TDD - How It Can Be Done Right
TDD has gone wrong. It was well intentioned and is a great technique, but many developers who are trying it are not experiencing the promised benefits. How come?
This question was asked and answered by Ian Cooper in a DevTernity talk in 2017. Watch the video here, if you like. It’s worth pretty much all of the 63 minutes.
I came across it through a tweet by Robert C. Martin:
And after a couple of minutes into that talk I even followed his advice and took notes.
It’s these notes and some thoughts I’d like to share with you in what follows. I liked the talk very much. I’m agreeing with a lot of what Ian Cooper said. However, a couple of things were missing or not said as explicitly as needed for my taste.
I spare you a paraphrase of why and where TDD went wrong according to Ian Cooper. Watch the first 20min of his video instead, if you like to know. Rather let me cut to the chase by telling you what he thinks can be done about it:
- Avoid testing implementation details, test behaviours.
- Test only the public API.
- Run tests in isolation.
- Get red tests to green as fast as possible.
- Think about design and clean code only during the refactoring step of TDD.
That’s it. Five easy steps to TDD bliss. No more red tests after refactoring. No more mock chaos. No more doubled or tripled coding time just because of tests.
Or maybe it’s not that easy? Because if it where and always already had been in the book - Kent Beck, TDD by Example -, then why could TDD possibly have gone wrong?
So here’s my 2c why it’s been so difficult to follow these steps.
1. What’s this thing to test: behaviour?
The goal of requirements analysis is to define the desired behaviour of software. How you do it, whether you follow a formal process or „just talk to the user“ is of less concern, I think. However, of utmost importance is how the results are documented. How can desired behaviour be specified unambiguously?
To answer that question you’ve to have an idea of what behaviour is in the first place. Here’s my definition:
Software shows behaviour by transforming input data (request) into output data (response) while using further data from resources.
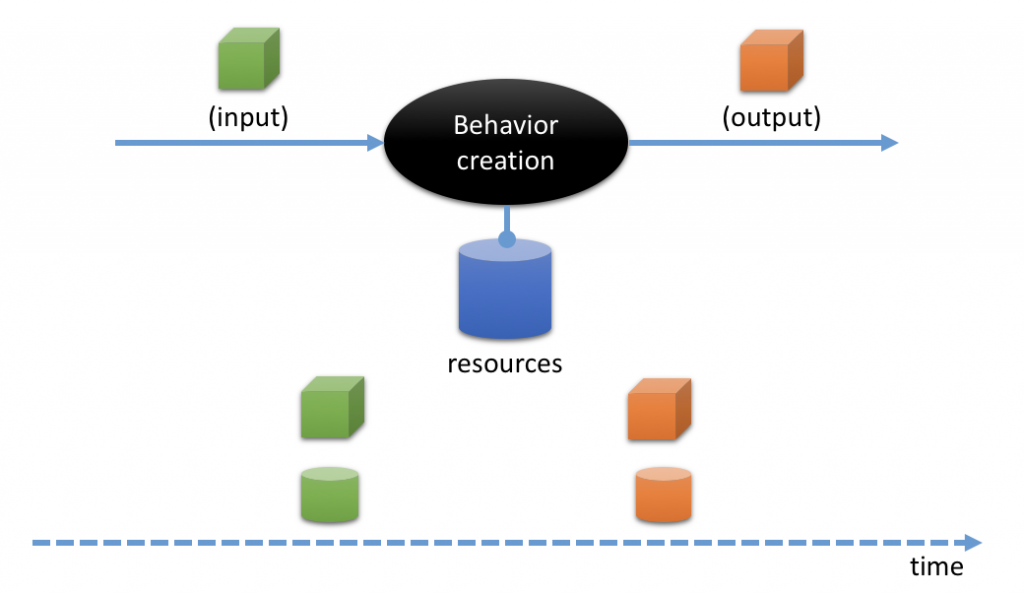
Software behaviour is expressed only in data. You might think it has to do with user experience of user interfaces, but I disagree. User interfaces are just the means to make data tangible, to enable the user to input data, trigger behaviour, and view output data.
User interfaces are a detail. They look this way today, but different tomorrow. You use this technology today, but another one tomorrow. The behaviour essentially is unaffected by that.
The what of behaviour thus should clearly be separated from the how of behaviour. Think of a behaviour layer beneath an outer user interface layer of software.
User interfaces are about the how or looks of triggering and watching behaviour. But they don’t define the what of behaviour.
Sure, these two aspects are easily and often entwined. But I recommend to clearly separate them as much as possible. Otherwise it will be very hard to systematically create the desired behaviour and also have tests for it.
From that it should be clear that the typical user story is not enough. It’s neither a description of the how nor a specification of the what. It’s, well, just a nice story - which has to be listened to and interpreted. Precision looks different.
But precision is important, I think. „Programming is about details,“ says Robert C. Martin. And how exactly input, output, and resources should be structured and filled to be considered good behaviour are details, important details. Precision is needed to get it right.
The part of the system to create a certain behaviour thus needs to provide means to feed it data - input as well as resources in a certain state. And it needs to provide means to receive data from it, output as well as resources in a changed state.
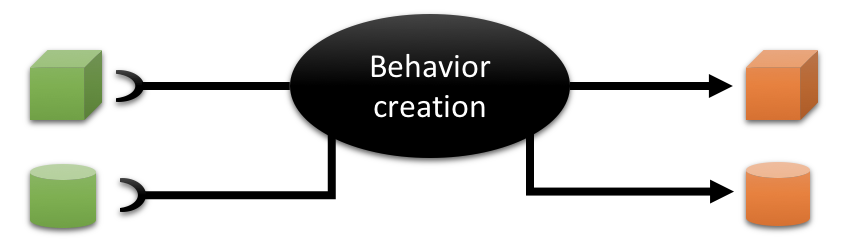
That’s all you need to start with TDD. As you can see this hasn’t to do with DIP, IoC, any test framework or what not. It’s about focussing on behaviour, i.e. something tangible to the user, something the user has an opinion about and an can give feedback on.
TDD starts with compiling a list of desired behaviours - which then of course need to be encoded so they can be checked automatically.
Without suggesting any specific tool such a compilation could look as simple as this:
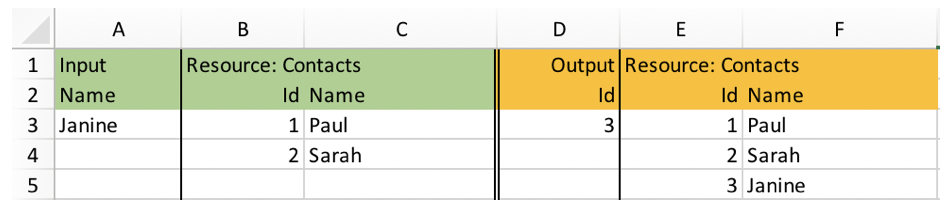
Sure, if data becomes more structured and larger in size and number Excel won’t do anymore. But what needs to be done stays the same: If you want to know what the system to build is supposed to do don’t be content with plain text explanations or pretty UX prototype pictures. You need to gather explicit data to describe the behaviour.
I’d even argue that as long as users/PO cannot or do not want to provide you with such exact data, you should not start into the next phase of programming (be that designing or coding). The reason is simple: you don’t know when you’ll be finished. You’ll stay more dependent on the user/PO than necessary which will lead to frustrating roundtrips and rework.
It’s that simple: no data, no tests. Is that what you want?
Behaviour defining data is crucial. What’s not crucial is how you automate tests of the specified behaviour. In my view „developer tests“, i.e. tests using a test framework like NUnit or JUnit are sufficient. As Ian Cooper says: users won’t really use testing tools themselves. They are not interested in learning the ins and outs of Fit or Cucumber. So you’re stuck with encoding the data into tests yourself anyway.
As long as behaviour specific data could be elicited it should be easy to map it free of errors into a format you can use in developer tests. The user/PO has to trust you anyway. It thus should be sufficient to present him/her with a list of green and red tests to document the progress of the implementation.
Forget about the tools for a moment. Focus on not letting go of users/PO until they actually commit to a specific, automatically testable behaviour description.
2. Where to find the „public API“ in a user story?
In order to not paint yourself into a corner with a host of tests focus on just keeping tests on the „public API“. That’s very good advice from Ian Cooper. I wholeheartedly agree. But what’s the „public API“?
Unless you’re tasked with writing a library with a specific API it might not be obvious what the „public API“ ist.
In my view an API defines the surface of a software system. It’s what’s visible to clients of the system; it’s what has been explicitly designed for consumption.
By „consumption“ I mean requesting behaviour. The „public API“ (or API for short, because APIs to me are public by definition) defines how requests can be send to the software system, and how responses are delivered back to a client. You see: APIs are about the how of behaviour.
An API thus can have very different shapes. I would not consider a user interface to be an API because it’s not designed to be consumed by software but by humans. However, a web-service answering to REST calls offers an API. Or a micro-service subscribed to a RabbitMQ queue offers an API. Or an ETF-service listening for changes in the file system offers an API.
As much as I agree with Ian Cooper (or Kent Beck) I see two difficulties with testing just the „public API“ of software:
- Not all software has a „public API“.
- A „public API“ can take on very different shapes.
I’ve thus come to the conclusion to not test the „public API“ itself. At least as long as the system to build isn’t a library.
With a library the API is easily accessible: it’s just a list of public functions. (In OO software those functions are methods on public classes.) And functions are simple to test with a test framework like NUnit or JUnit.
To me the „public API“ of a non-library system is just a detail. It’s pretty much non-essential and should not stand in the way of testing. Any „interface technology“ - be it a user interface technology like WPF or a service interface technology like ASP.NET MVC for REST calls - is comparatively hard to test and quite likely to change. I thus prefer to keep the code layer involved with such API technology as thin as possible - and don’t see much need to put it under full test automation.
I don’t want to test stuff that’s highly dependent on already tested stuff. ASP.NET MVC is doing its job fine, I trust. Why should I test a class tightly coupled to some framework? No, my job is to isolate such dependencies as much as possible from the really important code. That’s a very basic architectural principle to me. That way I keep the decision for a particular technology at bay or at least reversible.
Instead of the „public API“ I recommend to look for the „API behind the API“. And that’s true for all interfaces, be that APIs or UIs. My view of a software system is like this:
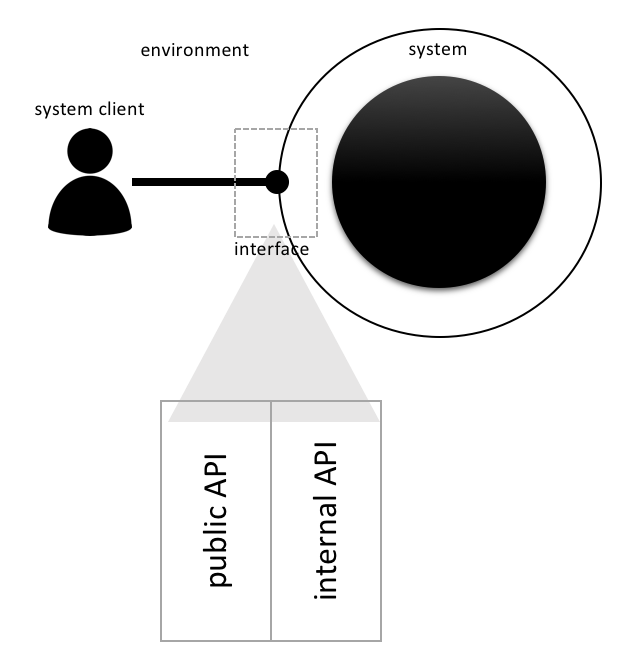
The interface to the environment consists of two layers: the outer layer is what clients of the system in the environment - be that human users or other software systems - directly interact with. That’s where special interface technology is involved, e.g. WPF, ASP.NET MVC, RabbitMQ etc. etc. That’s the real „public API“ - but it should be just a very thin layer.
Behind this outermost layer, the „public API“, then lies a second API layer, the „internal API“. It’s still an API in that its shape is determined by the needs of the environment. But it’s interface technology agnostic. It does not have a clue whether it gets triggered by a human user through a user interface or another software system by a message over TCP.
Take this trivial web-service for example:
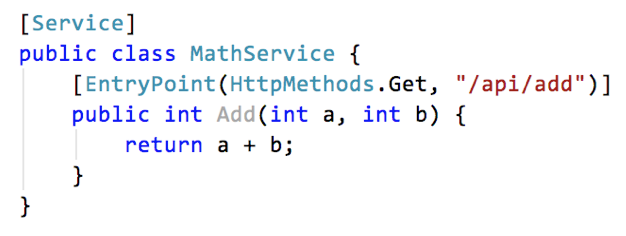
It can be tested with a call to http://localhost:8000/api/add?a=1&b=41 using curl or Insomnia or some REST client framework. But I’d rather not do an automatic test by that means. Much too slow and cumbersome.
Instead I’d separate the service into public and internal APIs like this:

And then I’d just put InternalAPI.MathService{} under permanent automatic tests. (Note how the internal API is static. No need to make its Add() an instance method; static methods are easier to test. But that’s a topic for another time. The REST framework requires service methods to be non-static, though; an implementation detail.)
Sure, this is a trivial example, but I hope you get my point: the internal API is devoid of any hints as to which concrete technologies are needed for publication. That’s what makes it easy to test.
No need to test if the framework which provides [Service] and [EntryPoint] is working correctly. And whether Get or /api/add are correctly applied can easily be checked once manually (or semi-automatically) - with all the dependencies hanging down from that entry point into the software system. No need for mocking.
What this boils down to for me is: Testing the „public API“ always means just testing an interface technology independent library. It’s just about regular public functions (regardless whether they are located in modules or classes).
It’s the internal API which has to provide means to send requests and receive responses. And the natural way to do that for programmers is… calling a function.
Preferably that’s a single function per test case. A single function should be responsible for creating each behaviour. But maybe some other functions have to be called to set up the input and the initial resource state, and some other functions have to be called to retrieve the response and the final resource state. The fewer functions the better, though, I think.
Such an internal API is not only easier to test than a public API with all its technological dependencies. An internal API also can be reused with different public APIs. It’s simply a matter of applying the SRP: serving the environment is a responsibility different from actually creating some behaviour. Behaviour creating is about data transformation. Publication is about technology. Different logic, different technologies, different rate of change.
And never mind that the user/PO does not know how to use an internal API. Since he/she is not involved with test frameworks in the first place he/she does not care what exactly you feed the test data into and where you retrieve results from. He/she is concerned about green vs red tests only.
Sure the public part of the API is about details which also have to be correctly implemented. You need to check that. But what I’m concerned with here - and so is Ian Cooper, I’d say - are regression tests of the bulk of your software accessible through some form of API. It’s not the API itself, but what’s behind it.
The API to put under test is a list of functions hidden in User Stories and Use Cases. Look for where the environment triggers behaviour, try to come up with one internal API function to deliver each behaviour, then apply the collected sample behaviours to the internal API function in automated tests.
This is how in the end it looks:
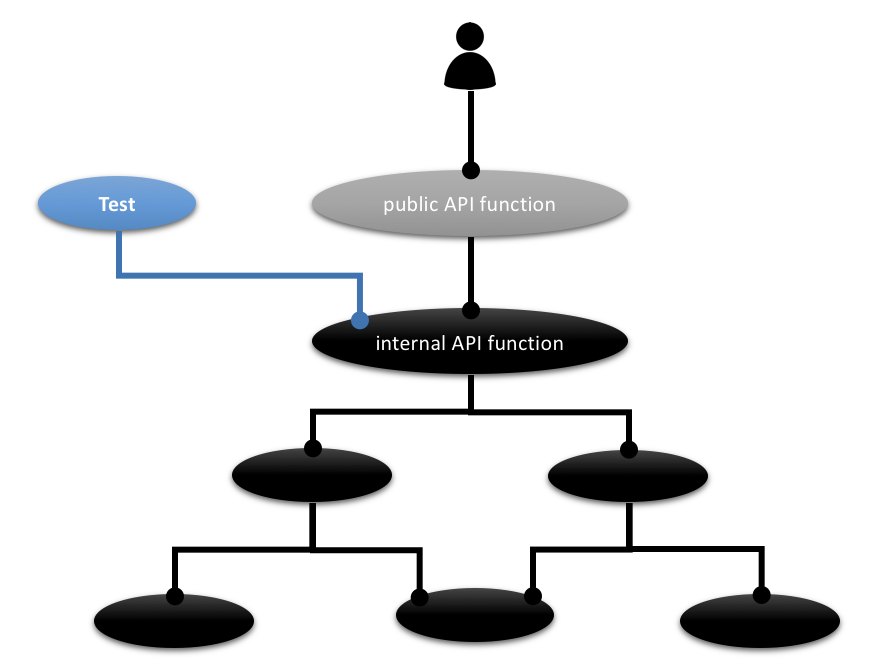
Most tests to stay should exercise your software system from the outside. That way you are free to refactor it on the inside.
3. How to isolate without so many mocks?
Yes, tests should be run in isolation. No leftovers from a previous test should influence a later test. But doesn’t that lead to heavy mocking?
I don’t think so. Mocking should not be the default for test isolation. The reason is simple: Mocking is not the real thing.
Mocking hides what’s going on in a software system. And it introduces its own source of bugs.
Mocking is a form of waste. It’s doing something again in a fake way, which has been done already in a real way.
Don’t get me wrong: Mocking is a useful technique - sometimes. It should be applied carefully and in small doses.
Avoid broad brush isolation of everything from everything else because you want to put everything under permanent test. It’s a recipe for disaster.
Test isolation first and foremost means data isolation. The output and/or final resource state of one test should not be used as input and/or initial resource state of another test. You’d lose the ability to run just selected tests or run tests in any order you like. (Suggestion: Look for test frameworks which can run tests in random order; that way you quickly get feedback whether you really isolated your tests from each other.)
It’s ok to have several tests share a common context. But the effects of one test on that context should not carry over to the next test.
Test isolation thus is less about functional mocks, but more about data. As long as you ensure data to be always „fresh“ and specific for a test according to the behaviour as specified you should not mock functionality. Your tests on the internal API should exercise as much of the function stack as possible. You need to have the parts of your program to actually collaborate. Your tests are experiments to confirm (or falsify) your hypothesis that all you’ve coded actually creates desired behaviour.
To me that’s the goal: no mocks, only comparatively few tests at the outside to cover the whole functional stack.
However… sometimes you need to replace the real thing with a stand-in. Sometimes the real thing simply is too expensive during tests. It’s the same in movies: the star actor is usually not used in dangerous action sequences or during boring lighting and camera adjustments.
If a test with real data becomes too expensive or cumbersome, then sparingly use some form of mocking. Replace an RDBMS with file system persistence or an in-memory database. Replace a TCP-connection with data from a file system or whatever. Become creative. That’s fine.
But again: I suggest you replace the least possible amount of code. Mocking mostly should happen on the boundary of a software system. Again, there is an interface:
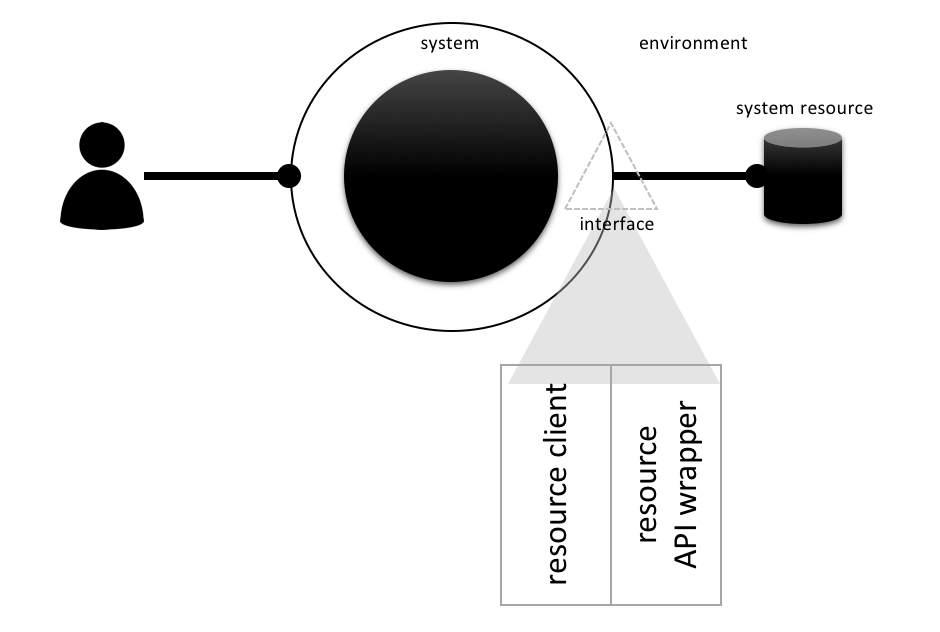
Resources are accessed through their public API. In order to be able to replace them when needed this API needs to be wrapped by an adapter and not be used directly all over the place within the software system. Resource clients should always go only through this adapter.
With this adapter in place mocking can be done. Still, I wouldn’t recommend it, but it’s possible with relatively little pain.
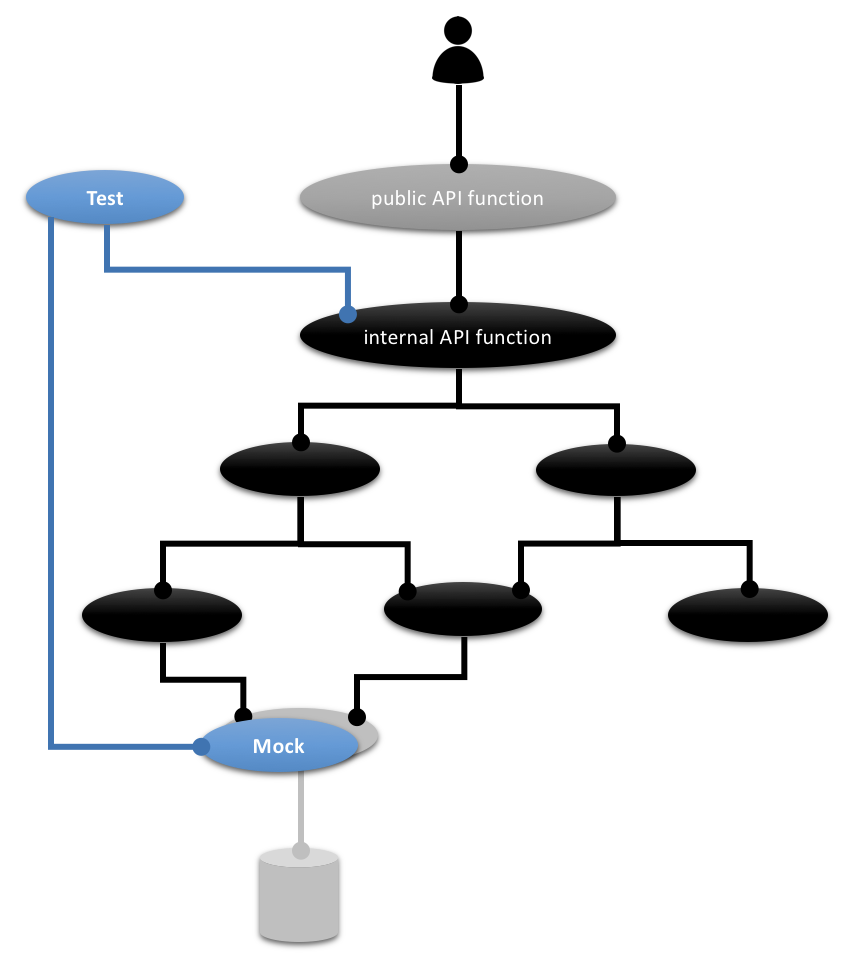
DIP + IoC help you with that. It’s no rocket science. A full blown dependency injection container is not necessary in my experience. Try to avoid as much additional complexity as possible which is inevitably introduced by the desire for mocking.
Probably the best advice with regard to test isolation is: avoid state. State as in-object state, but also persistent state.
Sure, in the end your systems will need to persist data. But that should not mean large parts of your systems should know about that. Making testing easier is not only about isolation and wrapping resource APIs. It’s also about not even to depend broadly on the resource wrapper at runtime.
4. Why is green so elusive?
In TDD green is supposed to be achieved by the simplest means possible. Follow the KISS principle. Ian Cooper emphasises that green does not equal clean, though. In the green phase of TDD don’t try to write beautiful timeless code. Just focus on getting the job done. Focus on satisfying the behaviour expectation specified by the test.
That’s good news, I’d say. It’s an application of the SRP to your brain. Avoid multitasking. During green you’ve one responsibility only to live up to: create functionally correct code.
Unfortunately my own experience as well as that of developers I watch in my trainings is that even dirty code is not that easy to write.
Let’s not kid ourselves with degenerate test cases, e.g. checking input parameters for null. And let’s not kid ourselves with fake solutions, e.g. returning the expected result as a hard coded value. That’s procrastination at the micro level. It does not bring a real solution any closer.
What I mean are test cases to be satisfied with non-trivial code. This code often is elusive. Why’s that?
The problem to solve often is too big.
Take the „8 queen problem“ for example:
The eight queens problem is the problem of placing eight queens on an 8×8 chessboard such that none of them attack one another (no two are in the same row, column, or diagonal).
Here’s an example output from Wikipedia a software solution should be able to produce:
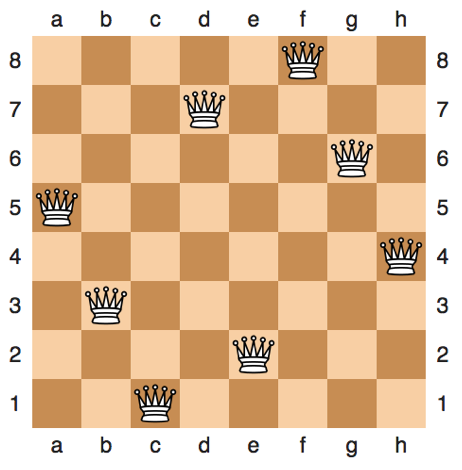
If the system to develop looked like this:
public class NQueensSolution {
public static int[] Solve(int numberOfQueens) { ... }
}Then an acceptance test for the above depicted behaviour could look like this:
[TestFixture]
public class NQueensSolution_tests {
[Test]
public void Acceptance_test() {
var result = NQueensSolution.Solve(8);
Assert.AreEqual(new[]{2,12,17,31,32,46,51,61}, result);
}
}Wouldn’t that be a valid, crystal clear requirement? Of course - but it’s a big one. It requires the full blown solution. If you had a hard time to come up with that even as very dirty code, I’d understand. And the point of TDD is to not even try.
Instead, find a simpler problem, a sub-problem hidden in the difficult big problem - and write a test for that first. Can the „8 queen problem“ be reduced to a „1 queen problem“? Not really. The point is to have multiple queens. (Never mind that Wikipedia is not excluding this case.) Then maybe 2 queens. No, not possible. 3 queens? Not possible. Ah, but with 4 queens it’s possible.
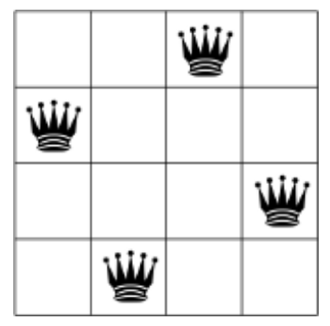
[TestFixture]
public class NQueensSolution_tests {
...
[Test]
public void Simpler_4_queen_problem() {
var result = NQueenSolution.Solve(4);
Assert.AreEqual(new[]{1,7,8,14}, result);
}
}But what now? Is that really, really a simpler problem? Sure, it’s less queens to place and a smaller board. But the fundamental problem stays the same. I say, the solution hasn’t come much closer.
So what else could you do to break down the difficult problem into simpler ones which can be solved by the system under development? Keep in mind it needs to be a problem which is „of the same kind“, just simpler.
If you take the „roman numeral conversion“ problem for example the „big problem“ could be to convert IV to 4. And if that’s too hard for you to tackle in full, then a sub-problem could be to convert VI to 6 (no subtractions). An if that’s still too difficult, start with converting I to 1 etc. (no addition, just single digits).
Each sub-problem is in and of itself a full problem (IV, VI, I are all roman numerals), just simpler in some regard. If you can decompose the user’s requirements into such kind of simpler requirements then all’s well with TDD. Work yourself incrementally from simple to complicated test cases.
To me, though, that does not seem possible with the „8 queen problem“. It’s always the full blown problem. There’s no way to approach the full solution incrementally. You either know the solution or you don’t.
And that’s my point: In real life problems don’t come packaged as nice little coding katas like the „roman numeral conversion“. You don’t really know how big they are. You cannot just look at required behaviour and derive simpler test cases from it.
Sure, the user/PO might help to classify behaviour. But in the end he/she is not concerned with difficulty. He/she just knows what kind of results should be produced. So you’re pretty much alone in TDD land.
My recommendation: always assume being confronted with an „8 queen problem“ - until you have evidence of the problem really being simpler.
That means: Diligently encode the acceptance test cases you came up with together with the user/PO. Always start with overall behaviour. Yes, even if that means those test cases will stay red for quite a while. Having some ambiguity tolerance helps to cope with that.
And then try to solve the problem. Yes, solve the problem without writing tests. Solving does not mean coding. It just means, you know how to transform input into output while using further data in resources. And that means you can state the explicit steps necessary. Again, no code is needed. Just steps, abstract steps, conceptual transformations.
Solving a problem without actually coding means modelling a solution.
How you find a model is a matter of creativity. But I know one thing: Your model must not be (imperative) code - because that would be in contraction with the meaning of model. Rather your model must just define partial transformations and their relationships from which a complete solution can be composed.
The originally required behaviour is created by a „the one big“ transformation. But since that’s too big a problem to tackle at once the overall transformation has to be decomposed into a number of partial transformations.
That’s a venerable problem solving technique but to me it seems as if many developers have forgotten about it.
TDD is great, but does not serve you a solution on a silver plate. You still have to come up with that yourself. Only when the problem is simple enough (see „roman numerals conversion“ above) you can expect incremental TDD tests to help hammering out the actual logic needed for behaviour creation.
As long as that’s not the case, though, don’t expect TDD to help. Do your homework.
That’s why I think green often is elusive: there is a misunderstanding. You think the problem is simple enough for TDD, but actually it’s not. After a few degenerate and fake tests you’re hitting a wall. No small wonder you then blame it on TDD to not be helpful. Wasn’t TDD supposed to guide you with tests to functional and clean code? Well, yes - but this requires the problem to be of a certain kind.
Unfortunately this does not get communicated well in most TDD demonstrations. And even „Growing Object-Oriented Software Guided by Tests“ (by Steve Freeman and Nat Pryce) falls short in this regard for my taste.
If you don’t want green tests to be elusive please look closely at the problems at hand. In most cases you’ll need to first decompose a comprehensive transformation into smaller, complementary ones. Maybe I can describe it like this: „Grow the function call tree from the root down guided by tests.“ Because that’s pretty much it, I guess: you start with a single function on the internal API which is required by the user as a root to direct requests at; and from there out grow branches of function calls which together deliver the behaviour requested. The deeper a function call is nested, the smaller the problem to be solved.
And what about objects? Well, locate those functions on classes as you see fit. Use an OO approach you like. This won’t change the basic structure of any software solution which is a deep tree of function calls. Also Functional Programming does not change that.
5. What to refactor to?
Finally refactoring! You’ve found a solution, all tests are still green. Great! Now is the time for cleaning up your solution. Leave your duct tape programmer mode which was ok during the green phase. Enter the zen mode of a Japanese monk raking a rock garden.
This could be a time of pure delight. You bask in the light of a shiny functional and correct solution. Relax. Now live out the craftsman in you. Clean up the code so posterity will look up to you as a responsible programmer. Or, well, maybe just your fellow programmer will utter a couple of less „WTF!“ next time he/she has to work with the code you just wrote.
But, alas!, refactoring is often skipped. It seems dispensable. And the next increment is always more important than a good structure because it’s clear who will be happy with more functionality compared to better structures: the paying customer.
Sooner or later, though, your productivity will drop because of accumulated dirt in your codebase. Hence you should really take the opportunity to do at least basic cleanup after each test you got to green. And then some thorough cleanup once you got the acceptance test to green as well. That’s the test sitting at the root of your function tree and which was defined by the user/PO.
Really take the prescribed refactoring as a time to relax. Reflect on what you’ve accomplished. You’ve done well. Now make your code sculpture pretty.
I think many more developers would really like to do that - but they don’t feel confident. What’s clean code anyway? To what other structure than they have created during the green phase should they refactor the code? There sure are a million ways to improve the code - but which of them to go?
What does SLA mean? How to detect an abstraction level? Where are the boundaries of responsibilities? Because they are important if the SRP should be applied. How to slice and dice the code into classes/objects? Which rules to follow? Doesn’t help DIP with testing? Maybe a couple of more interfaces are in order then?
So many principles, so little time. Even if one developer could keep them all in his/her head there wouldn’t be enough time to apply them all, right?
I see great uncertainty and many misunderstandings when it comes to code clean in developers on all stacks. That’s one of the reasons why technological frameworks are so popular: they suggest that all’s gonna be well if you just use them properly. How often do I hear developers proudly exclaim „We’ve a Spring architecture!“…
Unfortunately the contrary is true, I’d say. You first have to be very clear about what clean code means, only then can you find the proper place within a clean structure to place usage of a framework.
So the question remains: what to refactor code to? How to make refactoring easier?
There are a lot of great principles. But under pressure we tend to develop tunnel vision. And pressure it is we feel during refactoring. We’re not relaxed, but constantly feel the customer/PO with his/her need for more functionality breathing down our necks.
No chance a lot of great principles can be applied during refactoring. But maybe one? Yes, focus on just one principle. That’s not too much, isn’t it?
Here’s my choice for this one principle which at least should always be observed: the Integration Operation Seggregation Principle (IOSP).
It’s very, very easy to check if code follows this principle. You don’t even need to understand the solution. IOSP is just concerned with form.
In IOSP code there are just two types of functions:
- Functions which contain logic, i.e. actually do something. They are called operations. They create behaviour.
- Functions which do not contain any logic but only call other functions. They are called integrations. Their purpose is to integrate parts into a whole, to compose a comprehensive solution from partial solutions.
Code structured according to the IOSP looks very different from what you’re used to, I guess. It’s lacking functional dependencies! There is no logic calling another of your functions to delegate some work and after that consume the result in some more logic.
This is how your code is looking today. Most methods contain logic (red) as well as calls (green) to other functions. They are hybrids, neither just integration, nor just operation.
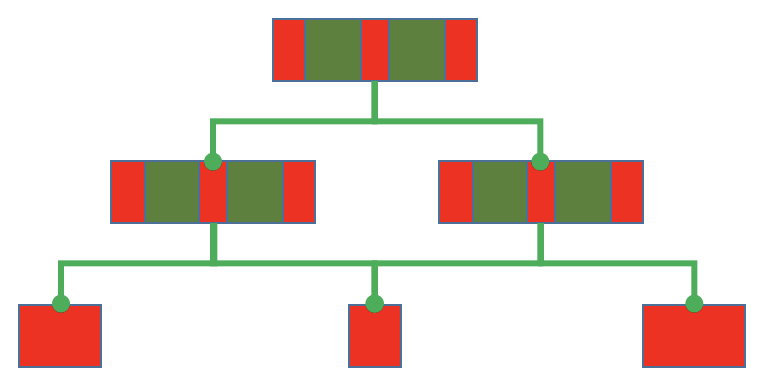
As usual as that is it’s not healthy in the long run. Several detrimental effects result from it, e.g.
- Functions grow indefinitely
- Logic in functions is hard to test
- Flow of behaviour creation is difficult to follow
- Changing levels of abstraction make understanding hard
Compare this to an IOSP function hierarchy:
As you can see: more functions. But all functions are now focused on one formal responsibility (remember the SRP?): they are either operations or integrations.
That has several beneficial effects:
- Functions tend not to grow beyond 10 to 50 lines.
- Logic is easy to test because it does not depend on other functions.
- The „flow of operation“ is easy to follow in each integration.
- Code naturally conforms to a stratified design which makes understanding and reuse easier.
Refactoring to the IOSP is not without its challenges, but the price to pay is small compared to the large benefits to gain.
First and foremost, though, the IOSP is easy to remember. Just a single acronym to keep in your head for refactoring after green. That should be doable, I guess.
But even better: if you get into a habit of thinking along the lines of the IOSP you’ll need less refactoring in the first place. You’ll produce cleaner code from the start. The IOSP is a natural match for problem solving by stepwise decomposition. So if you do your homework of solving the problem first before you start coding, then you very likely already have a list of integrations and operations to work through. This might go so far as to make implementation actually a boring task. What’s really exciting, though, is… design, i.e modelling a solution.
Summary
Yes, the understanding (or mainstream adoption) of TDD went wrong. But there is a way out of this pit of test frustration. Ian Cooper has presented a five step guideline to follow. And I’ve tried to fill in a couple of things I found missing. I hope in combination you’ll find more happiness in doing TDD.