Hamburg Style TDD - Diamond Kata
In a previous article I tried to explain why I’m not satisfied with the existing schools of TDD: They are not really tapping the developers’ capability to think. At least for my taste. Or to say it more bluntly: They are dumbing down developers.
Sure, their motivation behind that is honorable. And they all assure us of still, no, hence getting to the best possible code result. Nevertheless I think this is doing productivity a disservice.
Mileage always varies with different approaches, but for me the mileage so far has been too low with the established TDD styles. That’s why I came up with yet another one. I call it eclectic because it’s drawing from all sorts of approaches. And I might even not call it a programming style but a problem solving style.
In my previous article I explained why I think TBC (Thinking Before Coding) and ADC (Analyse, Design, Code) are so important. But what does that mean when applied to concrete problems?
Here’s a first problem I tackled to demonstrate this. I chose the Diamond kata because the originator of the Munich style TDD, David Völkel, was mentioned in a recent tweet teaching his style using this kata.
Let’s start…
Problem description
First a problem description as I found it on the web:
Given a letter, print a diamond starting with ‘A’ with the supplied letter at the widest point.
For example: print-diamond ‘C’ prints
..A
.B.B
C...C
.B.B
..A
(The dots '.' are just placeholders for spaces ' ' to make the result more clear.)
1. Analysis
The first thing I do when faced with a programming problem is… I’m trying to understand it. Sure that’s also advocated by other TDD styles. But exactly does that mean? What’s the result of analysis?
Analysis is the activity which in my view is supposed to produce understanding. But how to document my understanding?
In the end there is no unambiguous understanding except when I’m able to solve the problem (or very similar problems in the same problem class). That means any software I produce needs to be able to do the same. Otherwise I might have understood, but wasn’t able to encode my understanding.
Translated into code that means analysis results in two things:
- examples of successful problem solving (aka test cases)
- functions that actually show the behavior as described in the examples.
I usually document my understanding in a file next to the code. In this case I used a .md file:

You see, first there is some text explaining what I gleaned from the problem description. An important aspect of that are terms of the domain language.
But then there is a function and test cases. They are the real expressions of my understanding.
The sample problem is so easy, however, I did not come up with my own test case. But if it’s more complicated I will go beyond whatever has been presented by the client.
My analysis is complete once I really get my insights encoded as acceptance tests and the signatures of behavior delivering functions:

I don’t need to know how to create the results. Just the surface of my „system under development“ needs to be clearly specified.
That’s easy in this case of course. But what if I had a hard time to come up with an interface? Isn’t TDD supposed to help with that?
Well, my view is: As long as you don’t know which functions should provide the requested services, you should not touch your production code. You’re not even in a situation to write tests.
Lack of clarity of the interface is a clear sign of „chaos“ (in your head or the client’s head). And when in chaos the first thing to do is: act!
In the case of programming that means whipping up a REPL or some other scratchpad and start „drawing“, start experimenting. Play around with interfaces all you want. Write a whole prototype, even.
But don’t touch your production code! Not even backed by a test. Otherwise you’ll later on be sorry because you have to go through much refactoring. And that’s always putting strain on your codebase.
The remedy to cluelessness is not refactoring! As long as you don’t have a clue how a system under development’s surface should look like, you’re clueless. You can’t even come up with clear cut test cases.
It’s time for a different mode. Not the test-first mode, but an experimentation mode outside production code.
Luckily that’s not the case for the Diamond kata, though. That means my analysis is complete.
Bottom line: For me TDD always means ATDD (Acceptance Test-Driven Development). Don’t start work on production code before there is an acceptance test, i.e. a comprehensive test describing the required behavior.
An acceptance test to me is a guiding light or a north start. Once the acceptance tests are going green I know my job is done. I don’t mind them staying red for a longer while. I simply don’t execute them all the time ;-)
2. Design
With the acceptance tests implemented I continue by TBC. I ask myself:
- Can I partition the overall problem into smaller, complementary problems which I then solve independently?
- Are there simpler problems nested inside the overall difficult one? Can I find a list of incremental tests?
The second step is what TDD originally was about, I think. In my view, though, this only works well for very simple problems. It’s a not to be neglected question, but in my approach is not the first one to ask.
My first step is to look for more or less obvious sub-problems which I can solve more or less independently - hoping that the solutions to the sub-problems later can be integrated into a solution for the overall problem. Each sub-problem again will be represented by a function responsible for some partial behavior.
I’m using the good old „stepwise refinement“ approach, you could say. I’m recursively descending a problem tree.
And why not? Just because it’s an old approach doesn’t mean it’s not fit for the modern world.
But I’m using it with a twist! And that’s quite important for the clean code goal. My function hierarchies are free of functional dependencies. I’m not distributing logic vertically all over the hierarchy, but lump it together in the leaf functions, called operations according to the IOSP (Integration Operation Segregation Principle). That’s making a huge difference for understandability and testability!
Here’s what I came up with as a design for the Diamond kata:
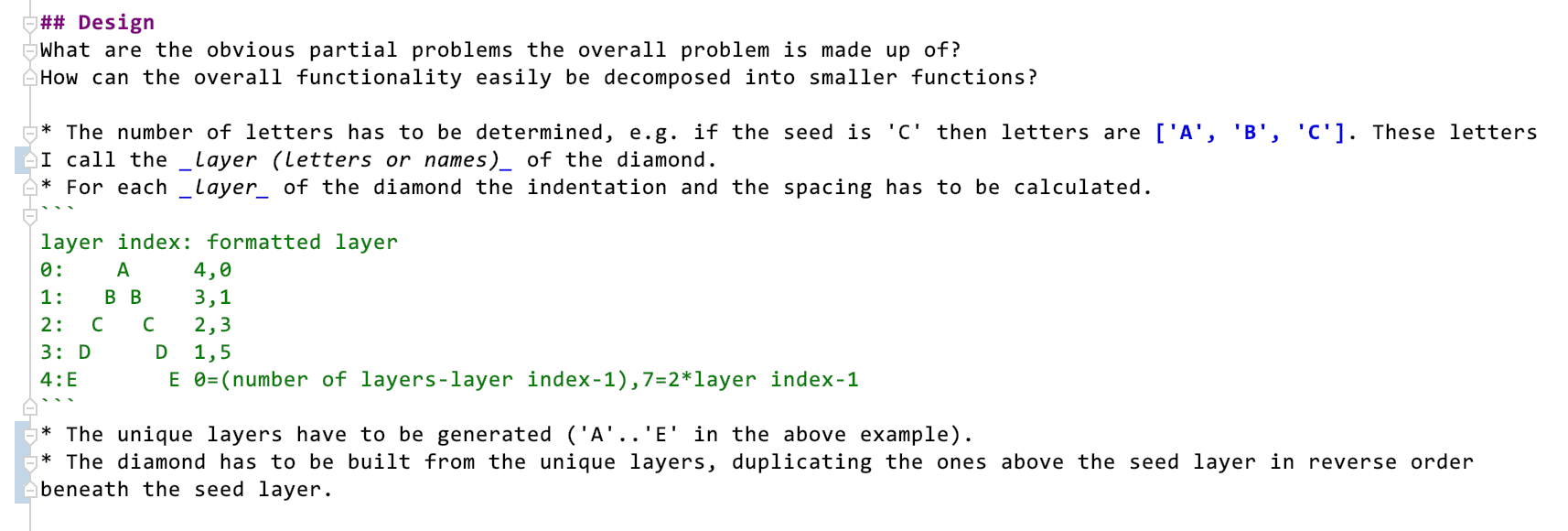
It’s more precisely documenting my understanding of the problem and delivering a model for the implementation.
The model consists of yet more functions, but in addition to that also relations between those functions.
- There is a hierarchical relation: The original user facing function, the root function of the function tree depends on the other functions.
- There are before-after or sequence relations: The partial functions will need to be called in a certain order.
- There is an implicit aggregation relation: All functions will belong to the same module (class).
Noteworthy of this kind of design is the absence of loops! To declarative and on a high level of abstraction a model needs to be free of imperative loops. Looping will occur in the end, but in the model it’s hidden.
This design process maybe takes me 10 minutes. The most effort goes into actually writing the results down for the purpose of this article.
Why should I not invest this short time up-front for design? It’s easy, and it delivers starting points for further tests. I don’t need to drive the implementation through the root function. That, to me, would feel artificial, and not simpler. And I would have to refactor more.
My design will produce clean code, I’m confident. Because the implementation will follow the IOSP.
Growing logic by applying tests primarily to the root function (and later refactor) is like growing a Bartlett inside a bottle. I call that pear programming.


Source: Wikipedia
It can be done. It’s a piece of art, maybe. But I find that hard. The harder the more logic this way should be developed. Because that way it’s impossible to target pieces of logic with tests. All logic is always under test - unless you swap it out with substitutes.
Substitutes, though, to me are additional complexity I want to avoid! I’m not saying they should not be used. But to base a programming approach on them is not my cup of tea.
A KISS for design
One argument against my approach, I hear, is that I’m not doing the simplest thing possible. Starting with a trivial test (even a degenerate test case) and then answering that with maybe only a singe line of production code would be much, much simpler. And it would immediately deliver a (small) value. And it would guarantee that no production code gets written without being covered by a test.
By now you can imagine: I beg to differ.
In fact I think my kind of design is the simplest thing you can do. I’m following the KISS principle to the letter.
Why? Because I don’t even implement a single line of code (at first). What’s simpler than writing code? Not writing code! That’s faster, that does not produce waste which later needs to be refactored.
Designing by stepwise refinement, by dissecting large problems into smaller ones is so simple because it „assumes“ that certain „services“ will be available. It does not care how they are going to be implemented. That’s details to wreck your brain about some other time.
The above list of functions is a wish list. I’m wishing for help: „How nice it would be to have a function that does X…“ or „What a relieve it would be to not worry about problem Y anymore because a function is taking care of that…“
If I cannot simplify a big problem by at least coming up with two partial problems which are smaller I guess I don’t really have a clue about what’s going on in the first place. Either I can solve a problem by writing the logic – or I can solve it by dissecting it into smaller, complementary problems.
With regard to the Diamond kata wishing for help could run like this:
- „Oh, there is a single input letter, but the diamond consists of multiple letters up until the input letter. I wish there was a function taking care of getting me this list. The rest then can be accomplished by another function.
- „Hm… given a list of letters I need to generate the layers of the diamond. Half of them are unique. It would be nice to have a function doing that. Another one could then take care of building a full diamond from them.“
- „Now that I have a list of letters the hard part is to generate a single layer with the right spacing. I wish there was a function for that. Generating layers for all letters then is simple based on that.“
- „The most difficult thing about a layer is to get the number of leading spaces and separating spaces right. There should be a function calculating that for each layer. Arranging the letter in a layer based on that info then would be easy.“
I find this most simple. And if it’s not then I need to double down on thinking the problem through or maybe go back to analysis. Not being able to come up with a „functional design“ to me is the first sign of cluelessness. I would not recommend to touch production code in such a state of mind.
3. Implementation
After design all’s prepared. At least that’s true in this simple case. I know all the functions that will be needed. I’ve a good feeling about this. If the problem was larger I would not have refined the whole function tree down to the last operation. Remember: I’m all for iterative and incremental progress. TBC with ADC is not about a resurrection of the waterfall.
Backed by the acceptance tests I now implement the functions I „uncovered“ during design in any order. I could start with the seemingly simplest or simply with the first one. It pretty much does not matter.
Determine the layers
The partial problem of determining the number of layers with their respective letters (layer names) I attack using… incremental tests. Inside my approach I’m using pretty much Chicago style TDD. You see why I’m calling it eclectic?
I come up with two tests growing in difficulty and implement the production code by going red-green-red-green.

There is nothing to refactor after the first test and not even after the second test. The function is so focused, so small.
You might find that the code to get the second red test to green does not seem simple. If so I say: To hell with simplicity! At that point I had a clear idea of how to solve the problem once and for all. Why not just write it down?
I could have used another test to drive out some pattern and refactor… but with this kind of small problem that seemed too much effort.
Or if you find the implementation lacking with regard to null boundary checks let me say: To hell with defensive programming! It’s not the responsibility of this function to check if the seed is in a certain range. If so, it just fails. There is not even a requirement to behave in a certain way in such a case. Why should I implement a solution to a non-existing requirement?
Defensive programming, I have to say, often is a form of procrastination. It’s applied to postpone solving the hard problems. It’s applied to ward off „friendly fire“ from code other team members might write. It thus is a substitute for the right thing to do: Doing real thinking about the real problem and drawing explicit trust boundaries during joint design sessions with other team members.
Calculate layer whitespaces
My approach again changes with the second function I implement: I go for a „one shot kill“: first a red test on an acceptance test level (for a partial problem), then all the necessary production code.

I’m not trying to crawl my way to a full solution with incremental tests because the solution is sitting right in front of me in the design. I’ve done „my math“ in the design document already; it was part of understanding the problem. Why shouldn’t I use that now?
And again: the operation is so small. The loop is following a pattern, the calculations are trivial. If the one test would fail it would be easy to detect the cause.
Of course the production code is benefiting from language features like yield return. No need to allocate a data structure to compile the results in. Also no need to define a data structure to carry both values for each layer. C# tuples as „ad hoc records“ are perfect for that.
Please note how only the number of layers is passed to the function. No need to let it know about the layer letters. That’s decoupling in the small. It’s made easier by designing the functions before implementation. Refactoring to this kind of decoupling later on would be harder.
Generate the unique diamond layers
The third partial problem again is different from the previous ones. I now realize it’s too difficult to solve right away or with incremental tests. So I revert to stepwise refinement once again.
The overall problem of generating the unique layers consists of the partial problem generating of generating just a single layer - and a remaining problem of doing that for all layer letters.
It’s a typical „N:1 problem“. Or you could call it a mapping problem: the same thing is done for each item in a collection. However here it’s two collections of the same length. The layer letters have to be „merged“ with the layer whitespace calculations.
What I do in this case I use a bottom up approach: first I implement the nested function for generating a single layer. I do that again with two incremental tests, red-green-red-green.

The first version of the production code might seem not really according to KISS. Why include the if? For the first test this condition was not necessary.
Well… I guess my attention slipped a bit. I indulged in some look ahead. I knew a second test was coming which would need the conditional statement.
(While I was writing it I actually stopped for a second and mused about it… but I did not draw the right conclusion: not necessary right now, throw away.)
Please note the strange letter passed into the function: Why a * which is not a valid layer letter? This is my way of making obvious that this function does not care about „correct“ diamond characters. It’s focused on the layout of whatever it gets.
After I got the generation of a single layer working I move a one level up the function hierarchy. Doing one layer is integrated by a function for generating all unique layers:

This one again is so easy, I just use a single test to drive its production code. I dare to do that because C# is offering powerful abstractions like Linq; there are no more loops to get right.
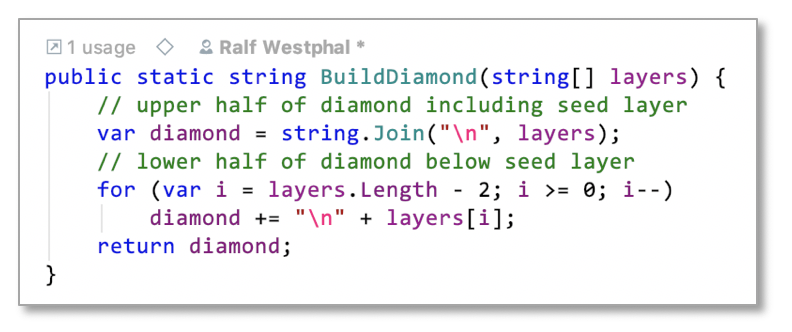
Build diamond
Finally I get to the function building the diamond from the layers. This again is so simple I just need one test:

As you can see the function consists of two parts. The levels of abstraction of its logic are not even: line 50 is slightly more abstract than line 51f. I need a bit more mental effort to understand what 51+52 are doing than what 50 does.
But in the end it’s such a small function I don’t think more structure is needed. Or maybe this is a case where comments would help?
Crossing the finish line
That’s it. All functions from the design have been implemented. They are doing their partial jobs. That means all „musicians“ are ready, the instruments are tuned. It’s time for them to come together as a band and play a concert.
I do this by calling the partial functions from the root function:

Calling functions is the root function’s only responsibility. I call that integration (or composition) as opposed to operation. Operation is what the other functions are doing. They contain logic, they are the real workhorses of the solution.
(With the exception of GenerateUniqueLayers which I also view as an integration due to its shortness and usage of Linq, even though it’s not just calling another function but wrapping that.)
Coding the integration is easy by definition. It’s so easy in fact, that intermediate integrations in an IOSP-based function hierarchy hardly need testing at all. It’s the same as if you extracted a method during refactoring: you don’t put that under test immediately.
With the root function, the function which the user/customer is interested in, filled out I check the acceptance test cases from the beginning… And lo and behold they are both green!
I’m done with solving the original problem.
Refactoring
So far no refactoring seemed necessary. Due to TBC the code already is very clean, I’d say: all functions are small, the integration gives a good overview of how the problem is solved, the SRP reigns.
Now that I’m finished, though, I step back and try to imagine how a future reader of the code (possibly myself) would experience it.
The first thing I notice is that Print still is kind of fraught with details. I decide to extract another function:
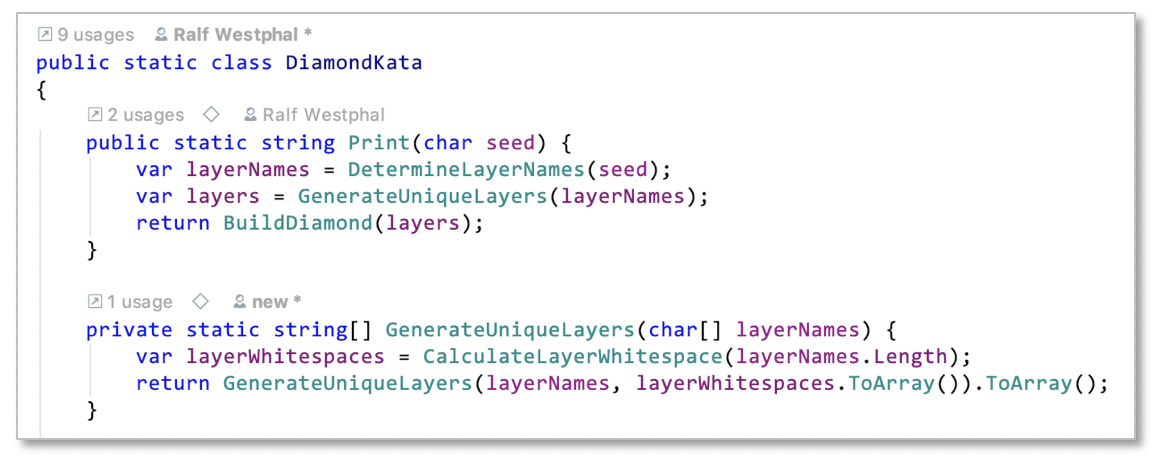
Now Print tells the story what a diamond production looks like in three easy „sentences“: First calculate the size of the diamond by determining the layers it should consist of. Then actually generate those layers, but only the unique ones. Finally build the diamond from the layers.
While reading this story no details of the processing steps are necessary to know. At first that’s what some developers cannot really accept; they tend to read the code depth-first. However, my approach favors breadth-first reasoning.
And GenerateUniqueLayers is yet another integration which is focused on layer generation. It’s hiding the details of that so Print can be shorter and more conforming to the SLA principle.
Although IOSP-based code is easy to understand due to many small methods and clearly visible processes, code sometimes cannot tell the full story. Why are things how they are, what do certain terms mean?
Even with this small example I felt that was the case. So I also added an introductory comment:
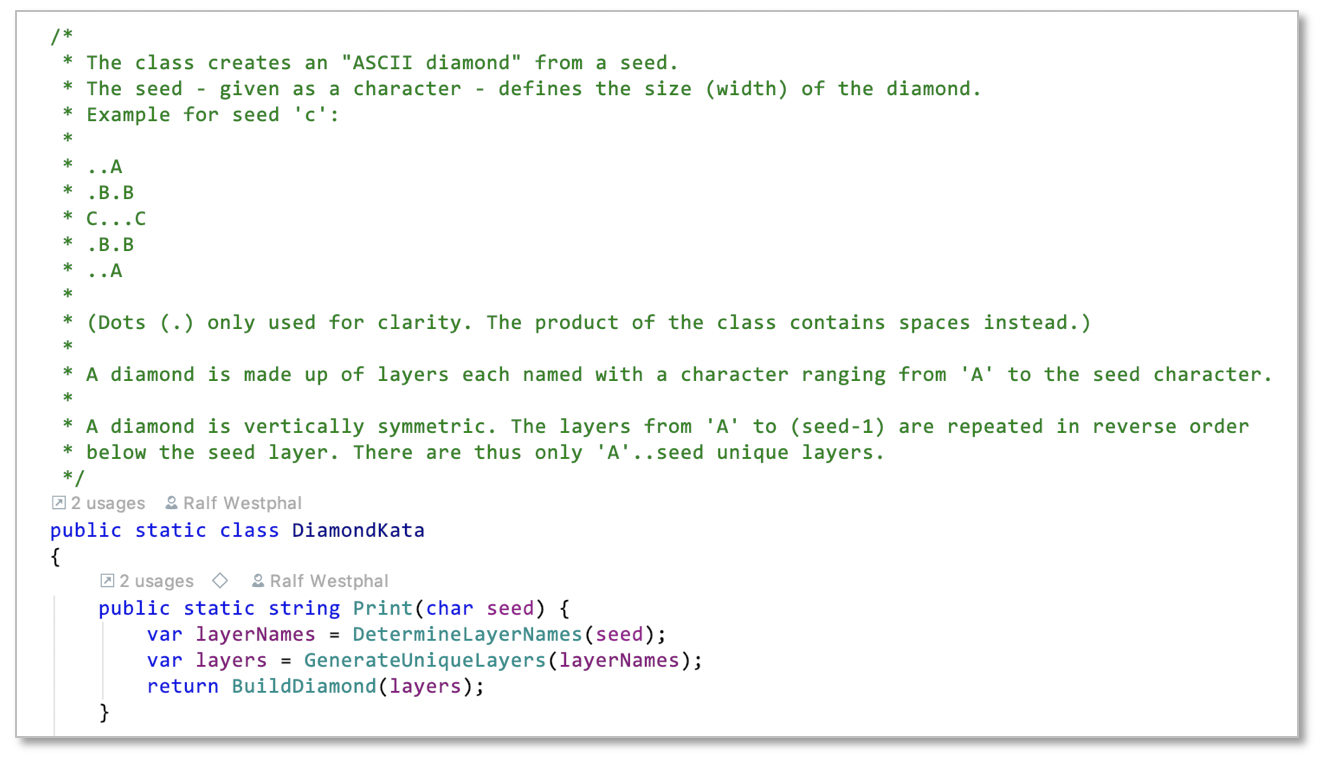
To me comments are not a code small per se. It’s what the comments are used for that is important. Background information, documentation of decisions, some kind of glossary… all that and more can be valuable in code.
Deleting tests
Finally, now that I’m satisfied with my solution, a fundamental act of refactoring. It’s almost unheard of, I’d say, but I’m doing it on a regular basis as part of my approach: I delete tests.
Yes, that’s true. I delete tests which would make future refactorings harder.
To see which tests are of no longterm use I simply set the accessibility of all methods to private which haven’t explicitly been ordered by the customer. Methods not used in acceptance tests are obviously not used and should be hidden as structural details.
All methods of the single class of my solution except for Print thus go private. And all tests exercising these methods go red and are deleted. That’s seven test functions.
The only remaining, stable, long term tests are the acceptance tests. Or more generally tests of methods which need to remain public on other classes I might have designed (or which were created during refactoring). Tests of methods on such classes which also haven’t been requested by the customer and might vanish at any time I call module tests.
And the tests which just got deleted to me are scaffolding tests. Like a scaffold on a building they were useful while building up the logic. But once the logic is complete they are torn down like a scaffold on a building. Otherwise they would impede future changes of the overall structure.
But isn’t it a waste of time to write those tests in the first place if they get thrown away? I don’t think so. They were of great help to develop logic function by function. They were like finely honed probes measuring some quality of my code at precise points. Also they can guide later decisions with regard to modularity: If I very much hesitate to delete a scaffolding test that might be a signal to extract a module on which the function under test is public.
I would not have been able to drive my logic test-first at such detail and in such isolation only with tests going through the root function. „Pear programming“ to me is too inflexible, too cumbersome. I like fine grained control over my logic and tests. I like to build my ship outside the bottle before I shove it in and erect the masts.
Source: wikiHow: How to Build a Ship in a Bottle
What I hear from developers trying one of the other TDD styles often is they feel trapped by all their tests. Refactoring becomes impossible without turning many tests red which then requires them to correct them.
I’m suffering much less from such effects. Because I keep less tests around.
The most important and long living tests are the acceptance tests. They exercise the logic in a solid way.
Module tests complement acceptance tests; they knit the safety net more finely. But if they turn red due to refactoring I’m very willing to throw them away instead of repairing them.
Summary
Hamburg style TDD is about thinking before coding, the absence of functional dependencies (substitutes are comparatively rarely used), and also about the „art of letting go“. Don’t attach yourself too much to your tests.
It’s an outside-in approach to problem solving and programming.
PS: You might be wondering if all this leads to overengineering. So many functions… isn’t that much overhead?
Well… this is the alternative: The same logic sitting in just a single function.
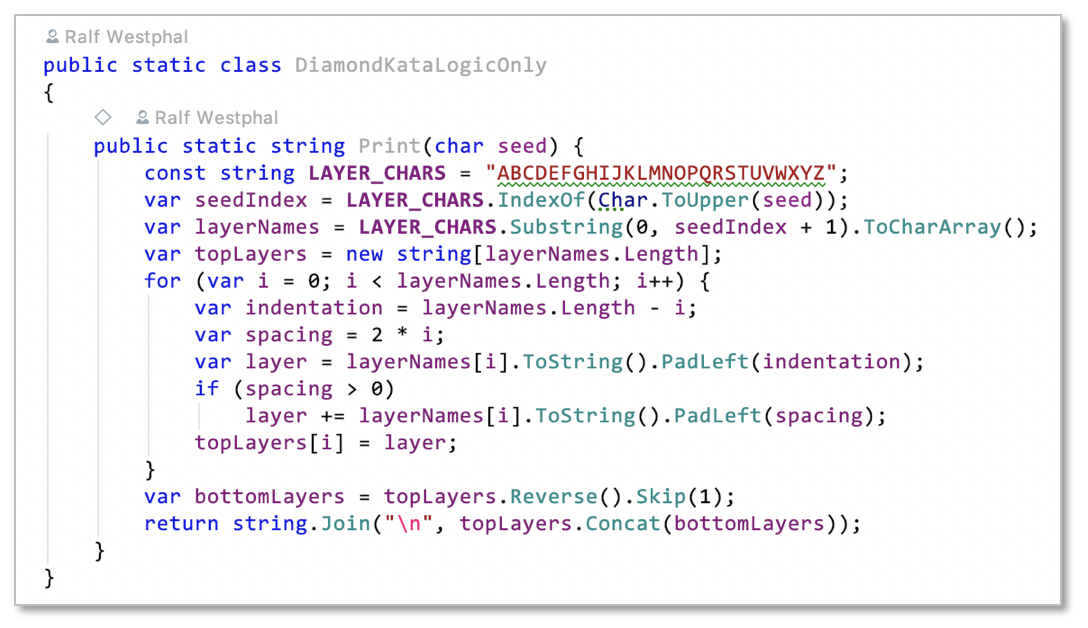
Is that, what you like to see when asked to fix a bug? Multiply the number of lines by 2, 5, 10, 50 because that’s how long functions in „real code bases“ usually are; even methods with 5000 lines of code and more are not unheard of.
Functions not following the IOSP tend to grow indefinitely. There are no boundaries to growth. And the general recommendation „keep your functions small“ is pretty fuzzy. What does „small“ exactly mean? And where to stop, what else to do?
The IOSP is a great guideline towards codebases with all small functions.
But the above function still is small. Why have more than one function? Reason no. 1: Because this is an exercise. Reason no. 2: Even small functions can contain logic that is hard to get right. Wouldn’t you want to be able to check that easily?
But the above function is not what a classic TDD approach – aka „pear programming“ – would have led to. Fewer functions would have been extracted from the growing logic in the single function under test.
That’s true. But firstly refactoring is hard and easy to avoid. Secondly the result probably would have been a root function not conforming to the SLA: there would be a mixture of logic and function calls in it. That would not be easy to understand.
Finally I find code refactored from functions with functional dependencies and driven by TDD often not easy to read because it’s hard to extract responsibilities cleanly once they were entwined. Sure, not to refactor is no solution. But not having to refactor due to a clean design before coding leads to better results in my experience.
PPS: It’s never over! Today’s clean code is tomorrows dirty code.
Cleanliness of code is subjective and relative to your understanding/knowledge. If you gain new insights clean code you wrote yesterday will turn into somewhat dirty code.
A case in point the BuildDiamond function. I expressed some concern regarding it and even suggested comments to improve it. But just know I had another idea:

This to me is cleaner. It’s the same functionality, hence I call it a refactoring. But instead of extracting structures I redesign the approach to solving this partial problem and implemented it using more of the power of Linq. Now the function shows better SLA; no comments are needed.
I changed the logic even without the scaffolding tests being present anymore. I was confident the acceptance tests would catch any regression.