Tests als evolutionäre Kraft
Warum sollte Software eigentlich eine bestimmte Struktur haben? Weil sie mit dieser Struktur den Kräften, die an ihr wirken, am besten standhalten kann.
Dass Software gewünschte Funktionalität zeigt, hat nichts mit ihrer Struktur zu tun. Dass Software gewünsche Effizienzen zeigt (z.B. Performance, Sicherheit), hat in vielen Fällen auch nichts mit ihrer Struktur zu tun. Für Funktionalität wie Effizienzen ist lediglich Logik verantwortlich – und die braucht keine Struktur, um ihren Effekt zu entfalten.
Das ist leicht zu verstehen, wenn Sie daran denken, dass im finalen Maschinencode all Ihre schönen Strukturen ja nicht mehr zu finden sind und die Software trotzdem das gewünschte Verhalten zeigt.
Was verstehe ich unter Struktur? Elemente, die in Beziehung stehen. Also eine gewisse Anordnung von Dingen. Diese "Dinge" in der Software sind zunächst einmal Module, d.h. Funktionen, Klassen, Bibliotheken usw. Und die Beziehungen zwischen ihnen sind vor allem Nutzungsbeziehungen: ein Modul kennt ein anderes, um dort eine Dienstleistung zu nutzen.
(Datenstrukturen lasse ich hier ausdrücklich aus. Die arrangieren ja keine Logik, sondern eben Daten.)
Und was sind die Kräfte, die auf die Softwarestruktur wirken? Veränderungen. Softwarestruktur soll Code wandelbar machen.
Wandelbar ist Code, wenn er leicht verständlich ist, wenn sich Veränderungen zur Herstellung neuer Funktionalität oder Effizienz leicht anbringen lassen und wenn man leicht feststellen kann, ob das Neue schon korrekt implementiert ist wie auch das Alte immer noch korrekt arbeitet. Testbarkeit ist mithin ein Kriterium für Wandelbarkeit. Tests sind ein Teil der Kraft, die auf Softwarestrukturen einwirken.
In Bezug auf Tests habe ich mich nun gefragt, wie sich Strukturen dadurch verändern? Wie setzt Software Tests möglichst wenig Widerstand entgegen?
Mir scheint es da eine natürliche Entwicklung zu geben, quasi eine Evolution:
Ohne Prinzipien
Alles beginnt mit ein bisschen Produktionscode und einem Test:
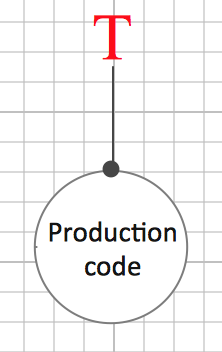
Produktionscode und Test enthalten Logik. Die Logik des Produktionscodes stellt das vom Kunden gewünschte Verhalten her. Hoffentlich jedenfalls ;-) Und die Logik des Tests prüft das.
Beide Logiken sind getrennt in verschiedene Module, zumindest unterschiedliche Funktionen. Es entsteht also schon eine minimale Struktur.
Ein Test reicht natürlich nicht aus. Der Produktionscode hat verschiedene Aspekte, die jede für sich überprüft werden wollen. Also sieht die Struktur zumindest so aus:
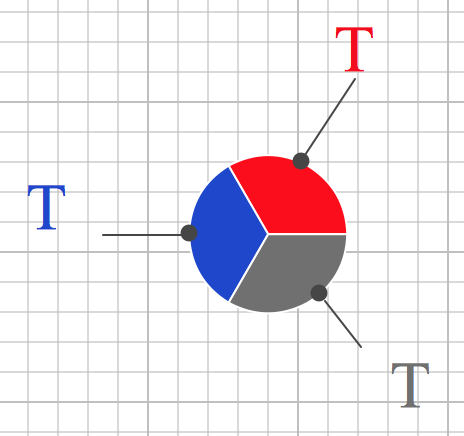
Alle Verhaltensaspekte sind in der Funktion des Produktionscodes zusammengemischt; die verhaltensindividuellen Tests setzen daher alle an der einen Funktion an.
Das kann man schon so machen... aber dann ist es halt kaum möglich, wirklich nur einen Aspekt zu testen. Die Logik aller anderen Aspekte wird in der einen Produktionscodefunktion immer mehr oder weniger mit durchlaufen.
Mit IoC
Um gezielter Aspektlogik testen zu können, wird empfohlen, das Prinzip Inversion of Control (IoC) anzuwenden. Dadurch lassen sich im Test gezielt uninteressante Aspekte ausblenden, indem man sie mit einem Mock/Stub/Fake ersetzt.
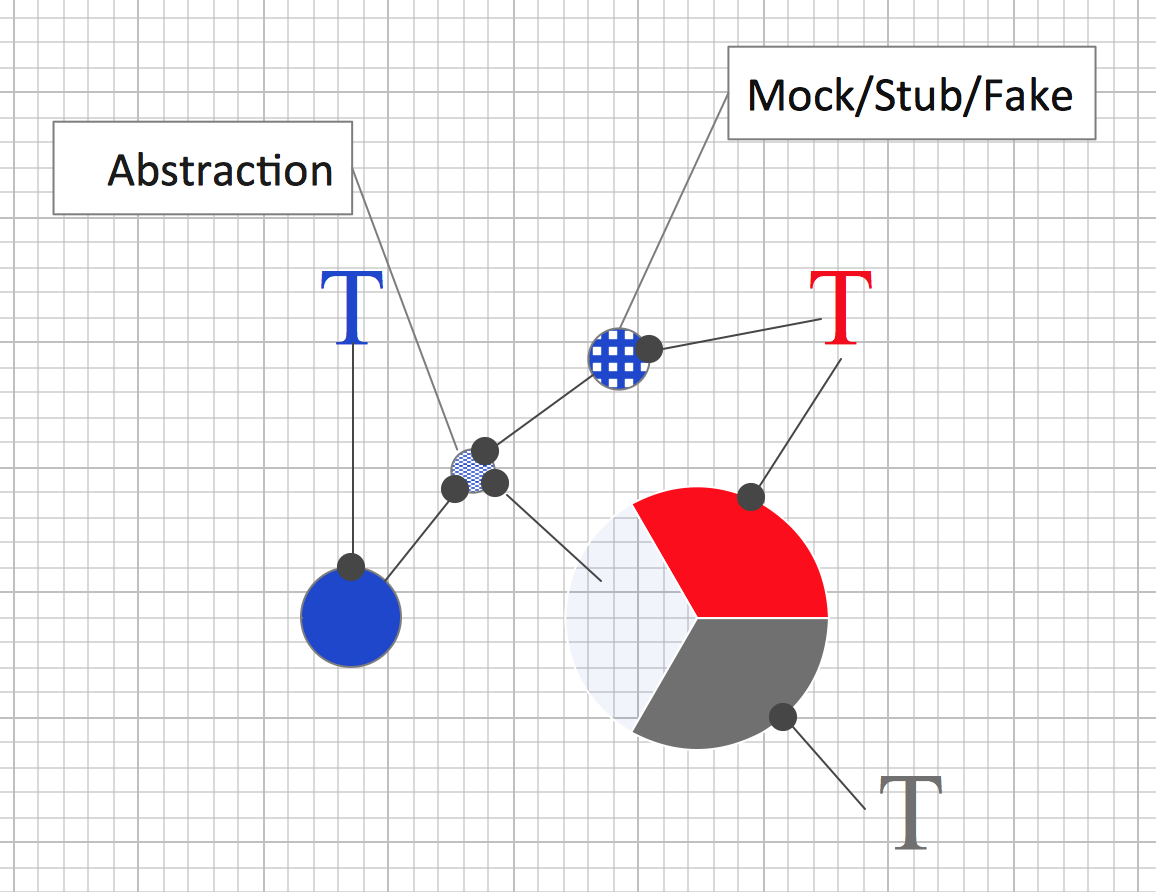
Der Produktionscodeaspekt wird ausgelagert in eine eigene Funktion und dort für sich getestet.
Eingebunden wird er zwischen den verbleibenden Aspekten in der ursprünglichen Funktion jedoch nicht durch direkten Aufruf, sondern über eine Indirektion. Die ursprüngliche Funktion kennt nur noch eine Abstraktion des ausgelagerten Aspekts, z.B. ein Interface, auf dem er eine Methode darstellt. Dieses Interface implementiert die Klasse, in die der Aspekte ausgelagert wurde.
Ebenso implementiert dieses Interface ein Mock/Stub/Fake, den andere Tests nutzen, um für sich den ausgelagerten Aspekt auszublenden.
Jetzt ist die ursprüngliche function under test (FUT) nicht mehr nur Behälter für Logik, sondern auch noch funktional abhängig von einer anderen Funktion. Die kennt sie zwar zunächst nur als Abstraktion; doch zur Laufzeit steht dann eine konkrete Implementation zur Verfügung (dependency injection).
Das kann man schon so machen... aber wie Sie sehen, wird das schnell recht unübersichtlich.
Die FUT enthält ja eine Mischung aus verschiedenen Logikaspekten. Um jeden davon isoliert testen zu können – eine Voraussetzung für feingranulare Fehlersuche und Weiterentwicklung –, müssten alle anderen ausblendbar sein.
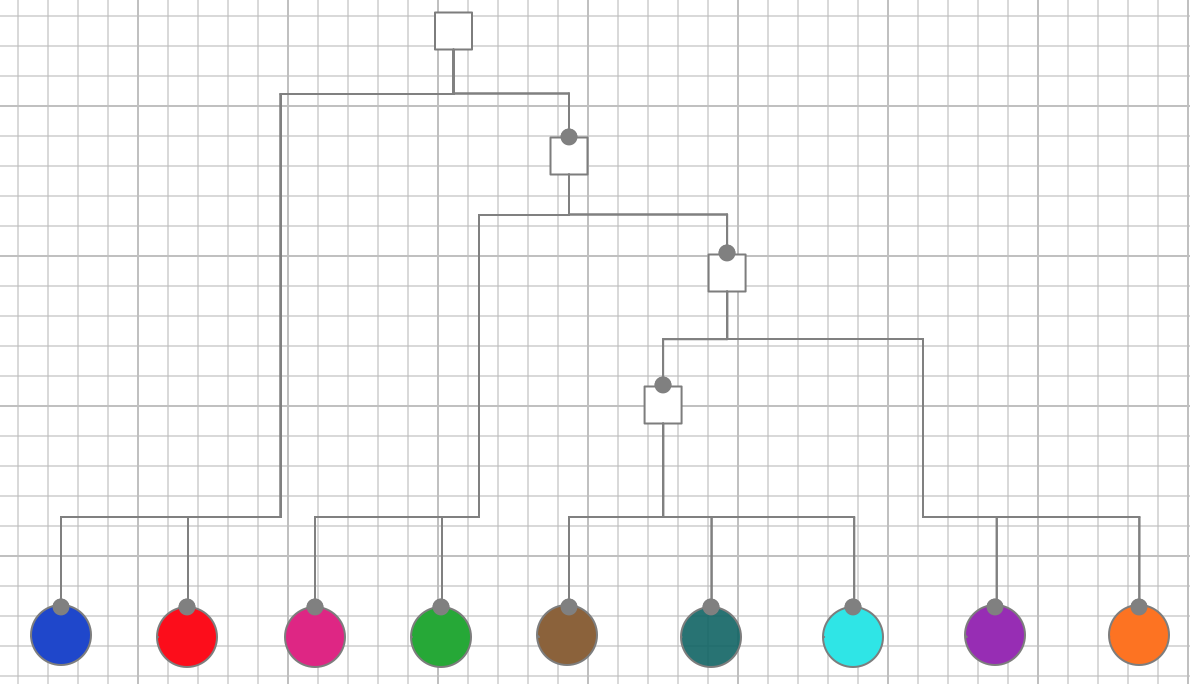
Eigentlich. Das macht aber niemand. Man behilft sich mit einem Gemisch. Manche werden über IoC ausblendbar gemacht, andere verlagert man nur in eigene Funktionen, ohne sie ausblenden zu können, wieder andere bleiben vermischt in der FUT. Am Ende sieht die Struktur von Software so aus:
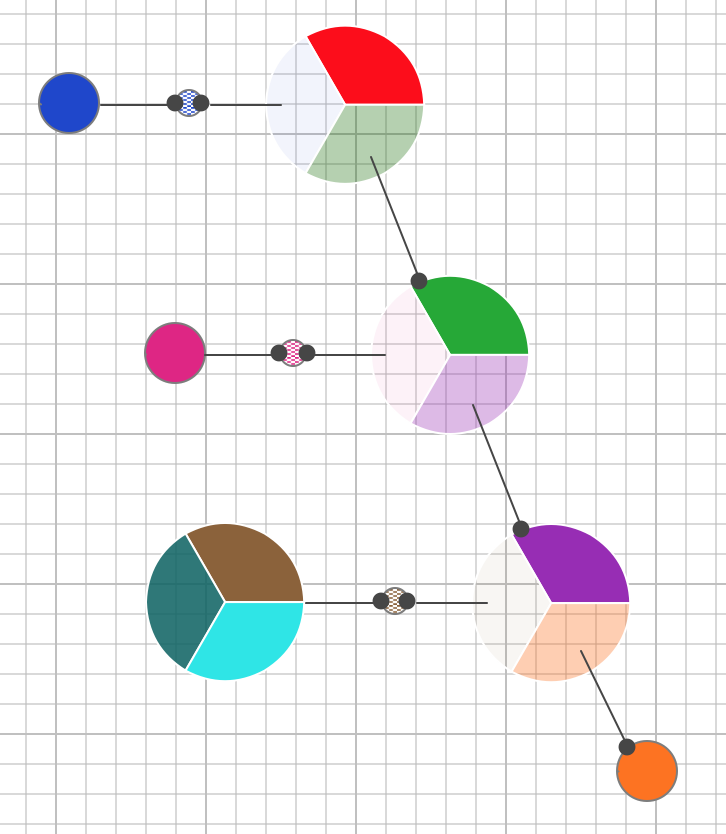
In tiefen Bäumen von Funktionsaufrufen sind auf jeder (!) Ebene Logik und (!) funktionale Abhängigkeiten zu finden. Manchmal sind die funktionalen Abhängigkeiten durch IoC/DI entschärft, manchmal aber auch nicht. Es ist eine bunte Mischung. Aber nicht unbedingt eine durchweg gut verständliche. Und auch die Testbarkeit ist nicht durchweg gut. Denn konsequente Entkopplung mittels IoC/DI wäre schlicht zu umständlich.
So hat man sich also in den letzten Jahren beholfen. Ist damit aber das Ende der Evolution von Codestrukturen erreicht? Ich glaube, nicht.
Mit IOSP
Prinzipien wie IoC und Praktiken wie dependency injection sind kein Selbstzweck. Man kann sogar sagen, sie führen zu Verschwendung. Denn mehr Indirektion ist ja nicht per se wünschenswert. Deshalb darf man den kritischen Blick auch auf ehrwürdige Prinzipien nicht verlieren.
IoC ist ein Mittel, um ein Problem zu lösen. Einerseits ist das eine gute Sache. Andererseits ist bei jeder Problemlösung zu fragen, wie hoch in der Problemhierarchie sie ansetzt. Ist sie eine Symptomkur oder geht sie das Wurzelproblem an?
Ich wende einfach mal die Five-Why-Methode an, um die Problemhierarchie zu beleuchten:
- Warum ist IoC ein so prominentes Prinzip? Weil es hilft, bei Tests Funktionen auszukoppeln.
- Warum ist es wichtig, in Tests Funktionen auskoppeln zu können? Weil nur so Logik getrennt testbar ist.
- Warum ist denn aber Logik überhaupt getrennt testbar zu machen? Weil sie auf jeder Ebene der tiefen Funktionsbäume vorhanden ist und dabei ganz unterschiedliche Aspekte (Verantwortlichkeiten) in Funktionen zusammengefasst werden.
- Warum wird Logik unterschiedlicher Aspekte in Funktionen zusammengefasst?
Ja, was ist die Antwort auf die vierte Frage? Für mich lautet sie: Weil man es kann und es so einfach ist und man nicht recht weiß, wie Logik sonst hierarchisch strukturiert werden sollte. So war es halt immer schon.
Das finde ich zwar einerseits verständlich, doch andererseits sollte das doch nicht dauerhaft die Antwort bleiben, oder? Das wäre ein bisschen bequem. Die Testbarkeit von Funktionsbäumen ist schlecht, also verschreibt man IoC. Doch das ist nur eine Symptomkur. Das Wurzelproblem, nämlich das Vorhandensein von Logik auf jeder Hierarchieebene wird damit nicht angegangen. Warum nicht?
Ich glaube, weil man es nicht gesehen hat. Man hat nicht erkannt, dass die üblichen Funktionshierarchien auch mit IoC immer noch das Single Responsibility Principle (SRP) verletzen.
Eine Methode, die einerseits Logik enthält und andererseits Logik in anderen Funktionen aufruft, also funktional abhängig ist, hat zwei (!) Verantwortlichkeiten. Die eine Verantwortlichkeit steckt in ihrer eigenen Logik. Die andere Verantwortlichkeit jedoch besteht darin, andere Funktionen geeignet mit der eigenen Logik zu einem Ganzen zu integrieren.
Ja, das sind für mich zwei deutlich eigenständige Verantwortlichkeiten. Die eine stellt Verhalten her, sie operiert auf Daten (Logik), die andere verbindet Verhaltensteile zu einem Gesamtverhalten (Integration).
Beide Verantwortlichkeiten getrennt zu sehen und auch im Code zu trennen, halte ich für so wichtig, dass dem ein eigenes Prinzip gewidmet sein sollte. Ich nenne es das Integration Operation Segregation Principle (IOSP).
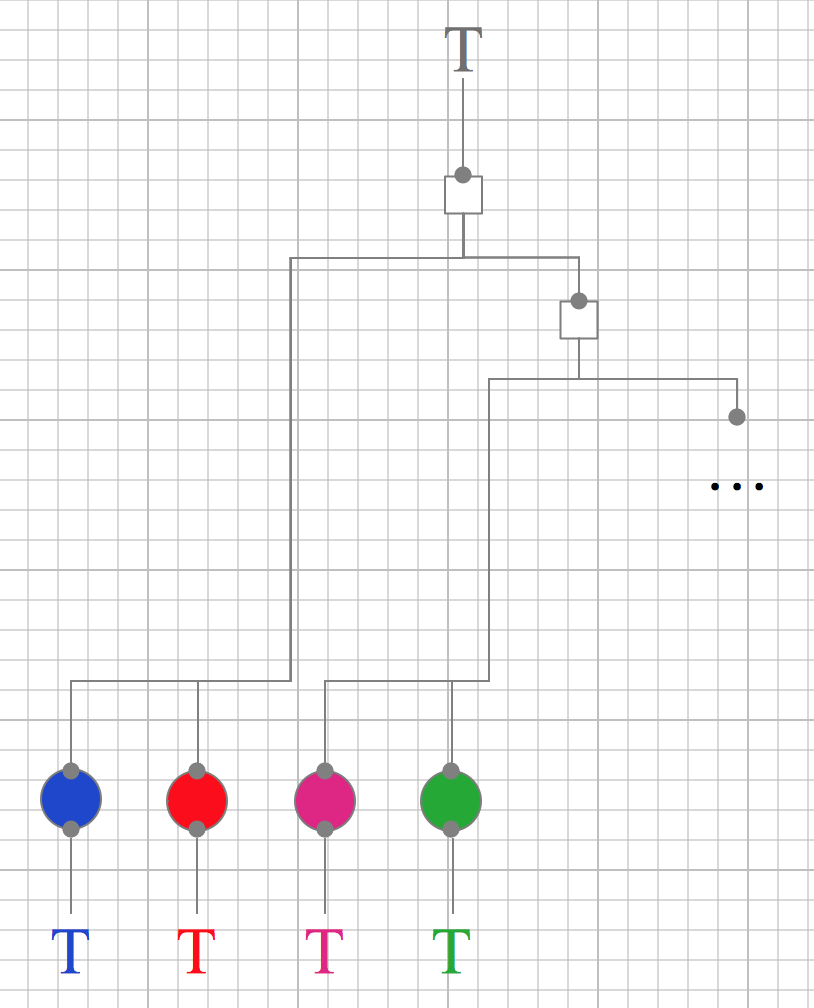
Und wie würde so eine Funktionshierarchie nach dem IOSP aussehen? Hier die Refaktorisierung des obigen Funktionsbaums:
Sie sehen hier alle Farben der Logik wieder – nur steckt sie dieses Mal ausschließlich in den Blättern des Baumes, den Operationen. Die darüber liegenden Knoten sind "ausgeblutet". Es gibt keine Logik-"Pizzastücke" mehr, sondern nur noch leere Rechtecke. Deren Aufgabe ist ausschließlich die Integration von "ausgelagerter" Logik und anderen Integrationen.
Die Verantwortlichkeiten Integration und Operation sind konsequent getrennt. Entweder integriert eine Funktion oder sie operiert, d.h. enthält Logik.
Damit sind funktionale Abhängigkeiten verschwunden!
Operationen rufen keine anderen Funktionen auf. Dort kann es also keine funktionalen Abhängigkeiten mehr geben.
Integrationen hingegen rufen andere Funktionen auf. Allerdings enthalten sie selbst keine Logik mehr. Nichts in ihnen ist also abhängig von der Logik, die in aufgerufenen Funktionen stecken mag.
Und was hat das für einen Effekt für das Testen?
Operationen sind ganz einfach zu testen. Es muss dabei nichts mehr durch Mock/Stub/Fake ersetzt werden.
Integrationen wären immer noch schwer zu testen. Aber im Grunde müssen sie nicht getestet werden. Denn darin steckt ja keine Logik. Was wäre also zu testen? Die reine Integrationsleistung. Die jedoch ist so simpel, dass in den meisten Fällen eine visuelle Überprüfung (code review) genügt.
Ultimativ muss aber natürlich doch das Ganze überprüft werden. Es ist also mindesten ein Test an der Wurzel nötig. Doch der testet ja ebenfalls nur die Integrationsleistung, nicht die Korrektheit der Operationen.
Sieht das einfacher aus als der Testverhau mit IoC? Das will ich wohl meinen.
IoC hat seinen Wert. Auch in einer nach IOSP strukturierten Codebasis wird es hier und da Operationen oder Integrationen geben, die man von Aufrufern mittels IoC entkoppeln will. Aber der Bedarf dafür sinkt drastisch.
Dadurch steigt mit IOSP die Übersichtlichkeit des Codes. Das Rauschen der Indirektionen nimmt ab. Und die Verständlichkeit von Funktionen, die sich auf die Integration konzentrieren ist sehr hoch.
Software strukturieren für Tests
Ich sehe die Evolution der Grundstruktur von Code als nicht abgeschlossen an. Er muss sich dem wachsenden Druck automatisierter Tests anpassen, es muss noch leichter testbar werden.
Mit IoC war ein Schritt in diese Richtung getan. Doch auch wenn der Code dadurch testbarer wurde, verlor er andererseits dadurch eine Eigenschaft: Übersichtlichkeit. Indirektionen lediglich zum Zweck des Testbarkeit einzuziehen, war nur eine Symptomkur.
Mit IOSP kann nun ein zweiter Schritt getan werden. Raus aus den verrauschenden Indirektionen, weg von den Diskussionen um Mock-Frameworks hin zu Code, der ohne weitere Hilfsmittel einfach zu testen ist. Weil das Wurzelproblem der schlechten Testbarkeit gelöst ist: die Vermischung von Verantwortlichkeiten - und zwar der Verantwortlichkeit "Verhalten herstellen" und "Integration von Verhalten zu etwas Größerem".
Ich halte das für eine natürliche Entwicklung der grundsätzlichen Codestruktur. Wenn gute Abdeckung mit automatisierten Tests alternativlos ist, um zügig durch Veränderungen voranschreiten zu können, ohne Angste vor Regressionen zu haben, dann ist die Strukturierung nach IOSP eine konsequente Anpassung.