen ist, dass sie einer Integrationshierarchie angehören. In dem Fall helfen Klassen durch Sichtbarkeitsattribute, diesen Umstand zu verschleiern. Sie können also helfen, Integrationen „auf den Punkt zu bringen“, indem sie lediglich die Wurzel eines Integrationsbaumes zugänglich machen - und alle darunter hängenden Bausteine verbergen.

Im Fall der Klasse Parser{} ist nur die Integrationswurzel öffentlich, alle anderen Funktionen sind unsichtbare Details der Leistungserbringung der Integration. Ob diese Wurzelfunktion eine Operation ist oder eine Integration? Das kann man ihr und der Klasse als Nutzer von außen nicht ansehen.
In dieser Hinsicht unterscheiden sich Klassen ganz wesentlich von syntaktischen Namensräumen und physischen Aggregationen. Klassen helfen hier der Integration, allerdings sind sie deshalb nicht selbst Integrationen. Sie bleiben lediglich Aggregationen.
Anwendungen als Aggregationen von Klassen
Logik-Anweisungen sind Elemente, die in Funktionen integriert werden. Funktionen sind Elemente, die von anderen Funktionen integriert werden oder von Klassen aggregiert.
Klassen sind nun Elemente, die von Anwendungen aggregiert werden. Zunächst sind Anwendungen - oder allgemeiner: Bibliotheken - nur Sammlungen von Klassen, die etwas gemeinsam haben. Sie alle leisten etwas, das der Erfüllung der Anforderungen des Kunden dient. Fünf Klassen sind im obigen Bild in den Topf der Anwendung geworfen und mit dem Etikett textstats.exe versehen worden.
Darin besteht die erste Kunst der gemeinen Objektorientierung. Ihr Ziel ist es, die Klassen zu finden, für die die zu realisierende Anwendung das Aggregat ist. Sie geht also von der Abstraktion aus und sucht zugehörige Elemente.
Der Ansatz, den ich hier beschreibe, beginnt am anderen Ende. In ihm stehen Klassen nicht am Anfang. Weder sieht er die Anwendung als Aggregat noch sucht er nach Aggregaten. Stattdessen ist die Anwendung vor allem ein Ort der Integration. Aggregate mögen später kommen, wenn genug Material dafür angehäuft ist. Klassen ergeben sich, wenn klar ist, wie das gewünschte Verhalten mittels Logik, Operationen und Integrationen hergestellt werden kann.
Klassen als Integrationen von Klassen
Bibliotheken mögen als reine Aggregate von Klassen durchgehen; Anwendungen jedoch integrieren immer. Deshalb liegt es nahe, dass es in Anwendungen auch Klassen gibt, die integrieren.
Integrierende Klassen sind Klassen, die andere, komplementäre zusammenziehen zu etwas Neuem, zu etwas Größerem, zu etwas Bequemerem. Das zeigt das folgende Listing exemplarisch anhand der neuen Klasse App{}:

Die Aufgabe von App{} ist es, die Leistungen anderer Klassen zu bündeln. Sie enthält deshalb in diesem Beispiel selbst auch keine Logik. Das ist zwar nicht Voraussetzung für eine integrierende Klasse, unterstreicht ihre Aufgabe jedoch.
Die Verantwortlichkeit von Program{} reduziert sich damit darauf, den Eintrittspunkt für die Anwendung zu definieren und alles herzurichten, damit das in App{} integrierte Gesamtverhalten abläuft.
Die integrierende Klasse steht hier an der Spitze und zieht die ansonsten nur aggregierten weiteren Klassen der Anwendung zusammen. Integrationen mit Klassen können aber natürlich auch an anderer Stelle stattfinden. Ist das sauber gemacht, bergen sie viel Potenzial für eine Produktivitätssteigerung.
Interfaces als Destillate von Klassen
Aggregate treten für mich erst nach Integrationen auf die Bühne der Softwareentwicklung. Und Destillate kommen sogar noch später. Der Grund: Für Destillate braucht es noch mehr Material, damit sich darin überhaupt eine destillierbare Essenz anreichern kann.
Das ist in einer Anwendung der Fall, wenn sich einige Klassen stabilisiert haben und darin destillierbare Muster zu finden sind. Oder das ist der Fall, wenn über Anwendungen hinweg Muster erkennbar sind.
Innerhalb von Anwendungen können Destillate dann Grundfunktionalität (oder Grundstruktur) bereitstellen in Form von Basisklassen, die von Ableitungen moduliert werden. Oder Destillate beschreiben abstrakt Funktionalität, die am Nutzungsort in verschiedener Weise konkretisiert werden kann.
Ein Freund von Destillaten in Form von Basisklassen bin ich nicht. Vererbung verwende ich nur in sehr wenigen und sehr klaren Fällen der Nützlichkeit und dann vor allem im Zusammenhang mit Datenstrukturen. Stattdessen favorisiere ich die Komposition (Favor Composition over Inheritance, FCoI), also die Integration, um auf vorhandener Funktionalität aufzubauen.
Interfaces als Form-Destillate finde ich jedoch nützlich, insbesondere, um die Testbarkeit von Code zu erhöhen. Davon kann im Beispiel die Klasse App{} profitieren. Sie ist die Integrationswurzel für das gesamte Verhalten der Anwendung. Ein automatisierter Akzeptanztest wäre hier also angezeigt. Doch die Abhängigkeit insbesondere von der Ressource Standard-Output macht das schwierig. Es wäre schön, Ressourcen für einen Test „abklemmen“ zu können.
Mit Dependency Inversion (DI) und Inversion of Control (IoC) ist das ohne technologische Klimmzüge möglich. Statt App{} direkt von Ressourcen kapselnden Aggregaten abhängig zu machen, schiebe ich ihr Form-Destillate unter und injiziere Konkretisierungen zur Laufzeit.
Das ist für mich ein Muster über Anwendungen hinweg:
- Ressourcenzugriffe machen das automatisierte Testen immer wieder schwierig. Also werden sie in Klassen aggregiert und dann destilliert (DI).
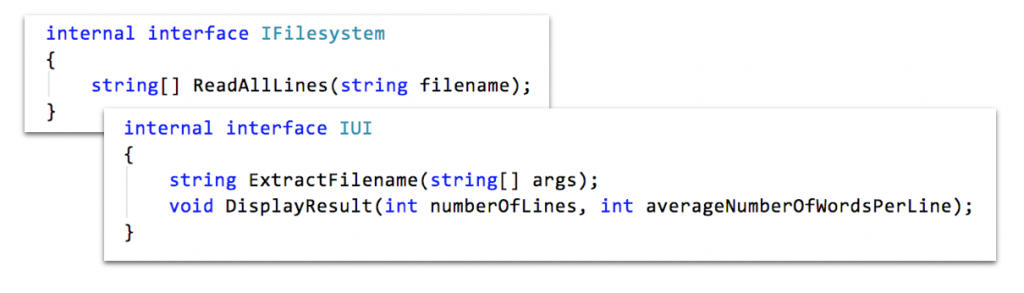
- Destillate werden zur Laufzeit durch Produktionsobjekte bzw. Testattrappen konkretisiert.

Der Preis, den der Mehraufwand für DI und IoC und die steigende Komplexität darstellt, halte ich für klein im Vergleich zum Gewinn. In Maßen eingesetzt ist eine solche Suboptimalität nützlich, um das Ganze deutlich zu verbessern im Hinblick auf nachweisbare Korrektheit.
Aber Vorsicht! Lassen Sie sich nicht davontragen von der Verlockung solcher Art Flexibilität. Würde dadurch nicht Software ganz allgemein viel wandelbarer? Das halte ich für einen Trugschluss, der leider in Robert C. Martins Clean Architecture einen populären Ausdruck gewonnen hat. Die Übersichtlichkeit der Beziehungen zwischen Abstraktionen steigt durch DI und IoC nicht. Selbst Martin muss bei Anblick eines „Komponentendiagramms“ für ein Beispiel in seinem Buch konstatieren:
„Much of the complexity […] was intended to make sure that the dependencies between the components pointed in the correct direction.“
Komplexität ist der Feind von Korrektheit und Wandelbarkeit. Auch mit allerbester Absicht sollten komplexitätserhöhende Maßnahmen wie DI und IoC daher nur sehr sparsam eingesetzt werden.
Das ist auch der Grund, warum Sie im hier vorgestellten Code über eine lange Strecke nur statische Methoden gesehen haben. Ich halte sie schlicht für besser testbar und leichter verständlich. Statische Methoden legen einfach nahe, keine Abhängigkeiten von Zustand oder Ressourcen einzugehen. Sie sind für mich deshalb der default – und erst wenn ich deutliche Hinweise habe, dass Daten aggregiert werden sollten oder ein Form-Destillat hilfreich wäre, rücke ich davon ab.
Klassen als Aggregationen von Daten
Bisher war nur von der Abstraktion rund um Logik die Rede. Klassen integrieren Klassen, die Funktionen aggregieren, die Funktionen integrieren, die Logik integrieren. Und was ist mit den Daten?
Mein Blick war bisher vor allem auf Logik und Funktionen gerichtet, weil ich glaube, dass wir Software von ihrem Verhalten her denken sollten. „Was soll Software tun?“ ist die zentrale Frage. Welche Funktionalität und welche Effizienz soll sie haben? Dafür müssen wir Logik finden und zu Funktionen abstrahieren und die dann weiter zu Klassen abstrahieren.
Daten sind zwar die andere Seite der Softwaremedaille und insofern auf Augenhöhe mit Verhalten, doch sie stehen für mich nicht am Anfang von Analyse und Entwurf, jedenfalls nicht jenseits des Offensichtlichen. Ich glaube nicht, dass wir uns einen Gefallen tun, wenn wir auf Anforderungen wie Trüffelschweine losgehen und Datenzusammenhänge ausschnüffeln. Daten folgen Verhalten selbstverständlich und in bekömmlichem Maße, eben so, wie sie gebraucht werden.
Am Ende gilt es dann aber natürlich auch, für Daten Abstraktionen zu finden. Welche Daten haben etwas gemeinsam und sollten in einer Klasse aggregiert werden?
Das Beispiel gibt in dieser Hinsicht leider nicht so viel her. Dennoch habe ich versucht, ein bisschen Datenabstraktion zu betreiben. Herausgekommen sind diese beiden Klassen, die ich dann auch physisch im Projekt separiert habe:

Das hat vor allem zu einem Umbau am Parser{} geführt:

Dessen Verantwortlichkeit ist geschrumpft - oder besser: fokussiert. Seine Aufgabe besteht nun einzig darin, einen Text in Zeilen und Worte zu zerlegen. Die entstehenden Daten liefert er nicht mehr in generischer, offener Form als IEnumerable<string[]>, sondern in einer speziellen Datenstruktur Text{}, die aus Line{}-Objekten besteht, die wiederum Worte enthalten.
Klassen als Integrationen von Daten
Durch die Aggregation sind Daten klar mit Bedeutung aufgeladen und können nun auch passende Funktionalität beigeordnet bekommen. Was vorher der Parser geleistet hat, ist zum Teil in die Datenobjekte gewandert. Die operieren damit auf sich selbst und machen es Nutzern bequemer. Davon profitiert die Domänenlogik in Stats{}:

Die wünscht sich nun einfach etwas von einem Text{}, statt die Daten selbst zu analysieren. Eine Anwendung des Tell, don’t ask (TDA) Prinzips. Bei umfangreicheren Datenstrukturen ist damit natürlich mehr zu gewinnen: Konsistenzprüfungen und Navigation in Daten sind Funktionalitäten, die sich sehr gut eignen, um mit Daten in einer Klasse verbunden zu werden. Das ist Abstraktion durch Integration, weil eine Einheit entsteht, bei der nicht jeder Nutzer immer wieder alle Feinheiten der richtigen Bedienung beachten muss.
Das ist eine so typische Situation in der Objektorientierung, dass Sie ausrufen mögen, Integration stehe doch im Vordergrund der gemeinen Objektorientierung. Ich hatte ja etwas anderes behauptet in meinem vorhergehenden Artikel.
Doch ich bleibe dabei: Dass Funktionen mit Daten in Klassen gebündelt werden können, ist noch kein Zeichen für integrierendes Denken. Es kommt darauf an, warum und wie man es macht. Schon wenn die Unterscheidung zwischen Klassen, die Daten sind, und Klassen, die Daten haben, nicht getroffen wird, fehlt es an Differenzierung.
Text{} und Line{} sind ganz bewusst als Klassen ausgelegt, die Daten sind, d.h. ihr Zweck ist es, Daten zu aggregieren und ggf. sogar zu integrieren. Die Daten sind nicht dort, weil sie eine Gemeinsamkeit von Funktionen darstellen; sie sind kein zu verbergender Zustand. Deshalb können sie auch offenliegen. Eine Datenstruktur verbirgt ihre Struktur nicht. Sie zu kapseln wäre wider ihren Zweck.
Deshalb darf der Zweck einer Datenstruktur auch nicht überladen werden mit Funktionalität. Er muss fokussiert bleiben auf das Strukturieren von Daten. Funktionen sind hier sekundär und helfen lediglich der Strukturierung.
Anders bei Klassen, die Daten haben. Bei ihnen stehen die Funktionen im Vordergrund. Daten bilden zwischen ihnen ein Bindeglied; sie sind quasi notwendiges Übel, weil sie die Testbarkeit der Methoden herabsetzen.
In Bezug auf diese Daten sind Klassen lediglich Aggregationen. Ihre eigentliche Funktion: die Aggregation von Funktionen, die Integrationen sind. Solche Klassen sollten keine Daten veröffentlichen. Die sind lediglich gemeinsame Details der aggregierten Funktionen.
Sie sehen, Klassen als Integrationen sind kein Selbstgänger. Deshalb glaube ich, dass mehr Differenzierung bei den Abstraktionsarten nötig ist.
Anwendungen als Aggregationen von Funktionen
Zum Schluss noch einmal zurück zu ganzen Anwendungen. Die sind doch nicht nur Integrationen von Logik und Funktionen, sondern auch Aggregationen.
Anwendungen bieten ihrer Umwelt eine Reihe von zusammengehörigen Funktionen an, die auf die eine oder andere Weise getriggert werden können. Dann verhält sich die Software, indem sie Input in Output transformiert.
Im Beispiel ist das leider nicht gut erkennbar. Dort gibt es nur eine triggerbare Funktion: App.Run(). Vom Windows Taschenrechner über ihren Email-Client bis zu einem CRM oder einem online Game sollte es jedoch klar sein: Software macht über ihre Oberfläche mit den unterschiedlichsten Mitteln – Tastatureingabe, Mausbewegung, Menü, Buttons, Spracheingabe usw. – eine Vielzahl von Funktionen zugänglich.
In CRUD-Anwendung ist das ganz deutlich: Sie können die Listung von Daten triggern, Sie können ihre Aktualisierung, Löschung, Beschaffung, Neuanlage triggern. Für jede dieser Funktionalitäten gibt es genau eine Funktion als Wurzel, die irgendwie durch den Benutzer gestartet werden kann. Die erhält Daten als Input und erzeugt Daten als Output.
Anwendung sind mithin kaum etwas anderes als Aggregate von Batch-Programmen - die allerdings über gemeinsamen Zustand im Hauptspeicher (oder in einer Datenbank) verbunden sind. Das macht ja gerade den Zweck der Anwendung als Aggregat aus im Vergleich zu lose nebeneinander liegenden Batch-Programmen.
Durch die Zusammenfassung der Funktionen in einer Anwendung wird Aufwand gespart und Bequemlichkeit für den Benutzer erzeugt. Aus der Aggregation wird Integration. Der Abstraktionskreis schließt sich.