Functional Dependencies Considered Harmful
You’ve probably heard of the seminal paper „Go To Statement Considered Harmful“ by Edsger Dijkstra from 1968. It paved the way for broad adoption of then modern programming languages with their control flow statements like if-then, for, or while. With Pascal and C probably being the first broadly popular languages in this vein.
You don’t ever question the usefulness of this language construct for example:

But some 50 years ago such an attitude would not have been the norm yet. You were most likely to encounter something like this in code instead:

Both code snippets show code valid in C# in 2019, but only the first of course is deemed proper or clean (in all but the most rare circumstances).
So called Structured Programming today goes without saying. It’s the de facto standard of programming. In my Clean Code trainings I never ever meet anyone who’s struggling with letting go of the goto statement.
The secret of Structured Programming
The world of programming has become a better one with „goto-less programming“ or Structured Programming. But why? What’s the lesson we can learn from not using goto anymore?
To me it’s that voluntary restraint can be empowering. Doing less of something that’s possible is actually enabling to get done more.
Arbitrarily jumping around in code was possible. It was used extensively. It got the job done. Programmers were working very hard. And they were meaning no harm.
Tragically, though, this common practice of well meaning hard working programmers was causing harm nevertheless. It was causing other hard working programmers to break out in sweat and work even harder. Because reasoning about code was made very, very difficult by casually using goto on the spur of the moment. Programmers were trying to shoot problems down they were under attack from – but also caused a lot of collateral damage. Software development was suffering from a growing amount of friendly fire, so to speak. Shots went into problems, sure. But they also went into programmers’ feet. A lot.
The common attitude back then was: Programmers are entitled to fight off problems by using goto. It was like an IGA, an International Goto Association😉 of language vendors offering goto and other weapons to programmers.
But then it dawned on some that maybe this goto weapon was causing more harm than good. And slowly, slowly things started to change.
The key was to understand, that not all that was possible should also be „allowed“. goto was a dangerous weapon. It was able to „kill“ problems, but it also was able to „kill“ understanding. Unbridled use was not sustainable.
First then there were admonishments to be careful when using it. Then came patterns of how to use it best. And finally… came languages with abstractions that made its explicit use unnecessary (or even impossible). Under the hood program control was still jumping around at runtime, but in high level languages this was carefully hidden by control statements.
goto still was possible technically, but through a mixture of abstractions and a growing consciousness regarding its dangers it vanished from everyday use.
In my view this was a step in the direction of „ecological programming“, i.e. programming not just thinking of today, but keeping in mind its effects on tomorrow. Some form of over-exploitation of code was stopped. Software development became a bit more sustainable - and thereby also scalable.
Voluntarily abandoning the capability of goto, voluntarily restraining oneself opened the possibility of actually writing larger programs and still being able to reason about them. With unbridled use of goto we would not be able to write the programs we write today.
More letting go
The other day I saw a presentation by Wolfang Kinkeldei in which he listed more self-imposed restraints in programming. If I remember his list correctly it went like this:
- Structured Programming (SP): getting rid of
goto - Object-Oriented Programming (OOP): getting rid of function pointers
- Functional Programming (FP): getting rid of assignments
- Reactive Programming (Rx): getting rid of
return - Actor Programming (AP): getting rid of threads
In the tradition of „Go To Statement Considered Harmful“ this to me means: software development has (also) evolved by restraining itself. Not all that can be done, that is technical possible, should be done. Even if that means letting go of fine grained control - because that’s something many developers struggle with. They like to be in control, to tweak whatever can be tweaked in case of some missing efficiency (mostly runtime performance and memory usage).
But even if in some very rare cases it might be necessary to take (back) control over minute details of program execution, it’s mostly a „control mania“, I’d say. Especially for the past 10-15 years large areas of software development haven’t been lacking hardware resources anymore. Memory, hard disks, processor power, number of processors are not the constraint anymore impeding the creation of valuable software. The constraint has shifted: developers are the constraint now, I believe. But that’s a topic for another article.
Let me explain what I see is behind those programming approaches:
Structured Programming
Letting go of goto while introducing control statements as abstractions of goto patterns led to easier to understand code. Evolvability increased, higher longterm programmer productivity was reached, programs could grow larger. Great!
Functional Programming I
I would define the self-restraint different from „getting rid of assignments“. „Getting rid of mutability“ is more fitting, I’d say. Changing data through assignments is for data what jumping around the code with goto is for behavior: it makes code hard to understand. More attention, more mental state, a more complex mental model is needed to be able to change code for the better. Without mutable state (or more generally: side effects) evolvability increases; code becomes easier to reason about, especially in times of a growing need for concurrent programming.
Functional Programming II
Even though it wasn’t on Wolfgang’s list I’d like to add another relinquishment of FP. FP is also about „getting rid of loops“, I think. You’ll find much less loops like for or while in FP code than in OOP code. (If a looping construct is all offered by a FP language.) Instead you find streams of data processed in „pipelines“ of map-reduce-filter operations each working on a collection of data, but with the loop carefully hidden beneath a language/library abstraction. First there was the iterator pattern, then a more abstract loop like foreach hiding it, then higher order functions like map (F#) or Select (C#) doing the looping inside and calling a function for each item pulled from an iterator (see code example below). Also responsible for the absence of loops in FP code: recursion; but to me that’s somewhat less of a replacement because many developers struggle with wrapping their head around recursive solutions. But anyway: the benefit of abstaining from loop statements is… evolvability. Again. Because less/no loops means easier to read code. It even means less code. Which means less surface for bugs to attach to.
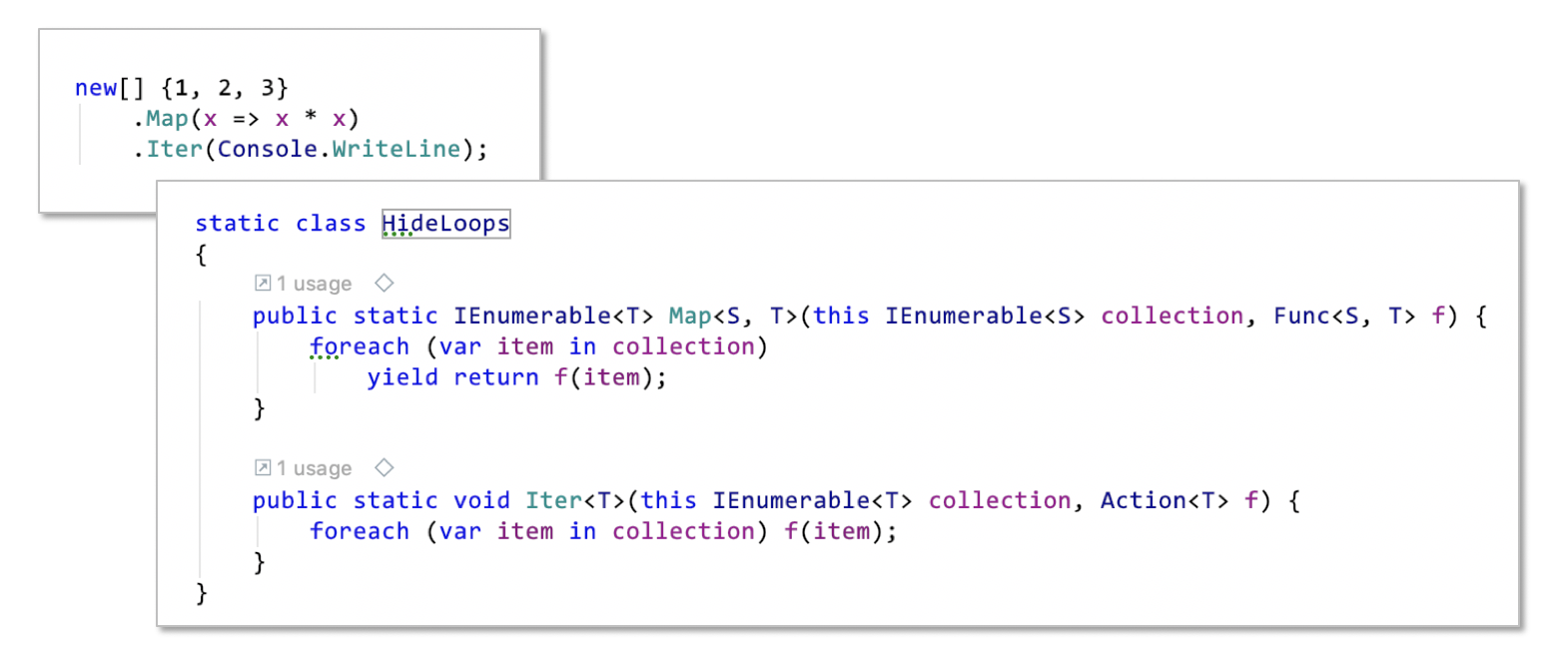
Reactive Programming
„Getting rid of return“ is a nice way to describe Rx, I think. Because that’s essentially what it is: don’t return the result of a function through return at the end, but rather „pass each result value on individually“ via a continuation (a function pointer). The effect of that: downstream processing of results does not need to wait for all parts of a result to become available. Maybe there is a huge number of result items which should not all be loaded into memory or items become available only sporadically. In both cases it can help to process them as a stream of single items instead of as a collection of many items. FP is hiding return in pipeline functions and with iterators, Rx is getting rid of it. And what’s the benefit of that? Primarily more efficiency, I’d argue. Data can get processed earlier (async) and more independently (in parallel). Also one could say that it’s more natural in certain cases, i.e. easier to reason about.
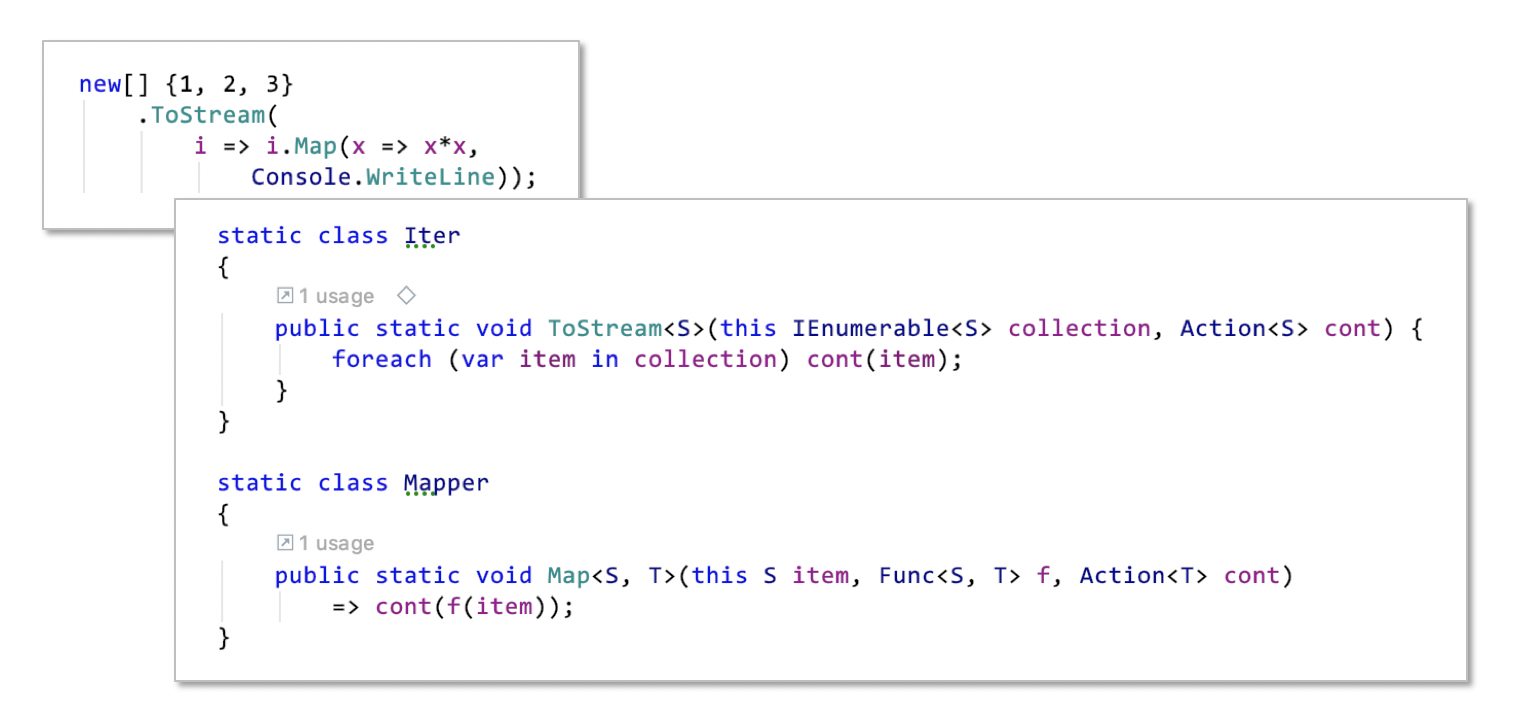
Actor Programming
With actors programming gets rid of threads. Threads are of no more concern to the programmer; they get allocated and assigned in the background. And with threads gone also synchronization is gone. No more semaphores or locks. Because actors are guaranteed their own resources and to run on a single thread. Data is passed to them via a queue (mailbox) and passed on to others via their queues. No waiting, no synchronous request/response. Less detailed control - but more peace of mind. Abandoning threads with all the ensuing complexity to manage shared resource access is clearly a means to make it easier to reason about code. Evolvability is increased and larger concurrent code bases can be written.
Object-Oriented Programming
I have to admit I don’t really understand what was meant by „getting rid of function pointers“. I can only imagine that it alluded to the lack of polymorphism of static function calls. In the next code example the calls to all functions are fixed, they are baked into the Client function. No way to change them at runtime to alternatively call some other function. That’s the opposite of flexibility.
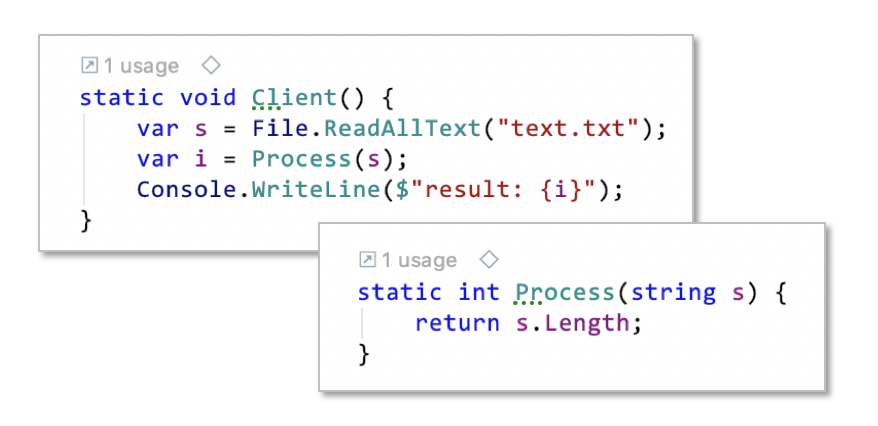
Compare that to an OOP variant:

Sure there now is more complexity – but what is gained is flexibility. By indirectly calling a service’s Process function through an object (_s) a variation point is created. The Clientdoes not care any longer which function provides the service to process the text read from the file. The Client is not dependent on a concrete service, but just on an abstraction (interface IService). That’s an application of the Dependency Inversion Principle (DIP).
This interface can be implemented by different concrete services as is done by Service and AnotherService. Where a Client is created it can be configured to use any service conforming to the interface. A service implementation is instantiated and injected into a Client object. That’s an application of Inversion of Control (IoC).
Great, isn’t it? OOP based on DIP + IoC increases the flexibility of code. That’s useful to make it adaptable for future requirements. That’s also useful for making it more testable.
Sounds like OOP was helping evolvability, doesn’t it? Because evolvability benefits from flexibility and testability (due to its potential to increase correctness).
Object-Oriented Programming is different
At first I thought, Wolfgang’s list was just great and to the point. But then I noticed it was mixing two categories of programming paradigms.
All had one thing in common: letting go of something that was possible, but somehow had a detrimental effect if used unbridled.
However the detrimental effect was concerning different aspects of software. With SP and FP and AP it clearly is the understandability of code. By using goto, mutability, and threads explicitly, by trying to control behavior on such a detailed level, code becomes hard to reason about.
To some extend that’s also true for using return. But the effect is much smaller. The situations where return stands in the way of easy to design/unterstand code, are comparatively rare, I’d say. FP is doing more good by hiding loops, than Rx is doing by avoiding return in favor of continuations. I’d even argue that Rx is adding complexity (i.e. decreasing understandability) in order to gain some other benefits. Compare the above FP code sample to the Rx code sample; you’ll find the latter „less easy on your eyes“.
But still, of course, Rx is useful. It just excels in another area as for example SP does. That’s my point.
With SP and FP and AP the point of letting go, of voluntary self-restraint very clearly is increasing understandability of code. Not so with Rx. Its focus, to me, is more in the realm of efficiency, i.e. some runtime characteristic (e.g. responsiveness).
And now OOP. With OOP the mismatch with SP etc. is even more pronounced.
OOP, at least mainstream OOP from the 1990s on, in my view was not supposed to increase understandability. Rather it was supposed to increase short term productivity. Bluntly put its message was: Quickly whip up abstractions and reuse them all over the place.
Sure, this also was supposed to help in the long run. But, alas, it did not really deliver on that. And my guess is, because it’s not really about letting go; there is no real self-restraint in OOP. That’s why it’s not fitting in the above list.
Look at the OOP code sample again. Does that look simpler than the previous one with the static functions? No! For the purpose of flexibility (through interface polymorphism) OOP is creating complexity.
SP, FP, AP are effectively hiding details for the benefit of understandability. However, OOP (and also Rx) are creating additional details.
OOP is not in the venerable tradition of SP, FP, AP! It’s not really getting rid of a complexity problem. It’s creating one.
That does not mean OOP is bad. I like the features of OOP languages like C#. I would not want to do without them. They are useful. But where they are useful for higher understandability of code that does come from „getting rid of function pointers“.
But what are OOP’s achievements? Where does its features abstract from details to increase understandability? How does it really let go?
Getting rid of visibility
The first feature of OOP it brought to the masses was modularization. Modularization was deemed important since the early 1970s. See another seminal paper as a testimony to that: „On the Criteria To Be Used in Decomposing Systems into Modules“ by D.L. Parnas.
Nevertheless features for effective modularization were lacking for a long time: C accomplished this half-heartedly in my view through .h files. Pascal was missing modules altogether. Modula was never broadly accepted, even less Oberon. And Ada was too heavy weight. Dialects of Pascal like USCD featured modules, lacked acceptance. Only when C++ made it into the mainstream, and then Delphi, and then Java became modules a feature at the fingertips of many programmers.
But what do I mean by „module“? You sure have an intuition about that which will overlap with my idea. Nevertheless let me state mine here to avoid misunderstandings:
A module to me is an aggregation of functions and possibly data. In that it’s resembling a namespace. But in addition to a namespace a module offers to selectively make its elements visible to the outside. The distinctive feature of a module is its interface, i.e. the collection of public/accessible elements which is a subset of all its elements.
The interface of the following Stack module consists of just two methods: Push and Pop. But Stack aggregates more than that: some data plus another function. These details, though, it hides as private.

Modules are aggregations of functions and data with a reduced surface. That’s so great about them. The possibility to distinguish between public and private elements enables encapsulation. Like with functions: how a function accomplishes its task is hidden behind its signature. Modules take that to the next level for several functions plus shared data.
It’s possible (and the default) to make all functions and all data visible to all parts of the code – but you should not do it. Restrain yourself! Modules do for structure what SP does for behavior: short term freedom is limited for long term understandability.
However, modules differ from control statements. With SP it’s (almost) not possible to do the wrong thing anymore (meaning to use goto). Control statements take the programmer by her hand. Modules, though, are just making an offer. You still have to make hard decisions yourself: What to include in this module vs that module, what to make visible vs what to hide.
That, I guess, is the reason, why modularization in general or OOP in particular until today did not have the same overall beneficial effect as SP. Still too much freedom or uncertainty. Too much you can do wrong.
Modules are helping to increase the understandability and thus evolvability of code. They allow codebases to grow larger, because an increasing number of details can be hidden behind interfaces. That’s great!
But I see more need for letting go.
Getting rid of availability
Modules were available before OOP, but not that widely used, I’d say. With OOP this changed. But the reason was not the increase in understandability to be gained. Rather OOP promised to make software able to more resemble the real world.
The „obvious“ structure of the real world seems to be made up of, well, objects. With objects being „things“ with some state reacting to forces and stimuli of all sorts.
OOP promised software to also consist of a mesh of „things“ with behavior based on hidden state.
The foundation for that of course were modules. They provided the ability to hide details like state - but the state existed only once. What about state for all the different „things“ in the world, i.e. multiple similar state? How to create a multitude of „things“ in the first place?
OOP needed to let go of universal availability (of single data items) to solve that problem.
Here’s what the problems was before OOP even when using modules:

Global data was the default before OOP. All data was available to all functions (to which it was visible). The Queue<T> module is different than the above Stack<T> module: The stack is working on just one, although hidden data structure; there can only be one stack (of a given type) at runtime. But if there are supposed to be many queues, the basic data structure needs to be handed to the Queue<T> module functions. That means the basic data structure is available to everybody because it’s managed outside the Queue<T> module. It’s not hidden and thus is not protected from arbitrary manipulation by other than queue logic.
Enter OOP. OOP’s instantiable modules (classes) made it possible to limit the availability of data. By binding data to functions inside of an object access could be even more limited than with modularization.

Data did not „float around“ anymore, it dit not need to be widely available despite restricted use, but could be tied to the place of its usage.
I think this is a quite helpful feature. It is limiting the ways you can use data in a wrong way. It is limiting the scope of its relevancy even further. That helps understanding code better.
But my feeling is that class modules (as templates from which objects are generated) are less of a boon for evolvability than modularization. As shown above in conjunction with interface types they allow polymorphy, but that comes at a price.
Also like with modularization classes are optional. A programmer has to decide when and how to use them. And for the past 25 years a lot of things have gone wrong with classes. Not so with the control statements of SP.
Whenever a control statement is used instead of goto statements, code will be easier to understand. That cannot be said of all classes defined in a program. Hence my feeling that also this feature of OOP leaves something to be desired. And see above for the complexity which can be easily introduced using classes/objects (despite its usefulness).
So my feelings are a bit mixed with regard to „getting rid of availability“.
More real letting go is needed. That means: Whenever you don’t do something that could be done technically and usually is done, it’s a win for understandability and possibly other aspects supporting high longterm productivity.
The missing relinquishment
More letting go is needed. I’m sure of that. We really should do less of what’s possible. Not all that can be done, should be done. But what to let go of in the name of more understandability? How to make code easier to reason about or also more testable?
Candidates for letting go are features of our programming languages (and platforms) which are widely used, which seem unsuspicious of causing harm on the surface, but when looking closely lead to lots of „WTF!“.
The infamous goto fits this description perfectly. Also immutable data (aka „assignments“) and threads fit it. Not so, though, return or static functions (aka „function pointers“), I think.
But what else? What’s causing pain today through unbridled use?
Here are my main two candidates:
- overloaded data structures, and
- functional dependencies.
The problem with overloaded data structures
Martin Fowler identified the „aemic domain model“ as an anti-pattern.
„The basic symptom of an Anemic Domain Model is that at first blush it looks like the real thing. There are objects, many named after the nouns in the domain space, and these objects are connected with the rich relationships and structure that true domain models have. The catch comes when you look at the behavior, and you realize that there is hardly any behavior on these objects, making them little more than bags of getters and setters.“ (emphasis mine)
I agree, sometimes data structures, i.e. OOP classes which represent data, which „are“ data, are not used as platforms for behavior closely related to their data. This smells of primitive obsession, I’d say.
On the other hand, however, I think many OOP code bases are suffering from the opposite: overloaded data structures. To me that’s classes which start with a fuzzy responsibility; their job is neither clearly „being“ data, nor being „a service“. And from that then follows an accumulation of all sorts of functionality.
And this accumulation of functionality around a fuzzy responsibility leads to all sorts of dependencies to other classes which make the code hard to understand.
I think, we need to stop that. We need to get rid of „anything goes“ with regard to classes. DDD tried this with its tactical patterns: value object, entity, aggregate, repository, service.
For a general adoption I find this categorization too complicated or too specific. We can start much simpler by just distinguishing two kinds of classes:
- classes whose purpose it is to be data (data classes)
- classes whose purpose it is to provide functionality and which might have (hidden) data (state) (behavior classes)
Behavior classes do not publish data, they don’t have a structure with regard to data. Behavior classes just offer functionality - which of course transforms input data into output data. Data is flowing through behavior classes (be they static or non-static). And if their behavior requires access to some resource or keep a memory of data… then behavior classes can have data hidden inside them. Such data can be an accumulated value or a reference to some service object.
Behavior classes offer functions/methods, no fields, not properties (C#)/getters/setters (or only rarely).
Data classes on the other hand are about, well, data. Their very purpose is to offer fields or properties (C#)/getters/setters. They are supposed to have a data structure consisting of values aggregated under the roof of an object or nested deeply in a richly connected data model.
Data classes should not publish functionality - except very limited one concerning their structure and consistency. Data classes may hide the details of how they keep their data like the above OOP version of a queue does. Then they are abstract data types (ADT).
I love OOP languages for their ability to easily define ADTs. It’s great to be able to associate functionality with data in a class.
But therein lies a danger, too! And that’s why I think we need to have strict rules as to what should be done with classes. It should no longer be „anything goes“!
Data classes should be restricted to functionality which just guarantees consistency of the data and allows easy access to it. And all that without resorting to resource access or other „heavy framework use“.
The first reason for that restriction: Access to special 3rd party functionality should be confined to adapters. Only that way it can easily be tested and if need be replaced. Data structures which get created in many places and moved around should neither depend on such details, nor on adapters which would probably need to get injected.
And the second reason: Data structures are meant to be dependable. Lots of code is supposed to use on them. Their dependency fan-in is large by purpose. That means, data structures need to be stable. They should not change too often because that would raise the risk of ripple effects. Hence whatever increases the likelihood of data structures to change should be avoided. Rich behavior based on deeply nested functions possibly across many classes is a danger to stability.
Finally a third reason: Since data structures are so broadly used they need to be present before their clients. Better to be able to develop them quickly. The more behavior they are loaded with, though, the longer it takes to code and test them. Rich functionality on data structure is an impediment to team productivity.
In the end, though, overloaded data structures are the lesser problem, I think. The real problem to get rid of first are functional dependencies.
The problem with functional dependencies
Functional dependencies are the bane of programming since the invention of subroutines. At the same time they are one of the most natural aspects of code. They are so natural, so intuitive, so common, that hardly anybody is thinking of them. Everybody is just creating them in any number without hesitation. And why not? Aren’t they even inevitable?
This attitude is the problem! It’s exactly the same as it was with goto back until the 1970s.
Functional dependencies are a fundamental problem while at the same time being the most natural thing to do. That’s why I titled this article with „considered harmful“: to put them next to goto and the damage that was caused by its „intuitive use“.
To avoid a misunderstanding let me quickly explain what I mean by functional dependency. It’s not that I want to get rid of function calls at all. But a certain form of function calls is a dangerous weapon whose use needs regulation, I think.
Here is an example of a functional dependency:

The red code I call logic, i.e. it’s the part of the code directly responsible for creating behavior. The green code are function calls to other parts of the code with more logic.
Functional dependency means, that logic depends on other logic through function calls.
Such dependency is inevitable once it comes to third party logic, of course. Console.ReadLine or even > or if are or can be understood as function calls. But they belong to the „substrate“ an application is built on, which is provided by a third party (language vendor, framework manufacturer).
Functional dependencies thus are mixtures of „pure substrate“ use (aka logic) and calls to functions you yourself are responsible for. In the above example that’s Load and Store of some „home grown“ database object.
This should look all very normal to you. What should be wrong about calling some functions from logic? And it sure is much better than the alternative without any such functions:

Without the database logic extracted into its own functions (even its own class) it’s much harder to understand what’s going on.
True. Just logic without some function calls does not scale with regard to understanding. But even with some logic extracted into other functions not all’s well.
- Functional dependencies violate the Single Level of Abstraction (SLA) principle. It’s still hard to understand the first version of
Runwith the functional dependencies. - Functional dependencies cause logic to expand indefinitely. You know that’s true, you have seen functions with 100, 500, 1000, maybe even 5000 lines of logic mixed with function calls. They exist, because it’s so easy to push logic down into extracted functions - and then add more. It’s the mixture between logic and function calls - aka functional dependencies -, that encourages such practice. To resist is very hard, especially when facing a deadline.
- Functional dependencies add complexity when you want to get rid of them for testing. And you want to automatically test your logic, don’t you? Logic is very hard to get right. So, how can you test just the logic in the first version of the
Runmethod above? You need to substitute the real database logic with some fixed results. And on top of that you also need to get rid of the user interaction. More extraction of logic is needed. Here’s the resulting code forRunand a test substituting the functional dependencies (thanks to DIP and IoC). That’s quite some hoops to jump through just to get some functionally dependent logic tested.
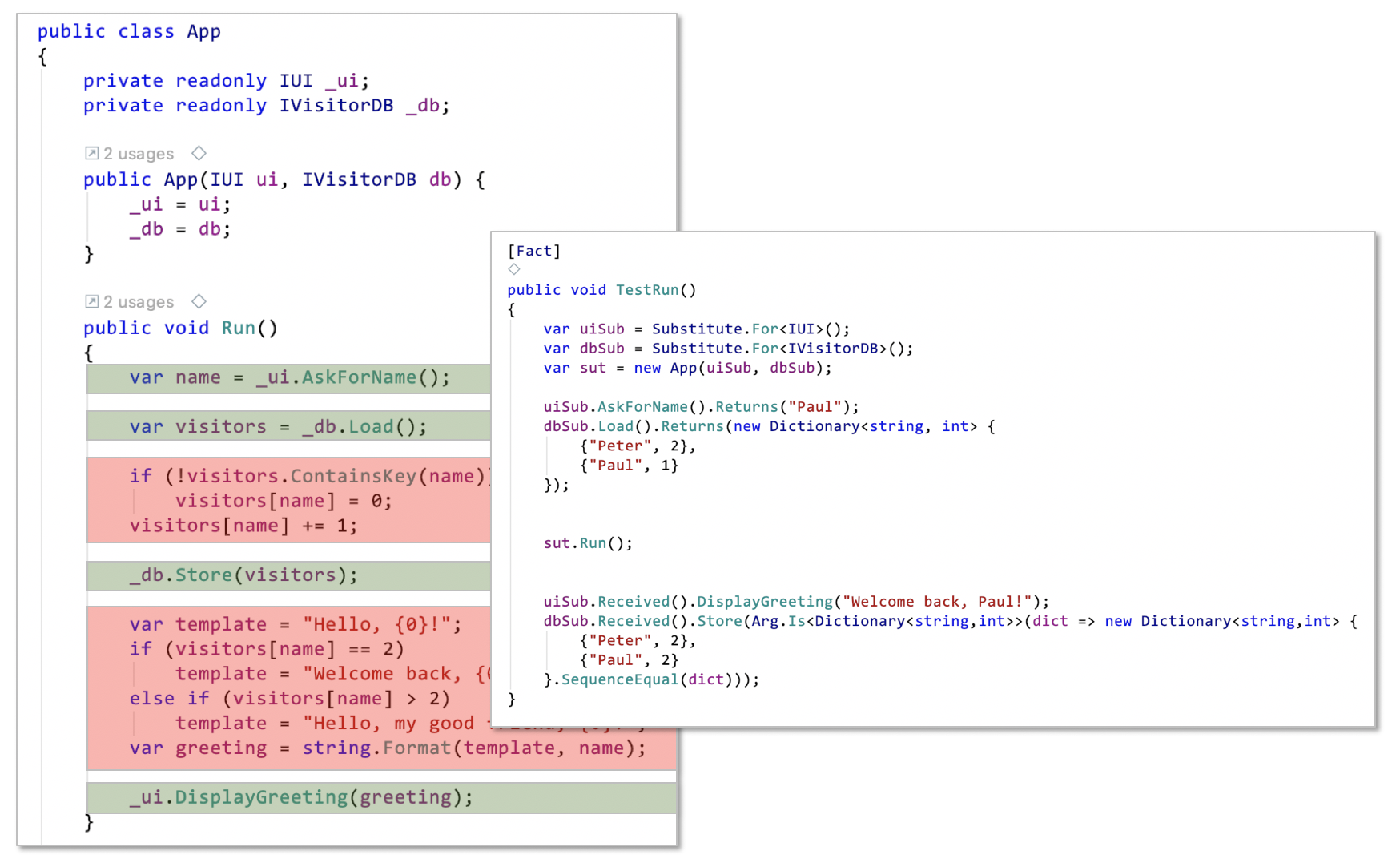
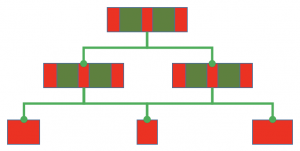
- Functional dependencies distribute the creation of behavior vertically across a code base. In order to understand how some effect is created you have to follow a trail of function calls into the depth of the function call tree. It’s hard to get an overview of what’s happening. The process of behavior creation is nowhere to be seen in its entirety on a certain level of abstraction. That’s why you’re constantly using the debugger when trying to understand code.
- Functional dependencies violate the Single Responsibility Principle (SRP)because they mix two formal responsibilities in a single function: 1) creating behavior (logic), 2) composing behavior from „services“.
In short: Functional dependencies make code hard to understand and difficult to test. They add complexity and violate wide accepted principles of clean code.
Functional dependencies to me are a core impediment to understanding, testing, and also refactoring code.
We need to strictly restrain the use of functional dependencies or even get rid of them altogether wherever possible.
It’s the same as it was with goto: The unbridled use of functional dependencies is causing a lot of harm. And the sad thing about it is it’s taken as normal or inevitable.
Functional dependencies: Just dont’t!
What’s the solution to the functional dependency problem? Don’t mix logic and calls to your own functions! (Calls to 3rd party functions are logic by definition.)
Yes, just don’t!
That means, all your functions contain either just logic (I call such functions operations) or don’t contain any logic but just calls to other functions (I call such functions integrations).
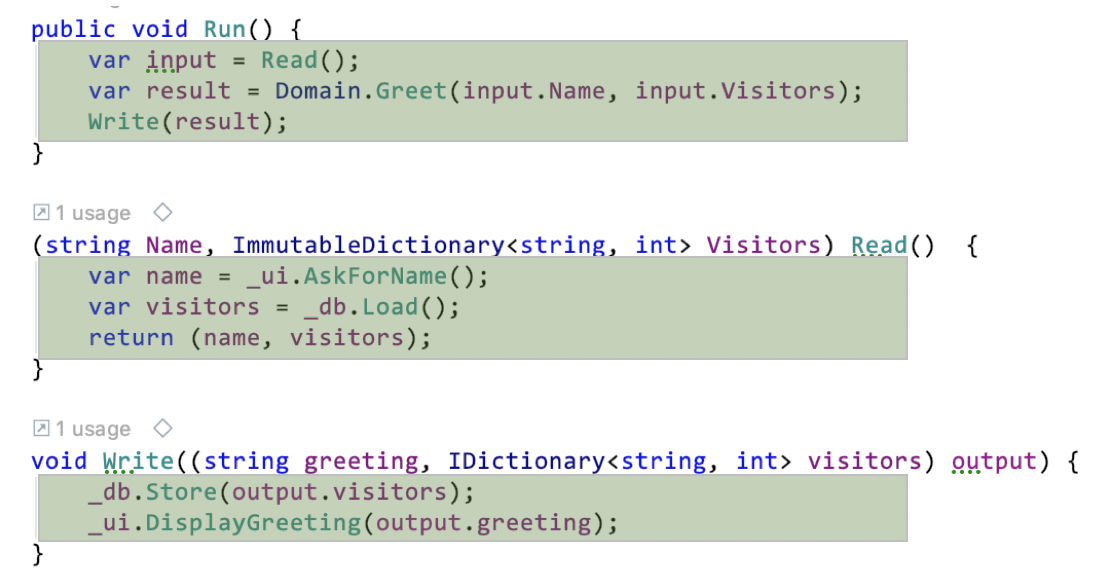
Here’s the Run function morphed into an integration:

All the difficult to get right logic has been extracted into operations (even in other classes).

Some of it had already been extract, but now it’s all of it. Why extract only part of it anyway?
The result is a Run method with beautiful characteristics:
- It’s conforming to the SLA, or at least much more than before. More about that in a minute.
- It’s conforming to the SRP. Its sole responsibility is to integrate.
- It’s very easy to understand because it shows the whole process of how its purpose is achieved at a single glance.
- No need to test it. There is no logic in it, so what can go wrong? Ok, yes, there is a slim chance of getting the integration wrong. But that’s negligible. (I’m not against testing integrations, but the need for that is much reduced. And if you test them, you should not substitute the functions called.) Hence there is no (or at least much less) need to add complexity through interfaces and mocking.
- All functions are short. This is an effect of the strict rule not to mix logic and function calls: 1) Integrations don’t grow large because it’s easy to refactor them once you feel you lose track of what’s going on. 2) Operations don’t grow because pure logic soon becomes unwieldy. Hence you feel the urge to extract some of it. Great, do that! But then the operation needs to be turned into an integration. All logic has to be extracted somehow.
- It’s easy to refactor. If I think the SLA principle could be strengthened by extracting a bit more that’s quickly done, e.g.
Summary
Even after getting rid of goto almost 50 years ago code today is suffering from unrestrained use of language features to the detriment of understandability and testability. This is severely hampering its evolvability and thus longterm team productivity.
Elements of Functional Programming and Actor Programming help. Some of OOP’s features also help. But there’s a fundamental and deeply ingrained problem remaining: functional dependencies.
Fortunately it’s not that hard to get rid of it. A simple rule can be your guide: make your functions either free of logic or full of logic. Either let them only call other functions or none at all.
I could call this Message-Oriented Programming for reasons extensively explained here in my current book (or somewhat shorter here in a series of old blog posts). It’s actually good OO practice to follow this rule. At least if you find value in the original definition of Object-Orientation by Alan Kay.
To push down logic the function dependency tree is easier than you think. You just have to try and cultivate this as an ideal. It’s like growing a new aesthetic sense. I cannot ever do without it anymore. All my code follows this rule. Like it follows the rules of Structured Programming or Actor Programming: no more gotos, no more threads.
One function depending on another won’t go away in the near future. But functional dependency can - and should! Functional dependencies are harmful to your team’s productivity. It’s that simple. Get rid of them.